vLLM v0.6.0:吞吐量提升 2.7 倍,延遲降低 5 倍
概括: vLLM 在 Llama 8B 模型上實現了 2.7 倍的吞吐量提升和 5 倍的 TPOT(每輸出令牌時間)加速,在 Llama 70B 模型上實現了 1.8 倍的吞吐量提升和 2 倍的 TPOT 降低。
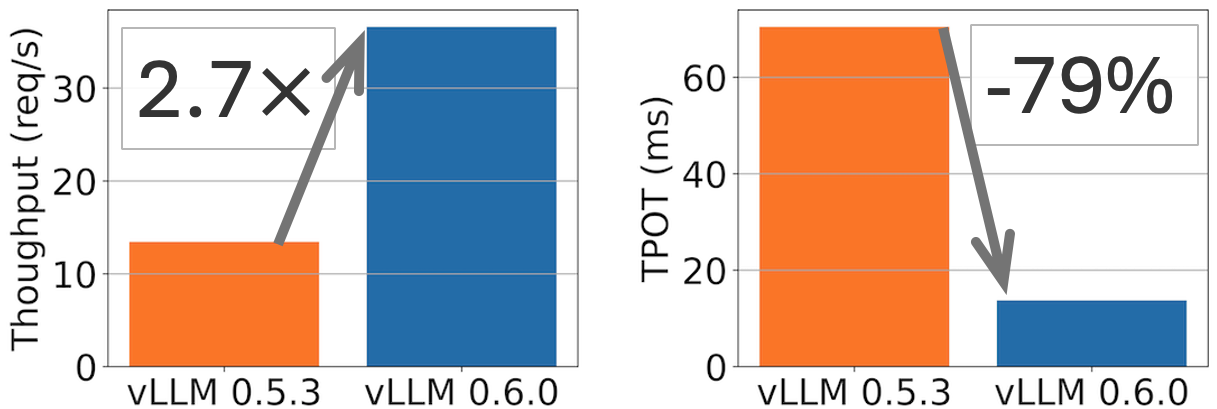
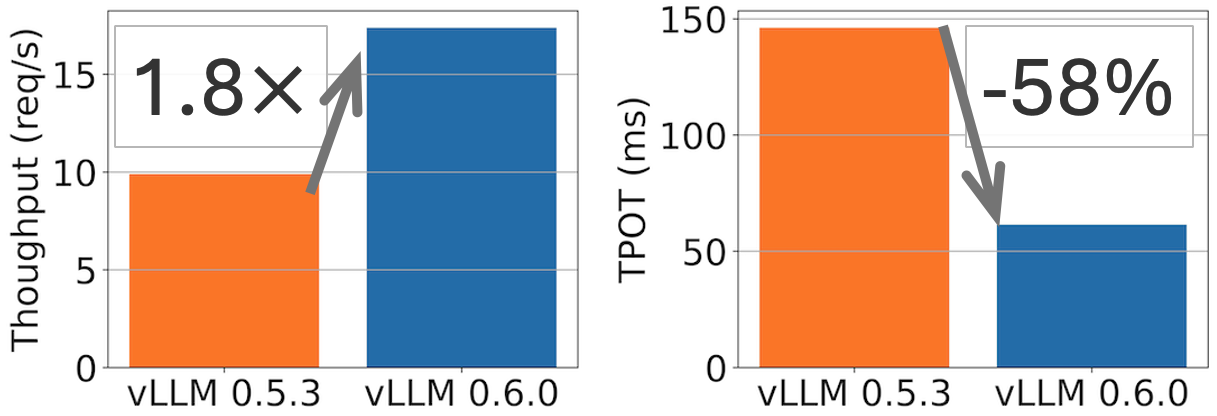
vLLM v0.5.3 和 v0.6.0 在 ShareGPT 資料集(500 個提示)上,Llama 8B 模型於 1xH100 和 70B 模型於 4xH100 的效能比較。TPOT 在 32 QPS 下測量。
一個月前,我們釋出了效能路線圖,承諾將效能作為我們的首要任務。今天,我們釋出了 vLLM v0.6.0,與 v0.5.3 相比,吞吐量提高了 1.8-2.7 倍,在保持豐富功能和出色可用性的同時,達到了最先進的效能。
我們將首先診斷之前 vLLM 中的效能瓶頸。然後,我們將描述我們在過去一個月中實施和落地的解決方案。最後,我們將展示最新 vLLM 版本 v0.6.0 和其他推理引擎的基準測試。
效能診斷
LLM 推理需要 CPU 和 GPU 之間的緊密協作。儘管主要的計算發生在 GPU 中,但 CPU 在服務和排程請求方面也發揮著重要作用。如果 CPU 排程速度不夠快,GPU 將閒置等待 CPU,這最終會導致 GPU 利用率低下並阻礙推理效能。
