投機解碼如何將 vLLM 效能提升高達 2.8 倍
vLLM 中的投機解碼是一項強大的技術,它透過協同利用小型和大型模型來加速令牌生成。在本部落格中,我們將深入探討 vLLM 中的投機解碼,其工作原理以及它帶來的效能提升。
本內容基於我們雙週 vLLM 辦公時間的一次會議,我們在會上討論最佳化 vLLM 效能的技術和更新。您可以在此處檢視會議幻燈片。如果您喜歡觀看影片,可以在 YouTube 上觀看完整錄影。我們很期待您參加未來的會議 - 請註冊!
投機解碼簡介
投機解碼 (Leviathan 等人,2023) 是一項在大型語言模型 (LLM) 中減少令牌生成延遲的關鍵技術。這種方法利用較小的模型來處理較簡單的令牌預測,同時利用較大的模型來驗證或調整這些預測。透過這樣做,投機解碼在不犧牲準確性的前提下加速了生成過程,使其成為最佳化 LLM 效能的一種無損但高效的方法。
為什麼投機解碼可以減少延遲? 傳統上,LLM 以自迴歸方式一次生成一個令牌。例如,給定一個提示,模型生成三個令牌 T1、T2、T3,每個令牌都需要單獨的前向傳遞。投機解碼透過允許在一個前向傳遞中提出和驗證多個令牌來改變這一過程。
以下是該過程的工作原理
- 草稿模型:一個較小、更高效的模型逐個提出令牌。
- 目標模型驗證:較大的模型在單個前向傳遞中驗證這些令牌。它確認正確的令牌並糾正任何不正確的令牌。
