關於 vLLM 與 DeepSpeed-FastGen 的比較說明
概要
- 在常見場景中,vLLM 的速度與 DeepSpeed-FastGen 相匹敵,並在處理較長輸出時超越後者。
- 由於其動態 SplitFuse 最佳化技術,DeepSpeed-FastGen 僅在長提示和短輸出的場景中優於 vLLM。此最佳化技術已在 vLLM 的路線圖上。
- vLLM 的使命是構建最快且最易於使用的開源 LLM 推理和服務引擎。它採用 Apache 2.0 許可證,由社群所有,並提供廣泛的模型和最佳化支援。
DeepSpeed 團隊最近釋出了一篇部落格文章,聲稱透過利用動態 SplitFuse 技術,吞吐量比 vLLM 提高了 2 倍。我們很高興看到開源社群的技術進步。在這篇部落格中,我們展示了動態 SplitFuse 技術具有優勢的具體場景,並指出這些情況相對有限。對於大多數工作負載,vLLM 比 DeepSpeed-FastGen 更快(或效能相當)。
效能基準測試
我們已經確定了 vLLM 和 DeepSpeed-FastGen 在效能最佳化方面的兩個主要區別。
- DeepSpeed-FastGen 採用保守/次優的記憶體分配方案,這會在輸出長度較大時浪費記憶體。
- DeepSpeed-FastGen 的動態 SplitFuse 排程僅在提示長度遠大於輸出長度時才能提供加速。
因此,當工作負載始終為長提示和短輸出時,DeepSpeed-FastGen 表現更佳。在其他場景中,vLLM 顯示出卓越的效能。
我們在 NVIDIA A100-80GB GPU 上使用 LLaMA-7B 模型,在以下場景中對這兩個系統進行了基準測試。
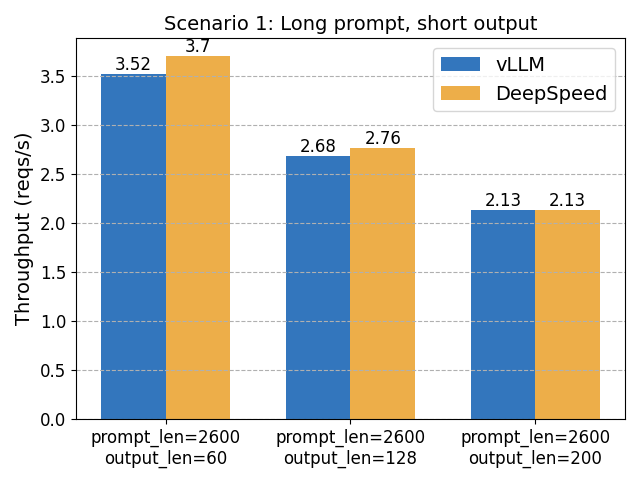
場景 1:長提示長度,短輸出
在這裡,DeepSpeed-FastGen 的動態 SplitFuse 排程有望發揮優勢。然而,我們觀察到的效能提升並沒有 2 倍那麼顯著。
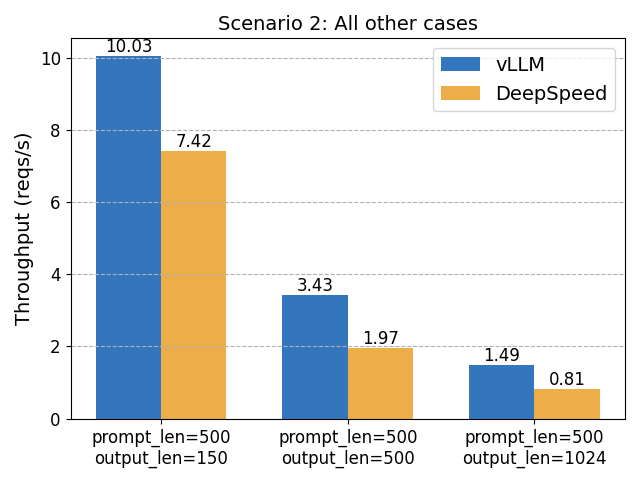
場景 2:其他情況
在這些情況下,vLLM 比 DeepSpeed-FastGen 快 1.8 倍。
vLLM 的未來:真正的社群專案
我們致力於將 vLLM 打造成最佳開源專案,融合社群的最佳模型、最佳化和硬體。vLLM 源於加州大學伯克利分校 Sky Computing Lab,我們正在以 Apache 2.0 許可證真正地以開源方式構建 vLLM。
vLLM 團隊優先考慮合作,並努力保持程式碼庫的高質量和易於貢獻。我們正在積極致力於系統性能;以及 LoRA、推測解碼和更好的量化支援等新功能。此外,我們正在與 AMD、AWS Inferentia 和 Intel Habana 等硬體供應商合作,將 LLM 帶給最廣泛的社群。
專門針對動態 SplitFuse 最佳化,我們正在積極研究適當的整合方案。如果您有任何問題和建議,請隨時在 GitHub 上聯絡我們。我們還在此處釋出了基準測試程式碼:here。
附錄:功能比較
DeepSpeed-FastGen 目前提供基本功能,僅支援三種模型型別,並且缺乏諸如停止字串和並行取樣(例如,束搜尋)等常用功能。我們確實期望 DeepSpeed-FastGen 渴望趕上,並且我們歡迎市場上的創新!
| vLLM | DeepSpeed-FastGen | |
|---|---|---|
| 執行時 | Python/PyTorch | Python/PyTorch |
| 模型實現 | HuggingFace Transformers | 自定義實現 + HF 模型轉換器 |
| 伺服器前端 | 用於演示目的的簡單 FastAPI 伺服器 | 基於 gRPC 的自定義伺服器 |
| 排程 | 連續批處理 | 動態 SplitFuse |
| 注意力核心 | PagedAttention & FlashAttention | PagedAttention & FlashAttention |
| 自定義核心(用於 LLaMA) | 注意力, RoPE, RMS, SILU | 注意力, RoPE, RMS, SILU, 嵌入 |
| KV 快取分配 | 近乎最優 | 次優/保守 |
| 支援的模型 | 16 種不同的架構 | LLaMA, Mistral, OPT |
| 取樣方法 | 隨機, 並行, 集束搜尋 | 隨機 |
| 停止標準 | 停止字串, 停止 tokens, EOS | EOS |