一年前,當 vLLM 首次釋出時,我們主要針對記憶體有限的 GPU 上的相對大型模型進行最佳化(例如 NVIDIA A100-40G 上的 Llama 13B)。隨著具有更大記憶體的更快 GPU(如 NVIDIA H100)變得更加普及,並且模型針對推理進行了更多最佳化(例如,採用 GQA 和量化等技術),推理引擎其他 CPU 部分所花費的時間成為了一個重要的瓶頸。具體來說,我們的效能分析結果表明,對於在 1 個 H100 GPU 上執行的 Llama 3 8B 模型:
- HTTP API 伺服器佔總執行時間的 33%。
- 總執行時間的 29% 花費在排程上,包括收集上一步的 LLM 結果,排程請求以執行下一步,以及準備這些請求作為 LLM 的輸入。
- 最後,只有 38% 的時間用於 LLM 的實際 GPU 執行。
我們透過以上基準測試發現了 vLLM 中的兩個主要問題:
- CPU 開銷過高。 vLLM 的 CPU 元件花費了驚人的長時間。為了使 vLLM 的程式碼易於理解和貢獻,我們將 vLLM 的大部分程式碼保留在 Python 中,並使用了許多 Python 原生資料結構(例如,Python 列表和字典)。這變成了一個顯著的開銷,導致排程和資料準備時間過長。
- 不同元件之間缺乏非同步性。 在 vLLM 中,許多元件(例如,排程器和輸出處理器)以同步方式執行,從而阻塞 GPU 執行。這主要是由於 1) 我們最初假設模型執行速度會比 CPU 部分慢得多,以及 2) 許多複雜的排程情況(例如,束搜尋排程)易於實現。然而,這個問題導致 GPU 等待 CPU,從而降低了其利用率。
總而言之,vLLM 的效能瓶頸主要由阻塞 GPU 執行的 CPU 開銷引起。在 vLLM v0.6.0 中,我們引入了一系列最佳化措施,以最大限度地減少這些開銷。
效能增強
為了確保我們能夠讓 GPU 保持繁忙,我們進行了多項增強:
將 API 伺服器和推理引擎分離到不同的程序中 (PR #6883)
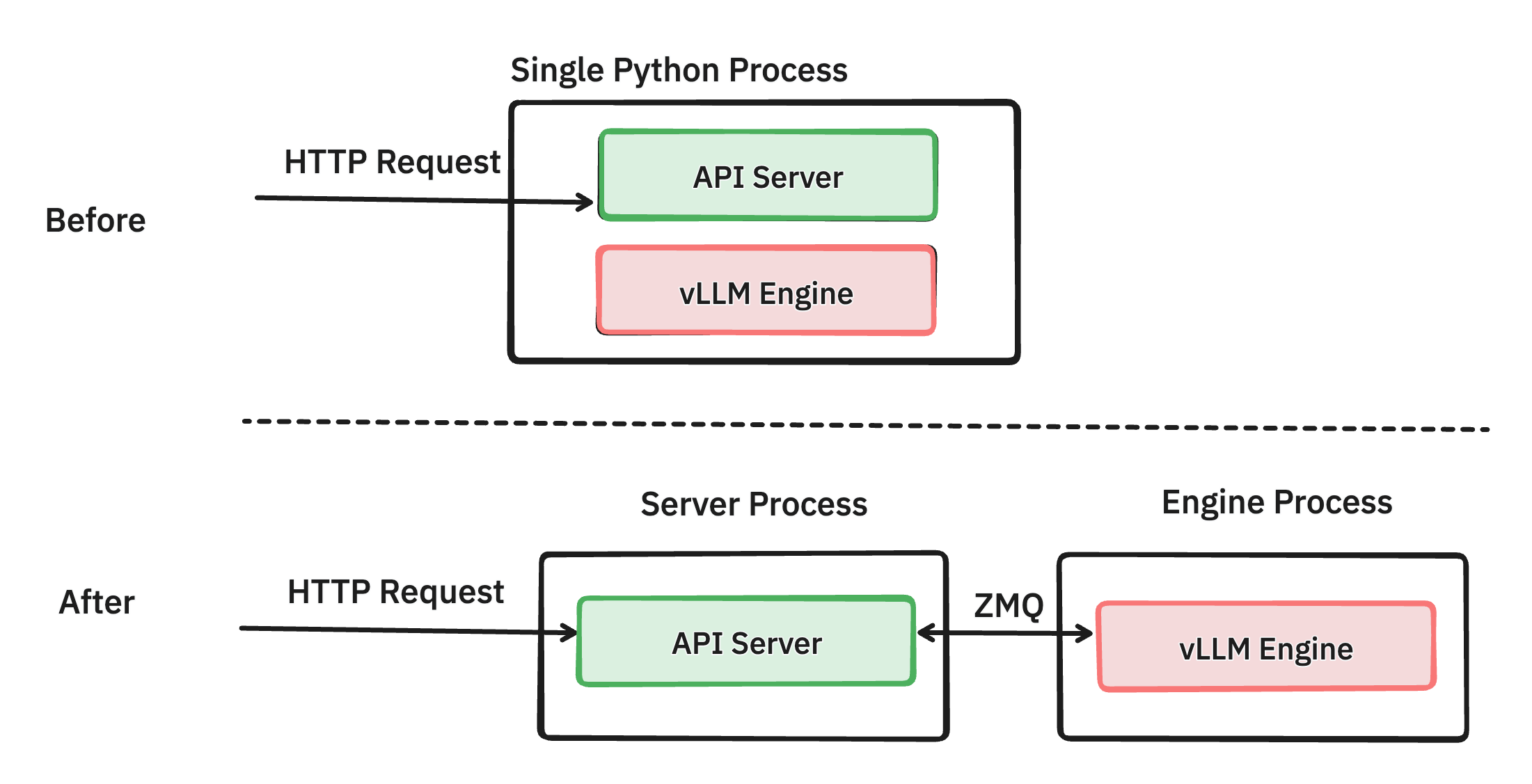