- 一次傳遞中處理多個令牌:這種方法不是每次傳遞生成一個令牌,而是同時處理多個令牌,從而減少延遲。
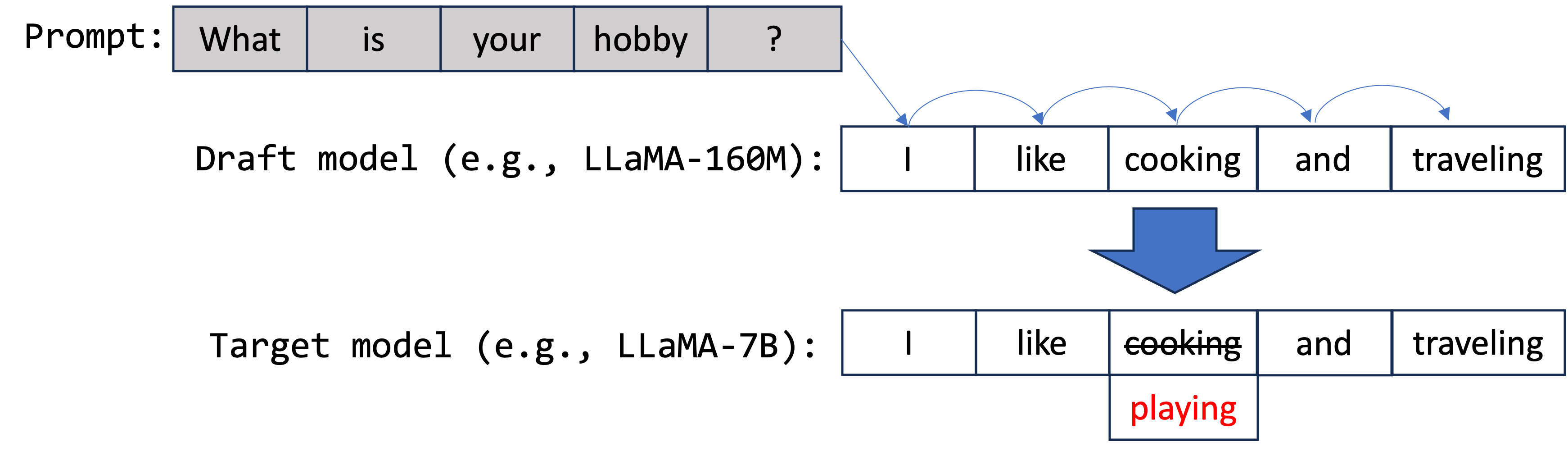
如上圖所示,草稿模型提出了五個令牌:["我", "喜歡", "烹飪", "和", "旅行"]。然後將這些令牌轉發到目標模型以進行並行驗證。在本例中,第三個令牌“烹飪”(應為“玩耍”)的提議不準確。因此,在此步驟中僅生成前三個令牌 ["我", "喜歡", "玩耍"]。
透過使用這種方法,投機解碼加快了令牌生成速度,使其成為小型和大型語言模型部署的有效方法。
vLLM 中投機解碼的工作原理
在 vLLM 中,投機解碼與系統的連續批處理架構整合,在該架構中,不同的請求在單個批次中一起處理,從而實現更高的吞吐量。vLLM 使用兩個關鍵元件來實現這一點
- 草稿執行器:此執行器負責執行較小的模型以提出候選令牌。
- 目標執行器:目標執行器透過執行較大的模型來驗證令牌。
vLLM 的系統經過最佳化,可以高效地處理此過程,從而使投機解碼與連續批處理無縫協作,從而提高整體系統效能。
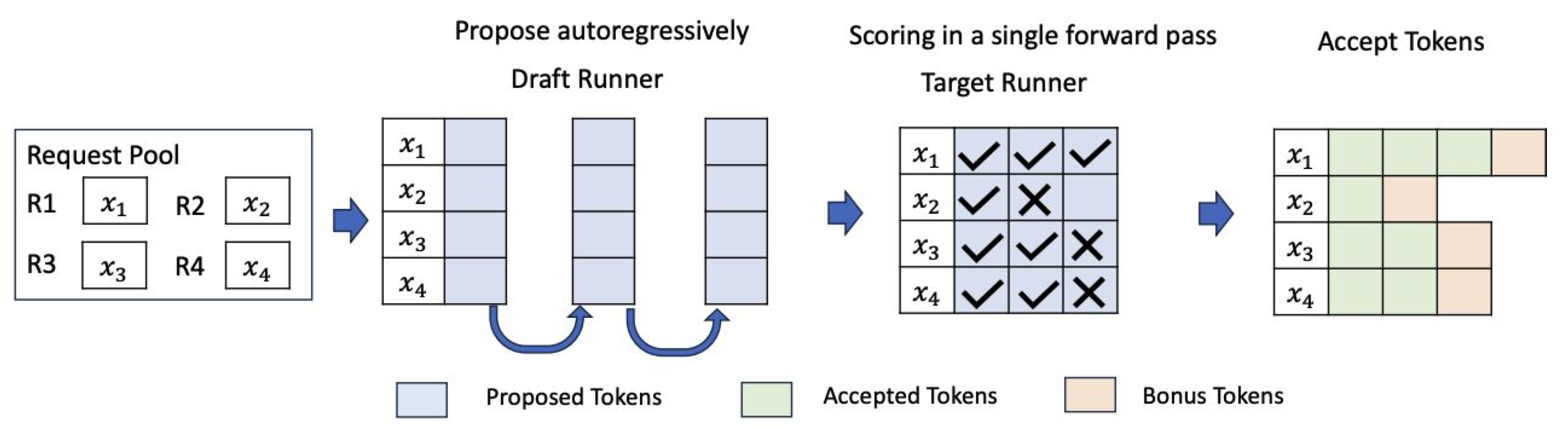
圖表說明了草稿執行器和目標執行器如何在 vLLM 批處理系統中互動。
為了在 vLLM 中實現投機解碼,必須修改兩個關鍵元件
- 排程器:調整了排程器以處理單個前向傳遞中的多個令牌槽,從而實現同時生成和驗證多個令牌。
