vLLM 2024 回顧與 2025 展望
vLLM 社群在 2024 年取得了顯著增長,從一個專業的推理引擎發展成為開源 AI 生態系統中事實上的服務解決方案。 這種轉變反映在我們的增長指標中
- GitHub 星星數從 14,000 增長到 32,600 (增長 2.3 倍)
- 貢獻者人數從 190 擴充套件到 740 (增長 3.8 倍)
- 月下載量從 6,000 激增至 27,000 (增長 4.5 倍)
- GPU 小時數在過去六個月內增長了約 10 倍
- 在 https://2024.vllm.ai 探索更多使用資料
vLLM 已確立其作為領先的開源 LLM 服務和推理引擎的地位,並在生產應用中得到廣泛採用(例如,為 Amazon Rufus 和 LinkedIn AI 功能提供支援)。我們的雙月例會已成為與 IBM、AWS 和 NVIDIA 等行業領導者建立合作伙伴關係的戰略聚會,標誌著我們在成為開源 AI 生態系統的通用服務解決方案方面取得了進展。 繼續閱讀以瞭解有關 vLLM 2024 年成就和 2025 年路線圖的更多詳細資訊!
這篇部落格基於雙週 vLLM 辦公時間 的第 16 次會議。 在 此處 觀看錄影。
2024 年成就:擴充套件模型、硬體和功能
社群貢獻與增長
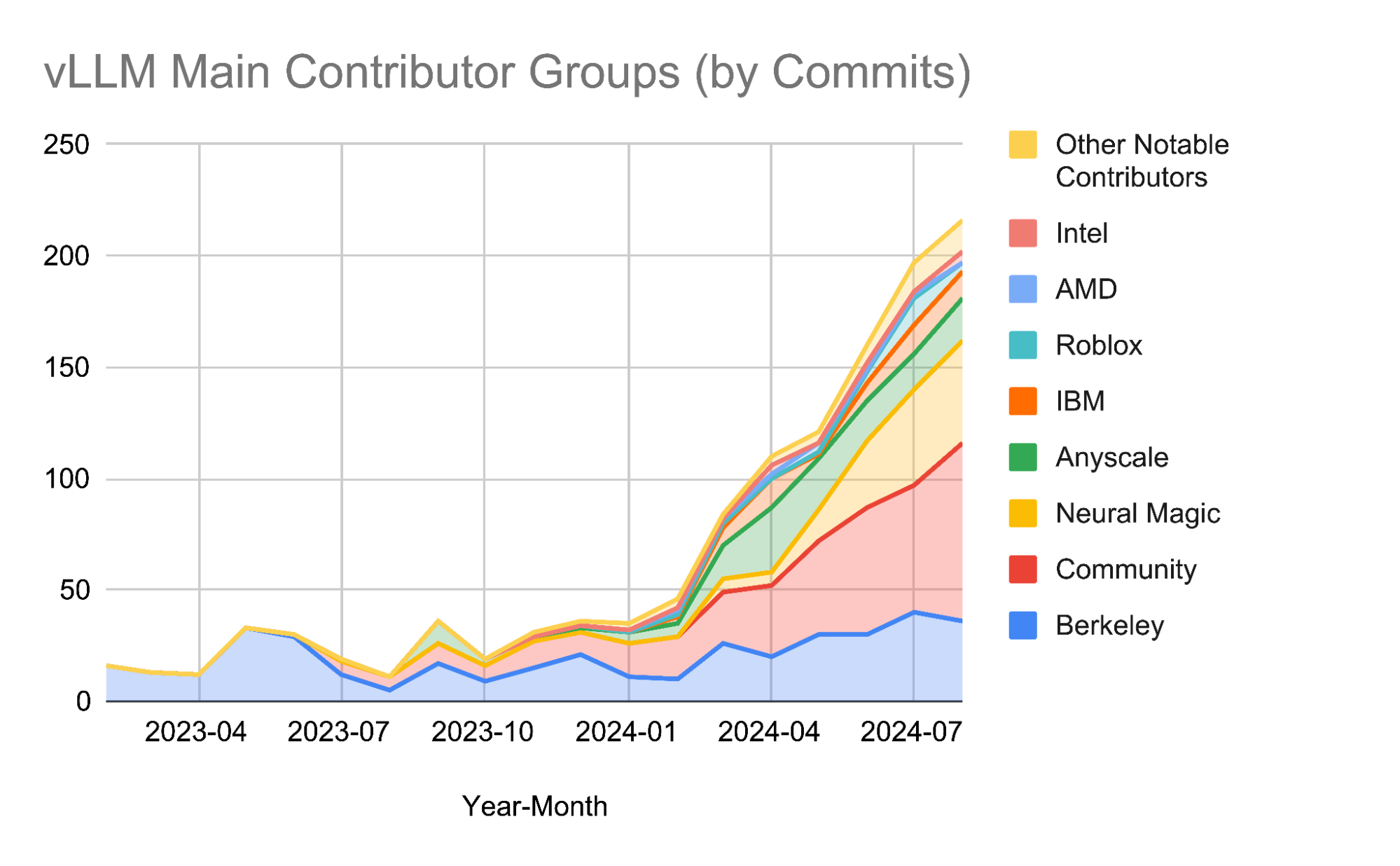
2024 年對 vLLM 來說是卓越的一年! 我們的貢獻社群已顯著擴充套件,包括
- 來自 6 個以上組織的 15+ 名全職貢獻者
- 20+ 個活躍組織作為主要利益相關者和贊助商
- 來自頂尖機構的貢獻,包括加州大學伯克利分校、Neural Magic、Anyscale、Roblox、IBM、AMD、Intel 和 NVIDIA,以及全球各地的個人開發者
- 一個蓬勃發展的生態系統,連線模型建立者、硬體供應商和最佳化開發者
- 組織良好、參與度高的雙週辦公時間,促進透明度、社群增長和戰略合作伙伴關係