透過仔細的效能分析,我們發現管理網路請求和格式化 OpenAI 協議的響應會消耗相當多的 CPU 週期,尤其是在啟用令牌流式傳輸的高負載下。例如,Llama3 8B 在輕負載下每 13 毫秒可以生成 1 個令牌。這意味著前端需要每秒流回 76 個物件,並且隨著數百個併發請求,這種需求進一步增加。這對以前版本的 vLLM 提出了挑戰,因為 API 伺服器和推理引擎在同一程序中執行。因此,推理引擎和 API 伺服器協程必須競爭 Python GIL,導致 CPU 爭用。
我們的解決方案是將 API 伺服器(處理請求驗證、分詞和 JSON 格式化)與引擎(管理請求排程和模型推理)分離出來。我們使用低開銷的 ZMQ 將這兩個 Python 程序連線起來。透過消除 GIL 約束,這兩個元件可以更有效地執行,而不會發生 CPU 爭用,從而提高了效能。
即使在拆分這兩個程序之後,我們發現引擎中如何處理請求以及如何與 http 請求互動方面仍有很大的改進空間。我們正在積極致力於進一步提高 API 伺服器的效能 (PR #8157),目標是在不久的將來使其與離線批次推理一樣高效。
提前批次排程多個步驟 (PR #7000)
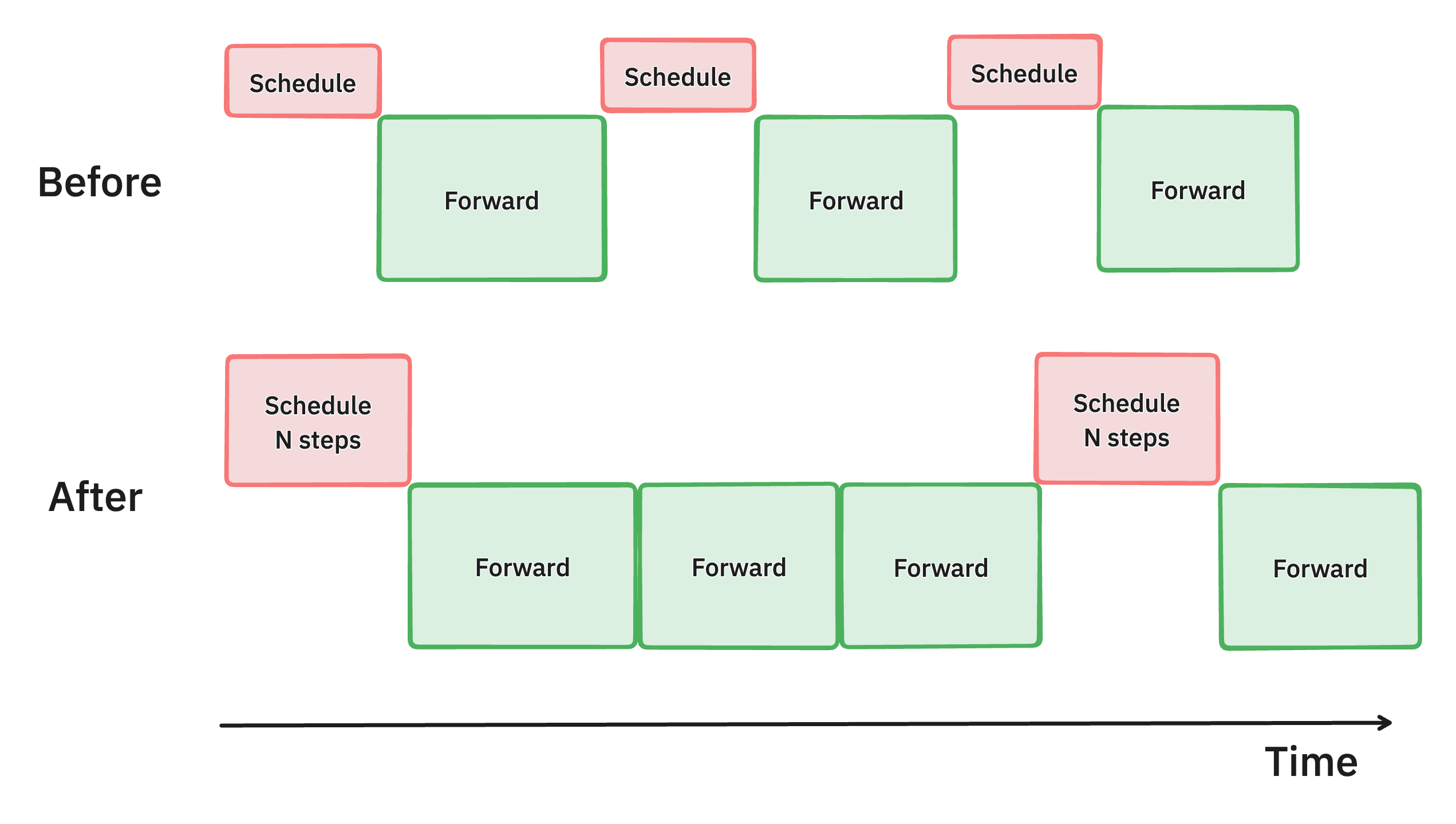
vLLM 中多步排程方法的示意圖。透過一次批次處理多個排程步驟,我們使 GPU 比以前更繁忙,從而減少延遲並提高吞吐量。
我們確定,vLLM 排程器和輸入準備的 CPU 開銷導致 GPU 利用率不足,從而導致吞吐量欠佳。為了解決這個問題,我們引入了多步排程,它執行一次排程和輸入準備,並使模型連續執行 n 步。透過確保 GPU 可以在 n 步之間繼續處理,而無需等待 CPU,這種方法將 CPU 開銷分散到多個步驟中,顯著減少了 GPU 空閒時間並提高了整體效能。