- 記憶體管理器:記憶體管理器現在處理草稿模型和目標模型的 KV 快取,確保在投機解碼期間的平穩處理。
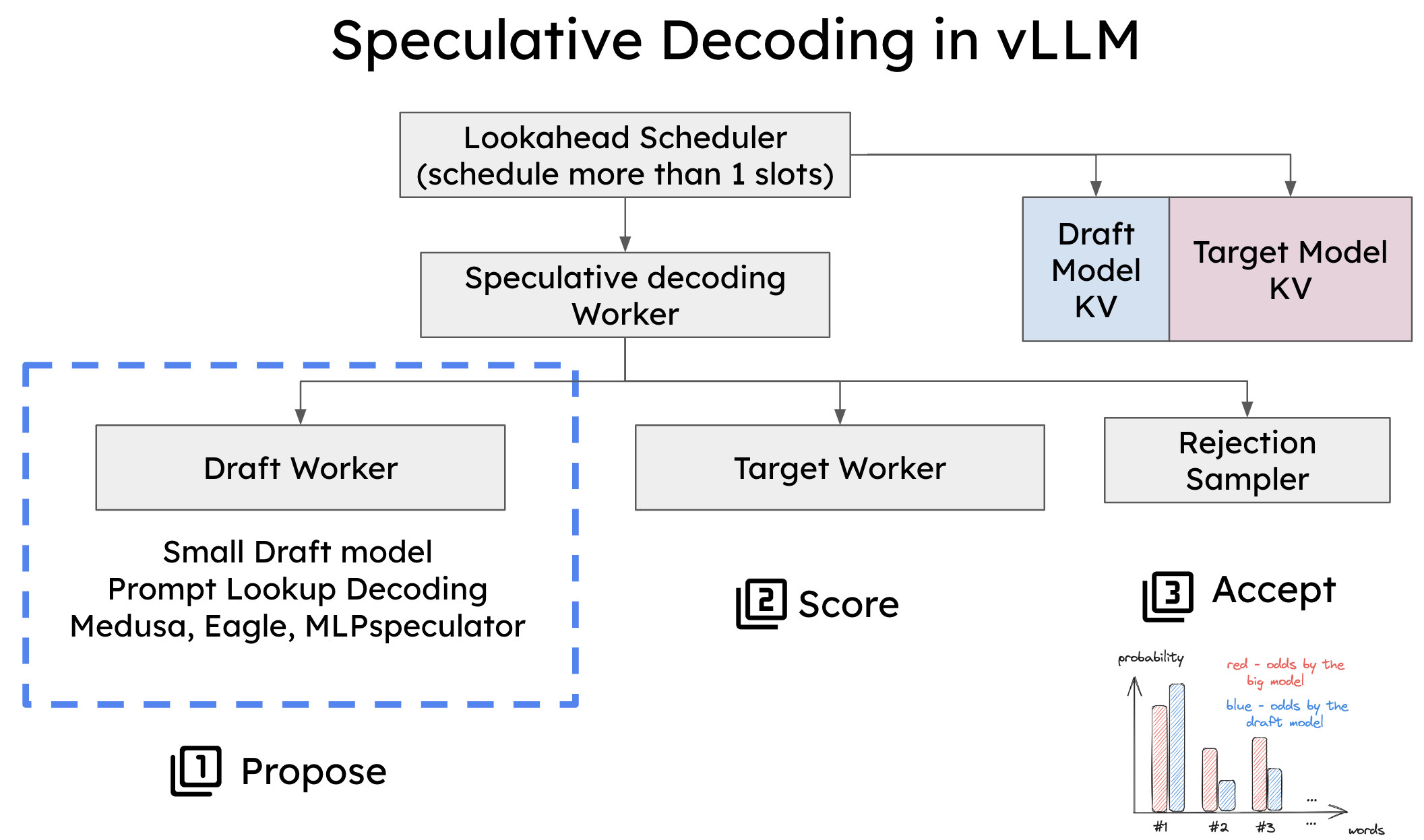
vLLM 中投機解碼的系統架構。
vLLM 中支援的投機解碼型別
vLLM 支援三種類型的投機解碼,每種型別都針對不同的工作負載和效能需求量身定製
基於草稿模型的投機解碼
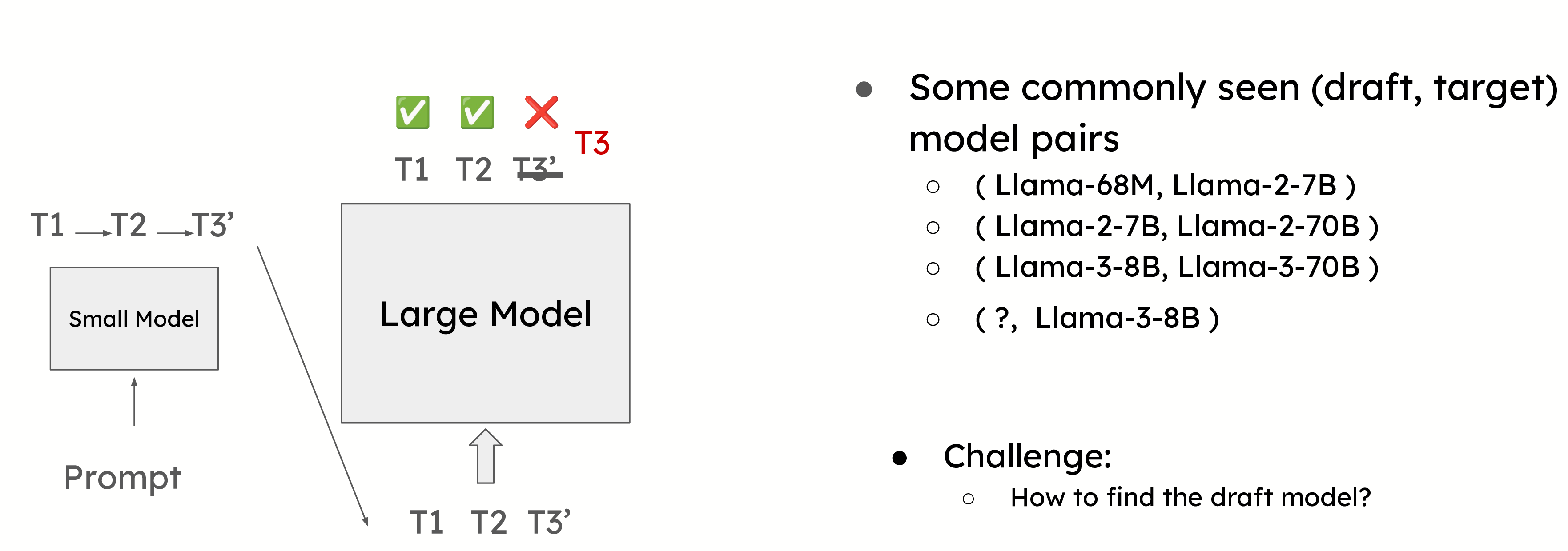
這是最常用的投機解碼形式,其中較小的模型預測下一個令牌,而較大的模型驗證它們。一個常見的例子是使用 Llama 68M 模型來預測 Llama 2 70B 模型的令牌。這種方法需要仔細選擇草稿模型,以平衡準確性和開銷。
選擇正確的草稿模型對於最大化投機解碼的效率至關重要。草稿模型需要足夠小,以避免產生顯著的開銷,但仍要足夠準確,以提供有意義的效能提升。
然而,選擇合適的草稿模型可能具有挑戰性。例如,在像 Llama 3 這樣的模型中,由於詞彙量大小的差異,很難找到合適的草稿模型。投機解碼要求草稿模型和目標模型共享相同的詞彙表,在某些情況下,這可能會限制投機解碼的使用。因此,在以下部分中,我們將介紹幾種無草稿模型的投機解碼方法。
提示查詢解碼
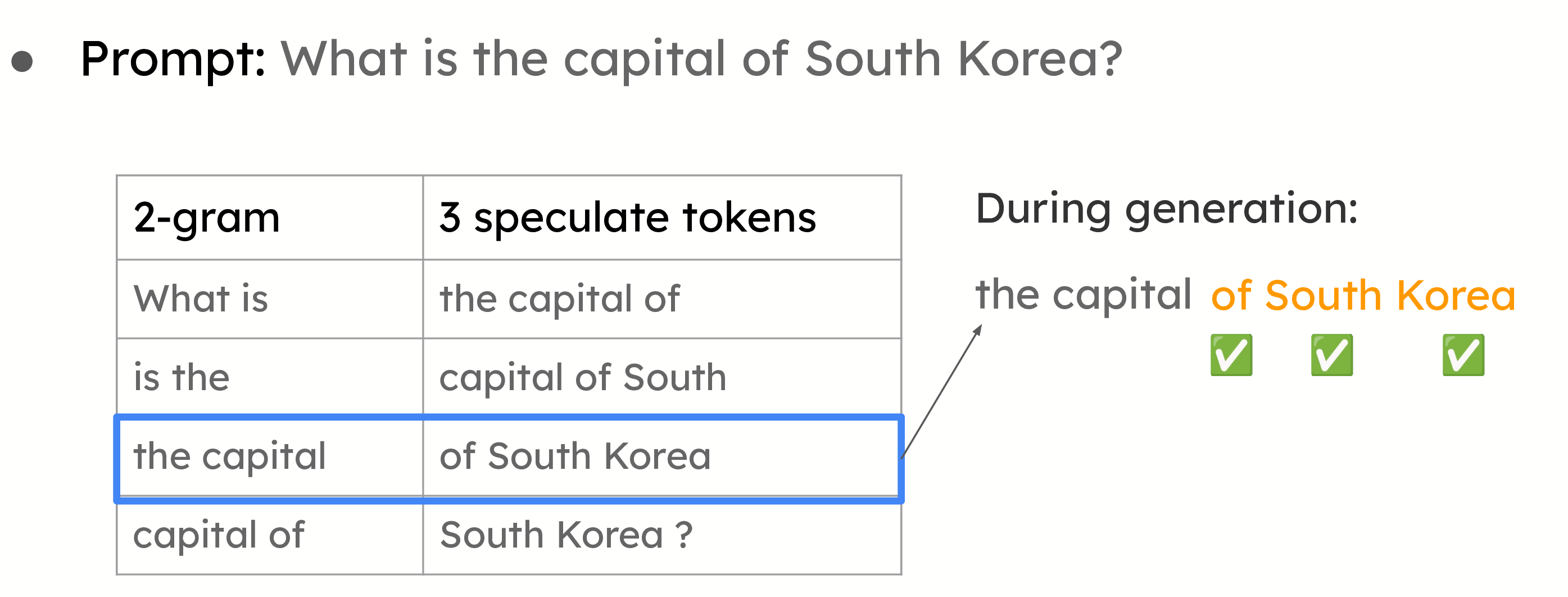