這些數字不僅僅反映了增長,它們還展示了 vLLM 作為 AI 生態系統中關鍵基礎設施的角色,支援從研究原型到為數百萬使用者提供服務的生產系統的一切。
擴充套件模型支援
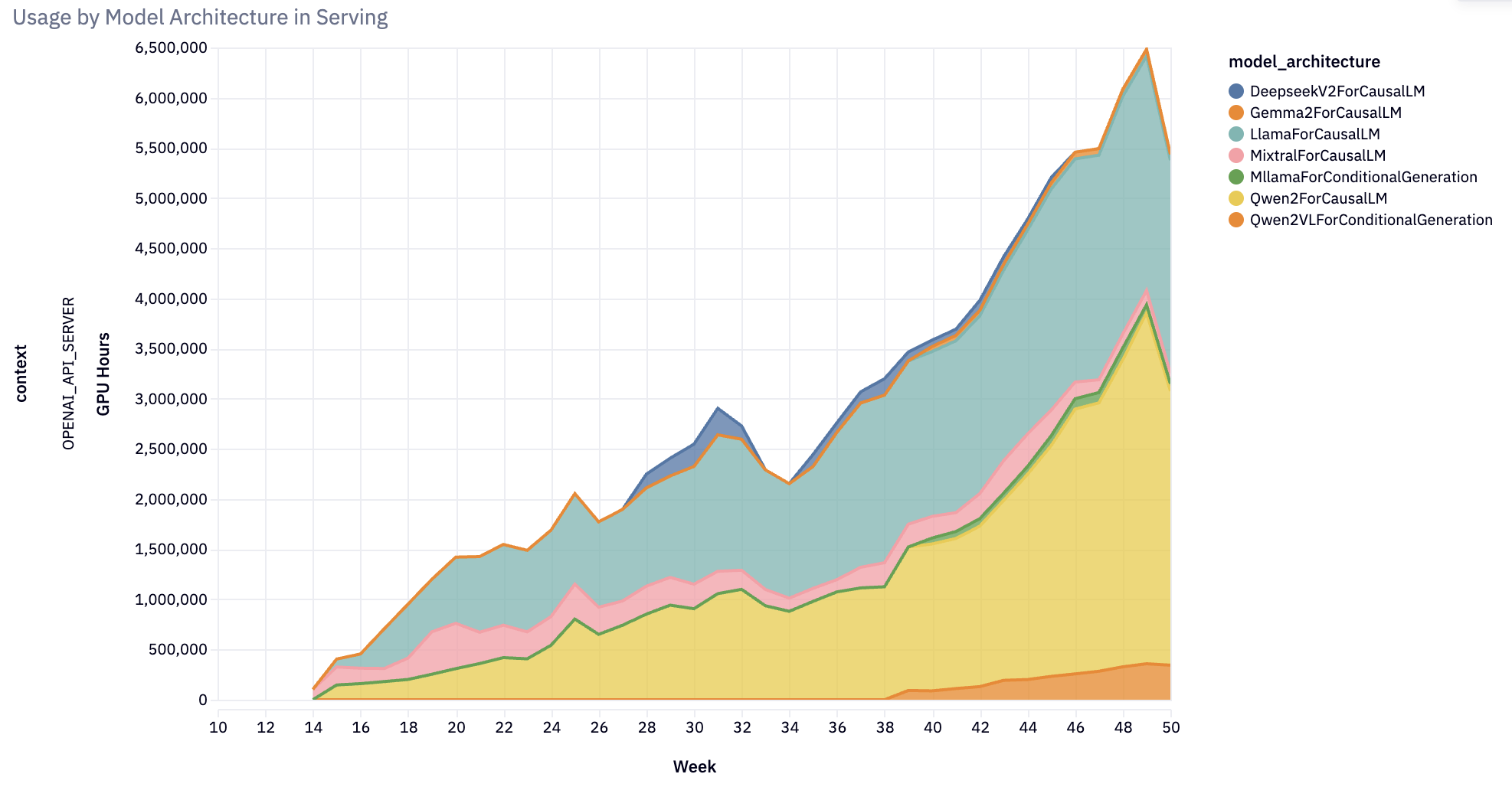
在 2024 年初,vLLM 僅支援少數模型。 到年底,該專案已發展為支援幾乎 100 種模型架構 的高效能推理:涵蓋幾乎所有著名的開源大型語言模型 (LLM)、多模態(影像、音訊、影片)、編碼器-解碼器、推測性解碼、分類、嵌入和獎勵模型。 值得注意的是,vLLM 推出了對狀態空間語言模型的生產支援,探索非 Transformer 語言模型的未來。
拓寬硬體相容性
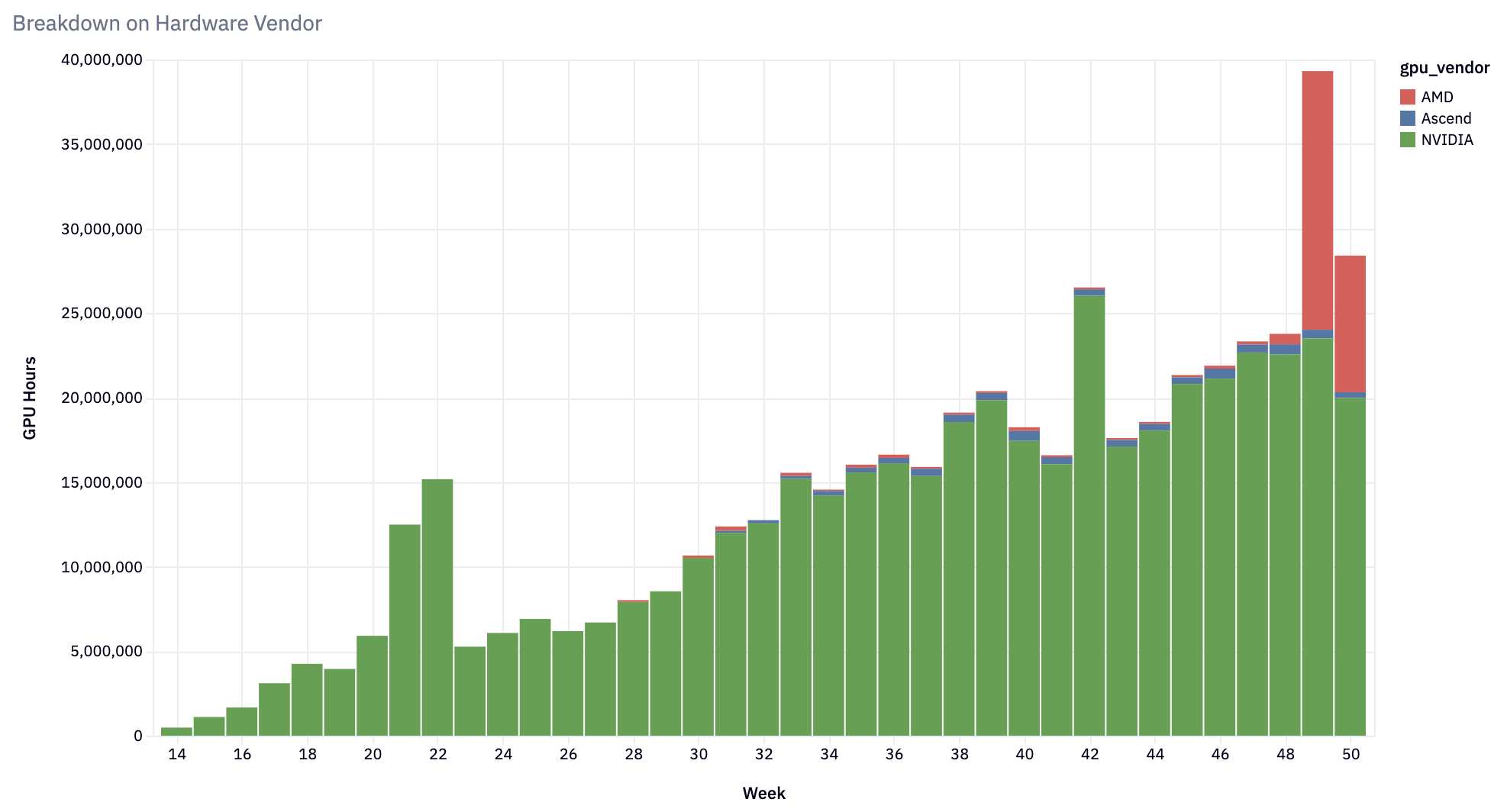
從最初的 NVIDIA A100 GPU 硬體目標開始,vLLM 已擴充套件到支援
- NVIDIA GPU:針對 H100 的一流最佳化,並支援從 V100 及更新版本開始的每款 NVIDIA GPU。