這使在 4xH100 上執行 Llama 70B 模型的吞吐量提高了 28%。
非同步輸出處理 (PR #7049, #7921, #8050)
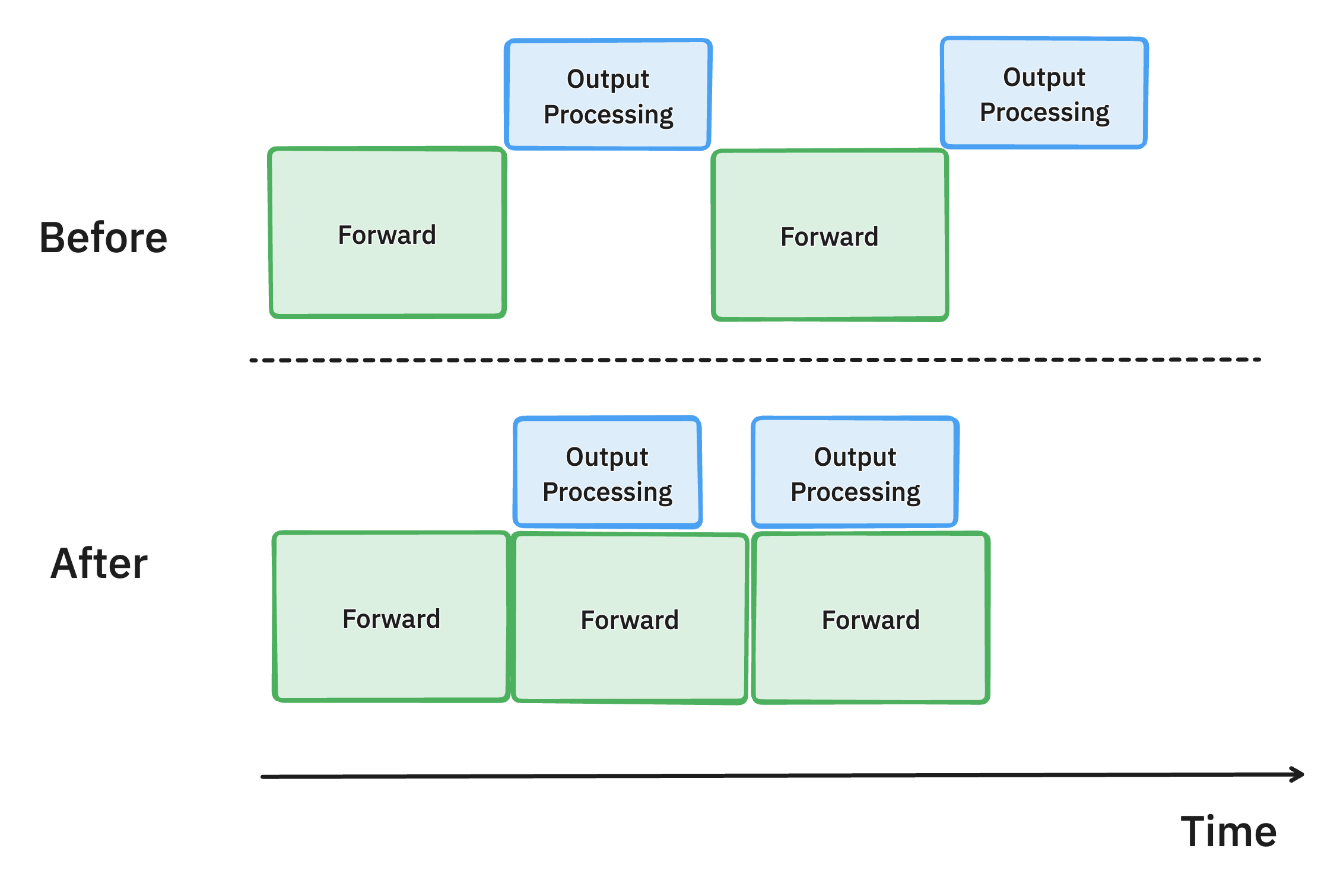
vLLM 中非同步輸出處理的示意圖。透過將輸出資料結構處理的 CPU 工作與 GPU 計算重疊,我們減少了 GPU 空閒時間並提高了吞吐量。
為了繼續努力最大限度地提高 GPU 利用率,我們還改進了 vLLM 中模型輸出的處理方式。
以前,在生成每個令牌後,vLLM 會將模型輸出從 GPU 移動到 CPU,檢查停止條件以確定請求是否已完成,然後執行下一步。這種輸出處理通常很慢,涉及對生成的令牌 ID 進行反分詞和執行字串匹配,並且開銷隨著批處理大小的增加而增加。
為了解決這種低效率問題,我們引入了非同步輸出處理,它將輸出處理與模型執行重疊。現在,vLLM 不會立即處理輸出,而是延遲它,在執行第 n+1 步時處理第 n 步輸出的處理。這種方法假設第 n 步中的任何請求都沒有滿足停止條件,從而導致每個請求額外執行一步的輕微開銷。然而,GPU 利用率的顯著提高彌補了這一成本,從而提高了整體效能。
這使在 4xH100 上執行 Llama 70B 模型的每輸出令牌時間縮短了 8.7%。
其他最佳化
為了進一步降低 CPU 開銷,我們仔細檢查了整個程式碼庫,並執行了以下最佳化:
- 隨著請求的到來和完成,Python 將不斷分配新物件並再次釋放它們。為了減輕這種開銷,我們建立了一個物件快取 (#7162) 來儲存這些物件,這顯著提高了 24% 的端到端吞吐量。
- 當從 CPU 向 GPU 傳送資料時,我們儘可能使用非阻塞操作 (#7172)。CPU 可以啟動許多複製操作,而 GPU 正在複製資料。