提示查詢解碼的示例。給定提示,我們將構建所有 2-gram 作為查詢鍵。這些值是查詢鍵後面的三個令牌。在生成過程中,我們將檢查當前的 2-gram 是否與任何鍵匹配。如果匹配,我們將使用該值提議以下令牌。
也稱為 n-gram 匹配,這種方法對於摘要和問答等用例非常有效,在這些用例中,提示和答案之間存在顯著的重疊。系統不是使用小型模型來提議令牌,而是基於提示中已有的資訊進行推測。當大型模型在其答案中重複提示的部分內容時,這種方法尤其有效。
Medusa/Eagle/MLPSpeculator
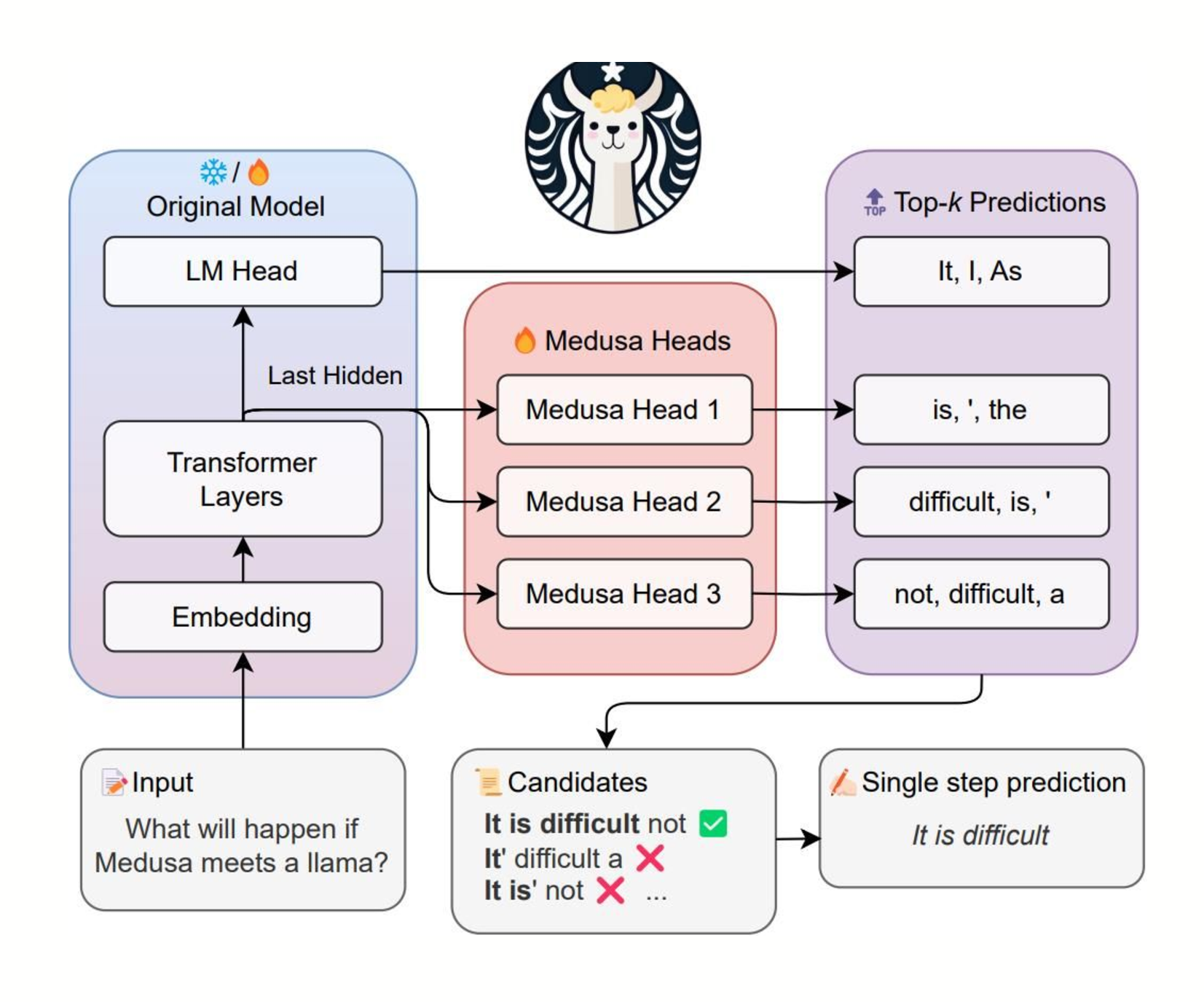
圖片來自 https://github.com/FasterDecoding/Medusa。在該示例中,使用三個頭來為以下三個位置提議令牌。頭 1 為第一個位置提議 ["is", "\'", "the"]。頭 2 為第二個位置提議 ["difficult", "is", "\'"]。頭 3 為第三個位置提議 ["not", "difficult", "a"]。所有頭都將最後一個 Transformer 塊的輸出作為輸入。
在這種方法中,將額外的層(或頭)新增到大型模型本身,使其能夠在單個前向傳遞中預測多個令牌。這減少了對單獨的草稿模型的需求,而是利用大型模型自身的能力進行並行令牌生成。儘管尚處於初步階段,但隨著更最佳化的核心的開發,這種方法顯示出提高效率的潛力。
投機解碼效能洞察:加速和權衡
