宣佈 vLLM 支援 Llama 3.1
今天,vLLM 團隊非常激動地與 Meta 合作宣佈支援 Llama 3.1 模型系列。Llama 3.1 帶來令人興奮的新功能,包括更長的上下文長度(高達 128K tokens)、更大的模型尺寸(高達 405B 引數)以及更先進的模型能力。vLLM 社群添加了許多增強功能,以確保更長、更大的 Llama 模型在 vLLM 上平穩執行,其中包括分塊預填充(chunked prefill)、FP8 量化和流水線並行。我們將在本博文中介紹這些新的增強功能。
簡介
vLLM 是一個快速、易於使用、開源的大型語言模型服務引擎。vLLM 支援 40 多種開源 LLM、多種多樣的硬體平臺(Nvidia GPU、AMD GPU、AWS Inferentia、Google TPU、Intel CPU、GPU、Gaudi 等)以及各種推理最佳化技術。請點選此處瞭解更多關於 vLLM 的資訊。
對於新的 Llama 3.1 系列,vLLM 可以使用完整的 128K 上下文視窗執行模型。為了支援更大的上下文視窗,vLLM 自動啟用分塊預填充。分塊預填充不僅可以控制記憶體使用量,還可以減少長時間的 prompt 處理對正在進行的請求造成的干擾。您可以透過執行以下命令或使用我們的官方 docker 映象 (vllm/vllm-openai) 來安裝 vLLM。
pip install -U vllm
對於大型 Llama 405B 模型,vLLM 支援以下幾種方法:
- FP8: vLLM 在 8xA100 或 8xH100 上原生執行官方 FP8 量化模型。
- 流水線並行: vLLM 透過將模型的不同層放置在不同的節點上,在多個節點上執行官方 BF16 版本。
- 張量並行: vLLM 也可以透過在多個節點以及節點內的多個 GPU 之間分片模型來執行。
- AMD MI300x 或 NVIDIA H200: vLLM 可以在單個 8xMI300x 或 8xH200 機器上執行該模型,其中每個 GPU 分別具有 192GB 和 141 GB 記憶體。
- CPU 解除安裝: 作為最後的手段,vLLM 可以在執行前向傳播時將部分權重解除安裝到 CPU,從而允許您在有限的 GPU 記憶體上以全精度執行大型模型。
請注意,雖然 vLLM 支援所有這些方法,但效能仍處於初步階段。vLLM 社群正在積極進行最佳化,我們歡迎大家的貢獻。例如,我們正在積極探索更多量化模型的方法,以及提高流水線並行的吞吐量。稍後在部落格中釋出的效能資料僅作為早期的參考點;我們預計效能將在未來幾周內得到顯著提升。
在所有方法中,我們推薦單節點使用 FP8,多節點使用流水線並行。讓我們更詳細地討論它們。
FP8
FP8 以 8 位表示浮點數。當前一代 GPU(H100、MI300x)透過專用張量核心為 FP8 提供原生支援。目前,vLLM 可以為 KV 快取、注意力機制和 MLP 層執行 FP8 量化模型。這減少了記憶體佔用、提高了吞吐量、降低了延遲,並且精度下降極小。
目前,vLLM 支援官方 Meta Llama 3.1 405B FP8 模型,該模型透過 FBGEMM 量化,並在 MLP 層中利用了逐通道量化。具體而言,up/gate/down 投影的每個通道都經過量化,並乘以靜態縮放因子。結合跳過第一層和最後一層的量化以及靜態上限,這種方法對模型精度的影響極小。您可以使用最新的 vLLM 在單個 8xH100 或 8xA100 上執行該模型,命令如下:
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 --tensor-parallel-size 8
在使用平均輸入長度為 1024 個 tokens 和平均輸出長度為 128 個輸出 tokens 的 FP8 量化模型服務請求時,伺服器可以維持每秒 2.82 個請求。相應的服務吞吐量分別為每秒 2884.86 個輸入 tokens 和每秒 291.53 個輸出 tokens。
我們還獨立證實了 FP8 檢查點的精度下降極小。例如,使用 lm-eval-harness 和 8-shot 以及鏈式思考 (chain-of-thought) 執行 GSM8K 基準測試,我們觀察到精確匹配得分 (exact match score) 為 95.38%(+- 0.56% 標準差),與 BF16 官方得分 96.8% 相比,下降幅度極小。
流水線並行
如果您想在不進行量化的情況下執行 Llama 3.1 405B 模型怎麼辦?您可以使用 vLLM 的流水線並行在 16xH100 或 16xA100 GPU 上實現!