- vLLM 支援多種注意力後端和取樣演算法。對於具有簡單取樣請求的常用工作負載 (#7117),我們引入了一條快速程式碼路徑,跳過了複雜的步驟。
在過去的一個月裡,vLLM 社群為這些最佳化付出了許多努力。我們將繼續最佳化程式碼庫以提高效率。
效能基準測試
透過以上努力,我們很高興分享 vLLM 的效能與上個月的 vLLM 相比有了很大提高。根據我們的效能基準測試,它達到了最先進的效能。
服務引擎。 我們將 vLLM v0.6.0 與 TensorRT-LLM r24.07、SGLang v0.3.0 和 lmdeploy v0.6.0a0 進行了基準測試。對於其他基準測試,我們使用它們的預設設定。對於 vLLM,我們透過設定 --num-scheduler-steps 10 啟用了多步排程。我們正在積極努力使其成為預設設定。
資料集。 我們使用以下三個資料集對不同的服務引擎進行基準測試:
- ShareGPT:從 ShareGPT 資料集中隨機抽取的 500 個提示,具有固定的隨機種子。
- 平均輸入令牌數:202,平均輸出令牌數:179
- 預填充密集型資料集:從 sonnet 資料集中合成生成的 500 個提示,平均約有 462 個輸入令牌和 16 個輸出令牌。
- 解碼密集型資料集:從 sonnet 資料集中合成生成的 500 個提示,平均約有相同數量的 462 個輸入令牌和 256 個輸出令牌。
模型。 我們在兩個模型上進行了基準測試:Llama 3 8B 和 70B。我們沒有使用最新的 Llama 3.1 模型,因為帶有 TensorRT LLM 後端 v0.11 的 TensorRT-LLM r24.07 不支援它 (問題連結)。