投機解碼在低 QPS(每秒查詢數)環境中提供了顯著的效能優勢。例如,在 ShareGPT 資料集上的測試中,vLLM 在使用基於草稿模型的投機解碼時,令牌生成速度提高了 1.5 倍。同樣,當應用於摘要資料集(如 CNN/DailyMail)時,提示查詢解碼也顯示出高達 2.8 倍的加速。
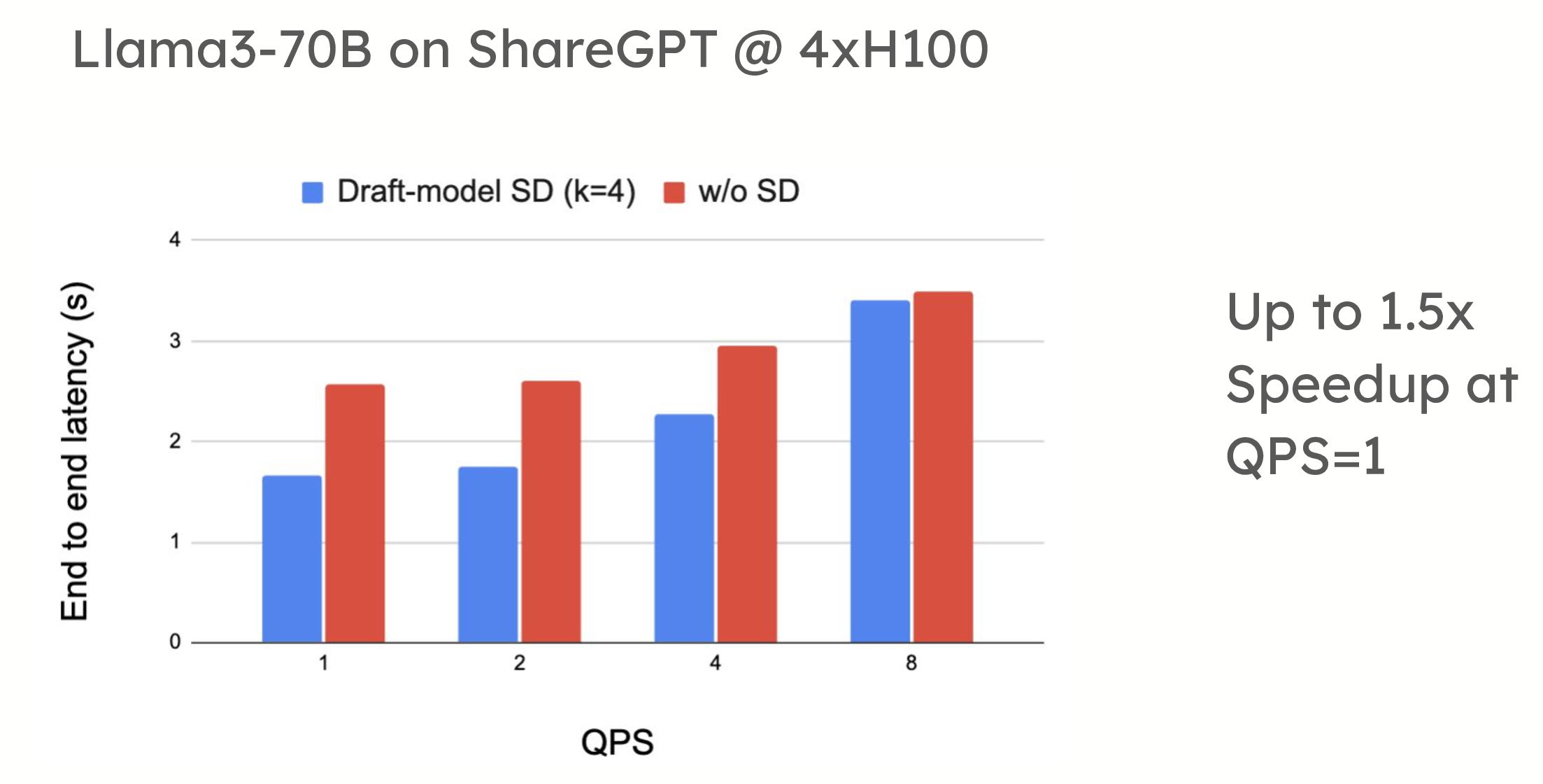
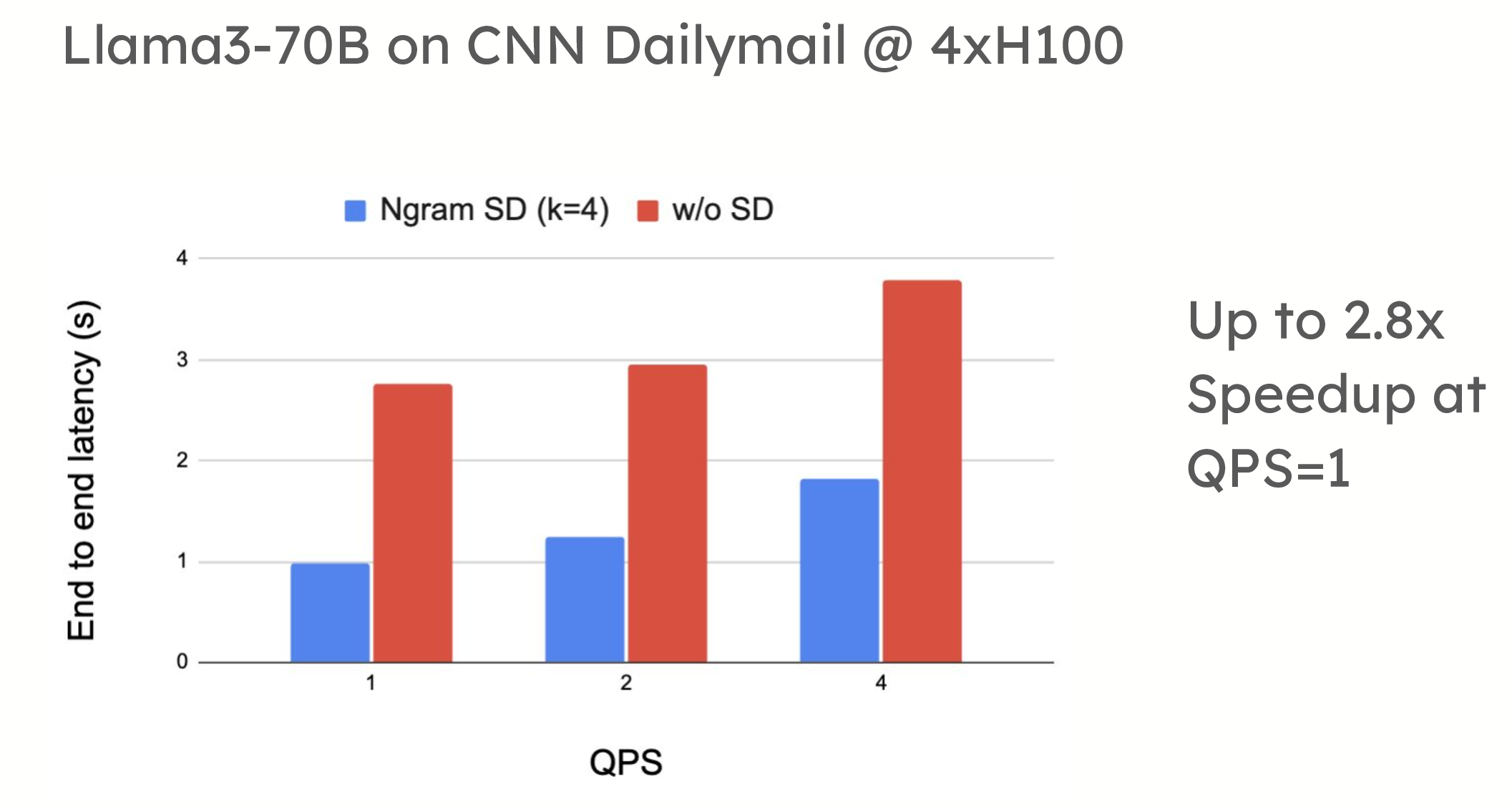
效能比較顯示,在使用草稿模型 (turboderp/Qwama-0.5B-Instruct) 的 4xH100 上,QPS=1 時,Llama3-70B 在 ShareGPT 上使用投機解碼可實現高達 1.5 倍的加速;在使用 n-gram 的 4xH100 上,QPS=1 時,Llama3-70B 在 CNN Dailymail 上使用投機解碼可實現高達 2.8 倍的加速。
然而,在高 QPS 環境中,投機解碼可能會引入效能權衡。當系統已經受到計算限制時,提議和驗證令牌所需的額外計算有時會減慢系統速度,正如每秒請求數增加時所看到的那樣。在這種情況下,投機解碼的開銷可能會超過其優勢,從而導致效能下降。
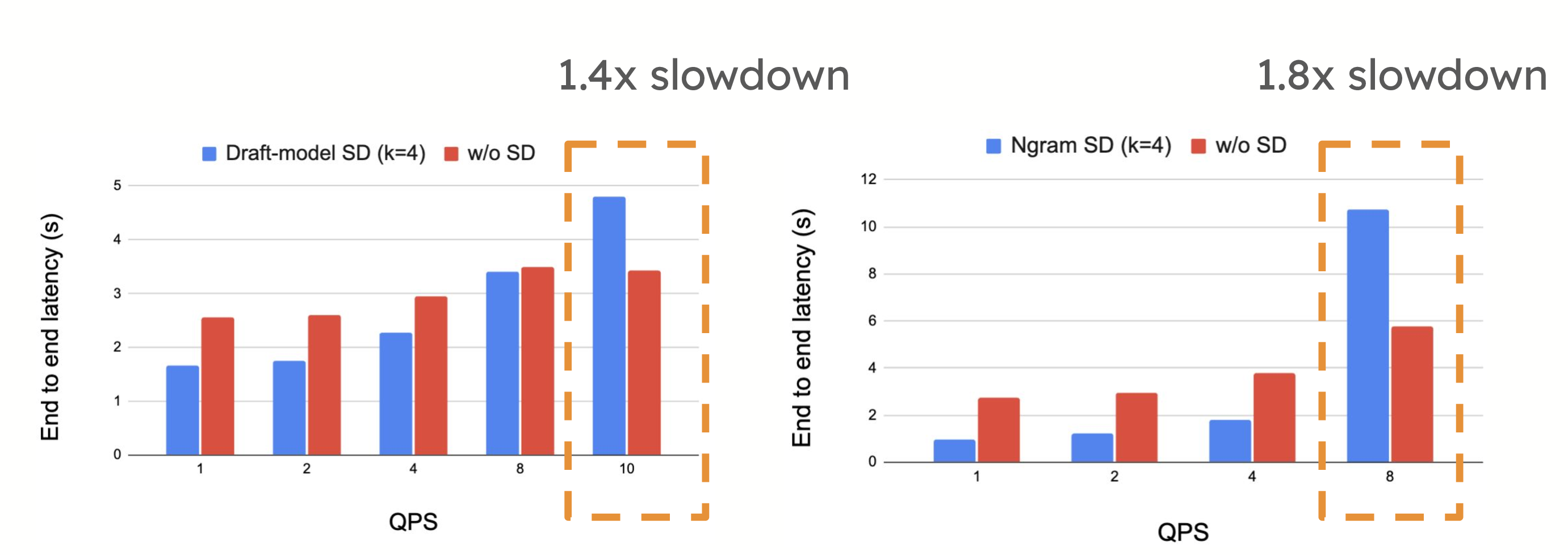