流水線並行將模型分成更小的層集合,在兩個或多個節點上以流水線方式並行執行它們。與需要昂貴的 all-reduce 操作的張量並行不同,流水線並行跨層邊界劃分模型,僅需要廉價的點對點通訊。當您擁有多個節點,而這些節點不一定透過像 Infiniband 這樣的快速互連技術連線時,這尤其有用。
vLLM 支援結合流水線並行和張量並行。例如,對於跨 2 個節點的 16 個 GPU,您可以使用 2 路流水線並行和 8 路張量並行來最佳化硬體使用率。此配置將模型的一半對映到每個節點,並使用 NVLink 將每層劃分為 8 個 GPU 以進行 all-reduce 操作。您可以使用以下命令執行 Llama 3.1 405B 模型:
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct --tensor-parallel-size 8 --pipeline-parallel-size 2
如果您有像 Infiniband 這樣的快速互連技術,則可以使用 16 路張量並行。
$ vllm serve meta-llama/Meta-Llama-3.1-405B-Instruct --tensor-parallel-size 16
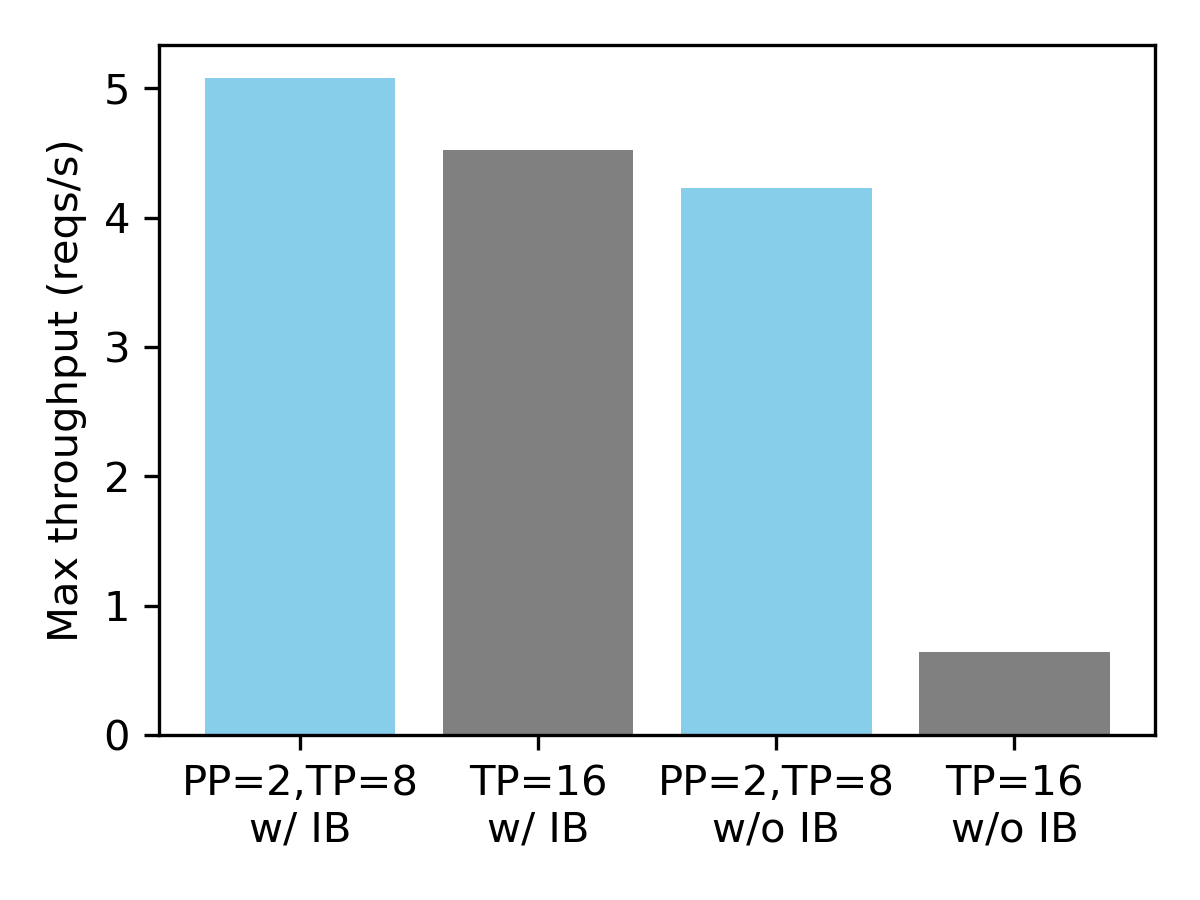
在具有合成數據集的 16xH100 GPU 上的服務吞吐量(平均輸入長度 1024,平均輸出長度 128)。
我們觀察到,當節點未透過 Infiniband 連線時,流水線並行至關重要。與 16 路張量並行相比,將 2 路流水線並行與 8 路張量並行相結合可帶來 6.6 倍的效能提升。另一方面,對於 Infiniband,兩種配置的效能相似。
要了解更多關於使用 vLLM 進行分散式推理的資訊,請參閱此文件。對於 CPU 解除安裝,請參閱此示例。
致謝
我們要感謝 Meta 提供的預釋出合作伙伴關係,讓我們能夠測試該模型。除了釋出之外,我們還要感謝以下 vLLM 貢獻者為本博文中提到的功能做出的貢獻:Neural Magic 貢獻了 FP8 量化;CentML 和 Snowflake AI Research 貢獻了流水線並行;Anyscale 貢獻了分塊預填充功能。評估執行在配備 InfiniBand 的 Lambda 的 1-Click Clusters 上,我們感謝 Lambda 提供的資源和順暢的叢集設定體驗。