硬體。 我們使用 A100 和 H100 進行基準測試。它們是用於推理的兩個主要高階 GPU。
指標。 我們評估以下指標:
- 首個令牌時間 (TTFT,以毫秒為單位測量)。我們在圖中顯示了均值和均值標準誤差。
- 每輸出令牌時間 (TPOT,以毫秒為單位測量)。我們在圖中顯示了均值和均值標準誤差。
- 吞吐量 (以每秒請求數衡量)。
- 吞吐量是在 QPS inf (意味著所有請求一次性到達) 下測量的。
基準測試結果
在 ShareGPT 和解碼密集型資料集中,當服務 Llama-3 模型時,vLLM 在 H100 上實現了最高的吞吐量。
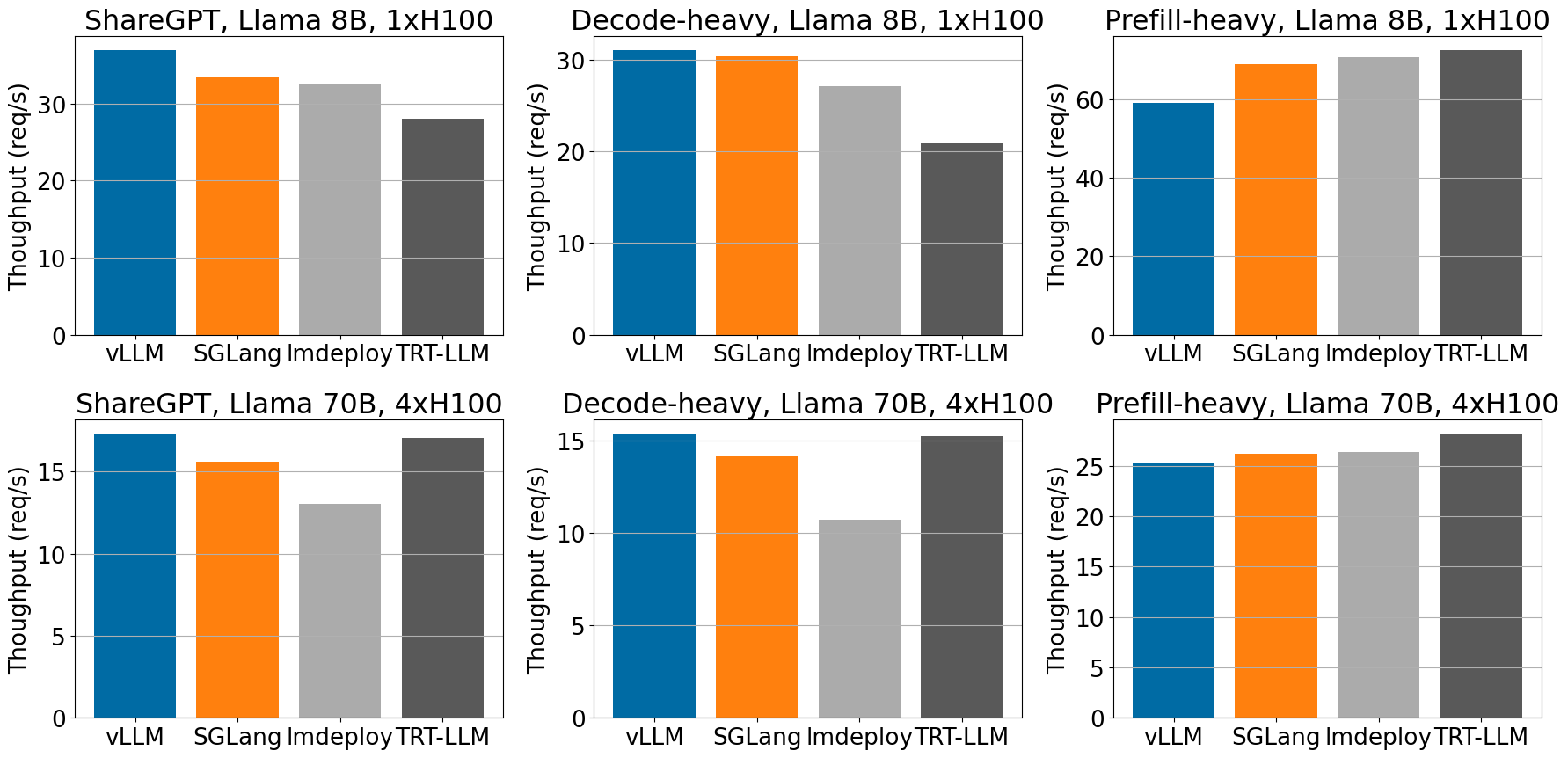
在不同的工作負載中,對於 H100 上的 Llama 8B 和 70B 模型,與其他框架相比,vLLM 實現了高吞吐量。
對於其餘的效能基準測試,以及捕獲的首個令牌時間 (TTFT) 和每輸出令牌時間 (TPOT) 的詳細指標,請參閱附錄以獲取更多資料和分析。您可以關注 此 github issue 來重現我們的基準測試。
當前最佳化的侷限性。 儘管我們當前的最佳化措施帶來了顯著的吞吐量提升,但我們當前的最佳化措施也存在效能權衡,特別是來自多步排程:
- 不穩定的令牌間延遲: 在我們當前的多步排程實現中,我們還在批處理中返回多個步驟的輸出令牌。從終端使用者的角度來看,他們將收到批量回復的令牌。我們正在透過將中間令牌流式傳輸回引擎來解決這個問題。
- 在低請求速率下 TTFT 較高: 新請求只能在當前多步執行完成後開始執行。因此,較高的
--num-scheduler-steps將導致在低請求速率下 TTFT 較高。我們的實驗側重於高 QPS 下的排隊延遲,因此這種影響在附錄的結果中並不顯著。
結論與未來工作