在高 QPS 下,我們看到 Llama3-70B 在 ShareGPT 上使用 4xH100 時速度減慢 1.4 倍,Llama3-70B 在 CNN Dailymail 上使用 4xH100 時速度減慢 1.8 倍
路線圖:用於提升效能的動態調整
為了克服投機解碼在高 QPS 設定中的侷限性,vLLM 正在努力實現動態投機解碼。請隨時檢視論文以獲取更多詳細資訊。這也是 vllm 中活躍的研究方向之一!此功能將允許 vLLM 根據系統負載和草稿模型的準確性來調整投機令牌的數量。在較高層面,當系統負載較高時,動態投機解碼會縮短提議的長度。然而,如下圖所示,當平均令牌接受率較高時,這種減少不太明顯。
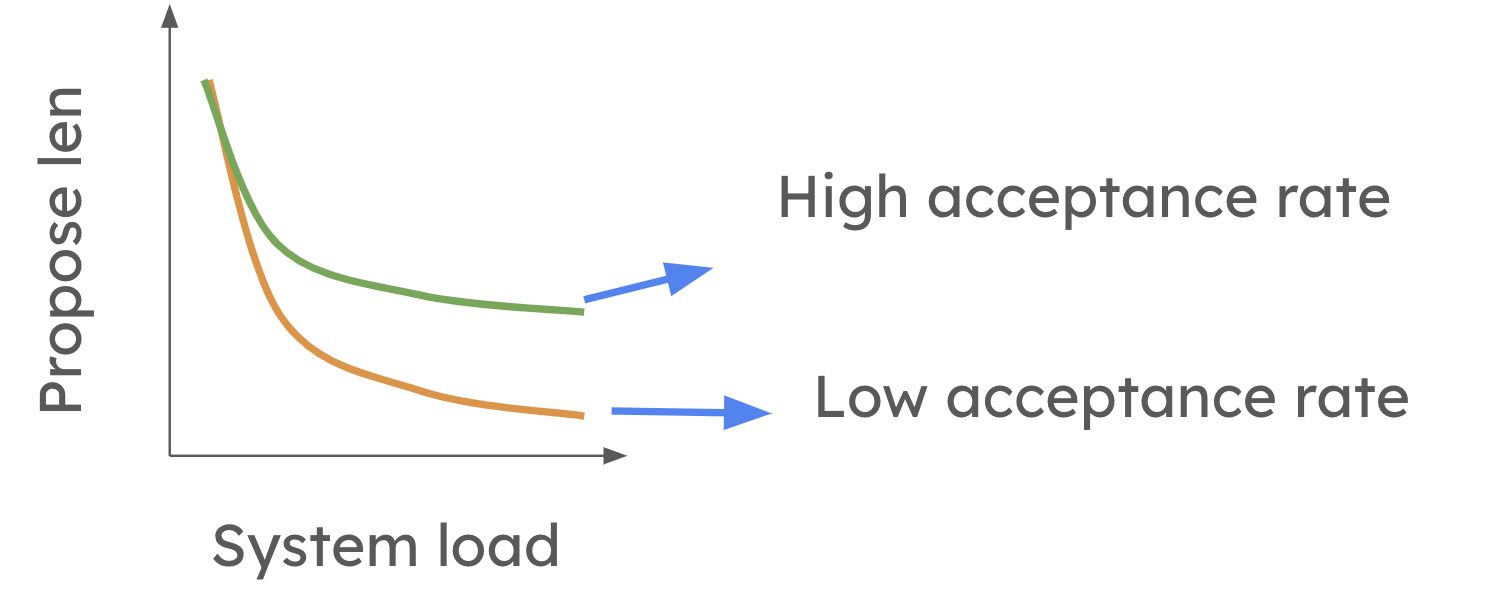
未來,系統將能夠自動修改每一步的投機程度,確保投機解碼始終是有益的,而無需考慮工作負載。這將允許使用者啟用投機解碼,而無需擔心它是否會減慢系統速度。
如何在 vLLM 中使用投機解碼
在 vLLM 中設定投機解碼非常簡單。啟動 vLLM 伺服器時,您只需包含必要的標誌來指定投機模型、令牌數量和張量並行大小。
以下程式碼配置 vLLM 在離線模式下使用帶有草稿模型的投機解碼,每次投機 5 個令牌
from vllm import LLM
llm = LLM(
model="facebook/opt-6.7b",
speculative_model="facebook/opt-125m",
num_speculative_tokens=5,