在這篇文章中,我們討論了 vLLM 中的效能增強,這些增強帶來了 1.8-2.7 倍的吞吐量提升,並與其他推理引擎相媲美。我們仍然致力於穩步提高效能,同時不斷擴充套件我們的模型覆蓋範圍、硬體支援和多樣化功能。對於本文討論的功能,我們將繼續加強它們以實現生產就緒。
重要的是,我們還將專注於改進 vLLM 的核心,以降低複雜性,從而降低貢獻的門檻,並釋放更多效能增強。
參與其中
如果您還沒有這樣做,我們強烈建議您更新 vLLM 版本(請參閱此處的說明)並親自試用!我們一直很樂意瞭解更多關於您的用例以及我們如何為您改進 vLLM 的資訊。可以透過 vllm-questions@lists.berkeley.edu 聯絡 vLLM 團隊。vLLM 也是一個社群專案,如果您有興趣參與和貢獻,我們歡迎您檢視我們的路線圖並檢視適合新手的問題來解決。透過在 X 上關注我們,隨時關注更多更新。
如果您在灣區,您可以在以下活動中與 vLLM 團隊會面:vLLM 第六次與 NVIDIA 的聚會 (09/09)、PyTorch 大會 (09/19)、CUDA MODE IRL 聚會 (09/21) 和 Ray Summit 上的首個 vLLM 專題 (10/01-02)。
無論您身在何處,都不要忘記註冊參加線上雙週 vLLM 辦公時間!每兩週都會討論新的主題。下一次將深入探討效能增強。
致謝
這篇博文由伯克利的 vLLM 團隊起草。效能提升來自 vLLM 社群的集體努力:來自 Neural Magic 的 Robert Shaw 和來自 IBM 的 Nick Hill、Joe Runde 領導了 API 伺服器重構,來自 UCSD 的 Will Lin 和來自 Anyscale 的 Antoni Baum、Cody Yu 領導了多步排程工作,來自 Databricks 的 Megha Agarwal 和來自 Neural Magic 的 Alexander Matveev 領導了非同步輸出處理,以及來自 vLLM 社群的許多貢獻者貢獻了各種最佳化。所有這些努力使我們齊心協力,獲得了巨大的效能提升。
附錄
我們在本節中包含詳細的實驗結果。
Llama 3 8B 於 1xA100
在 Llama 3 8B 上,vLLM 在 ShareGPT 和解碼密集型資料集上實現了與 TensorRT-LLM 和 SGLang 相當的 TTFT 和 TPOT。與其他引擎相比,LMDeploy 的 TPOT 較低,但 TTFT 總體上較高。在吞吐量方面,TensorRT-LLM 在所有引擎中吞吐量最高,而 vLLM 在 ShareGPT 和解碼密集型資料集上吞吐量排名第二。
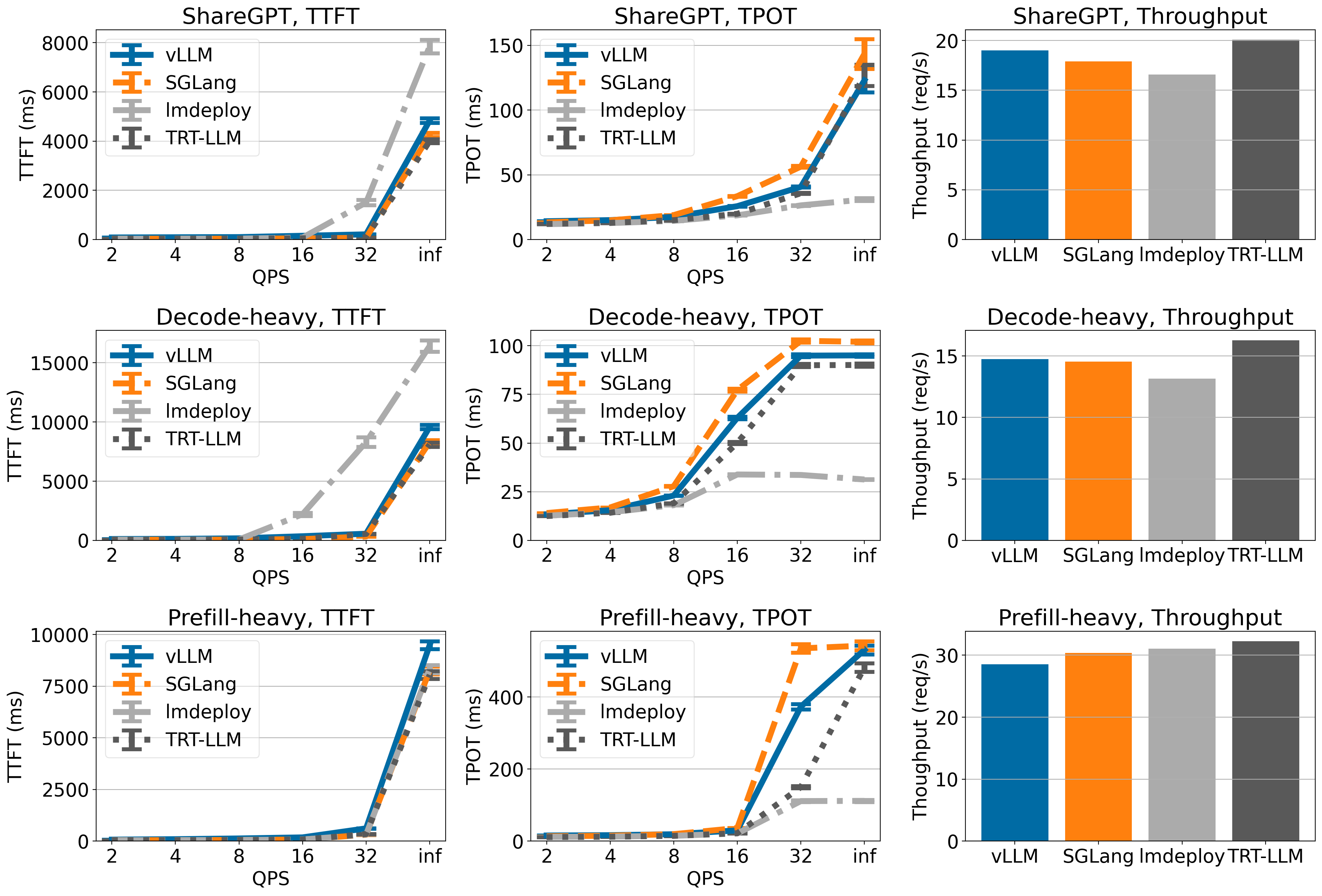
Llama 3 70B 於 4xA100
在 Llama 3 70B 上,vLLM、SGLang 和 TensorRT-LLM 具有相似的 TTFT 和 TPOT(LMDeploy 的 TPOT 較低,但 TTFT 較高)。在吞吐量方面,vLLM 在 ShareGPT 資料集上實現了最高的吞吐量,並且在其他資料集上與其他引擎相比具有相當的吞吐量。

Llama 3 8B 於 1xH100
vLLM 在 ShareGPT 和解碼密集型資料集上實現了最先進的吞吐量,儘管在預填充密集型資料集上吞吐量較低。

Llama 3 70B 於 4xH100
vLLM 在 ShareGPT 和解碼密集型資料集上具有最高的吞吐量(儘管吞吐量僅略高於 TensorRT-LLM),但在預填充密集型資料集上,vLLM 的吞吐量較低。