)
outputs = llm.generate("The future of AI is")
for output in outputs:
print(f"Prompt: {output.prompt!r}, Generated text: {output.outputs[0].text!r}")
以下程式碼配置 vLLM 使用投機解碼,其中提議透過匹配提示中的 n-gram 生成
from vllm import LLM
llm = LLM(
model="facebook/opt-6.7b",
speculative_model="[ngram]",
num_speculative_tokens=5,
ngram_prompt_lookup_max=4,
ngram_prompt_lookup_min=1,
)
outputs = llm.generate("The future of AI is")
for output in outputs:
print(f"Prompt: {output.prompt!r}, Generated text: {output.outputs[0].text!r}")
有時,您可能希望草稿模型以與目標模型不同的張量並行大小執行,以提高效率。這允許草稿模型使用更少的資源並減少通訊開銷,將更多資源密集型計算留給目標模型。在 vLLM 中,您可以將草稿模型配置為使用張量並行大小 1,而目標模型使用大小 4,如下例所示。
from vllm import LLM
llm = LLM(
model="meta-llama/Meta-Llama-3.1-70B-Instruct",
tensor_parallel_size=4,
speculative_model="ibm-fms/llama3-70b-accelerator",
speculative_draft_tensor_parallel_size=1,
)
outputs = llm.generate("The future of AI is")
for output in outputs:
print(f"Prompt: {output.prompt!r}, Generated text: {output.outputs[0].text!r}")
未來的更新 (論文,RFC) 將允許 vLLM 自動選擇投機令牌的數量,從而無需手動配置並進一步簡化流程。
請關注我們的文件 vLLM 中的投機解碼 以開始使用。加入我們的雙週辦公時間,提出問題並提供反饋。
結論:vLLM 中投機解碼的未來
vLLM 中的投機解碼提供了顯著的效能提升,尤其是在低 QPS 環境中。隨著動態調整的引入,即使在高 QPS 設定中,它也將成為一種高效的工具,使其成為降低延遲和提高 LLM 推理效率的多功能且必不可少的功能。