- AMD GPU:支援 MI200、MI300 和 Radeon RX 7900 系列 - MI300X 的採用率迅速增長。
- Google TPU:支援 TPU v4、v5p、v5e 和最新的 v6e。
- AWS Inferentia 和 Trainium:支援 trn1/inf2 例項。
- Intel Gaudi (HPU) 和 GPU (XPU):利用 Intel GPU 和 Gaudi 架構進行 AI 工作負載。
- CPU:支援越來越多的 ISA - x86、ARM 和 PowerPC。
vLLM 的硬體相容性已擴充套件到滿足多樣化的使用者需求,同時融入了效能改進。 重要的是,vLLM 正在朝著確保所有模型在所有硬體平臺上都能工作,並啟用所有最佳化的方向前進。
交付關鍵功能
vLLM 2024 年的開發路線圖強調了效能、可擴充套件性和可用性
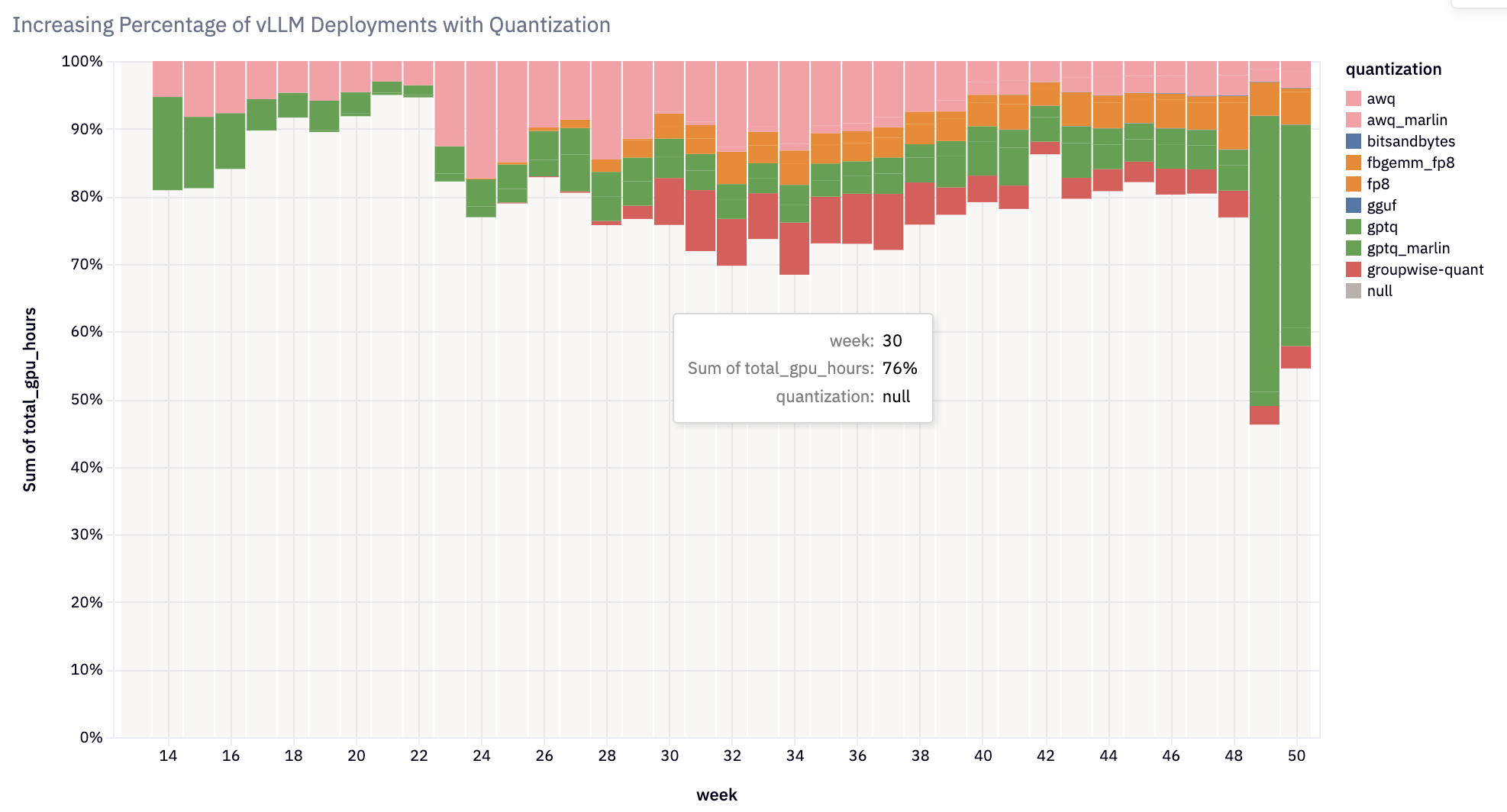
- 權重和啟用量化:增加了對多種量化方法和核心的支援,從而在各種硬體平臺上實現高效推理。 值得注意的整合包括 FP8+INT8 的啟用量化、用於 GPTQ/AWQ/wNa16 的 Marlin+Machete 核心、FP8 KV 快取、AQLM、QQQ、HQQ、bitsandbytes 和 GGUF。 現在超過 20% 的 vLLM 部署使用量化。
- 自動字首快取:降低了成本並改善了上下文密集型應用的延遲。
- 分塊預填充:增強了互動式應用中令牌間延遲的穩定性。
- 推測性解碼:透過同步令牌預測和驗證加速了令牌生成,支援草稿模型、提示中的 n-gram 匹配以及像 Medusa 或 EAGLE 這樣的 MLP 推測器。
- 結構化輸出:為需要特定格式(如 JSON 或 pydantic 模式)的應用提供了高效能功能。
- 工具呼叫:使具有受支援聊天模板的模型能夠自主生成工具呼叫,從而促進資料處理和 Agentic 流程。
- 分散式推理:引入了流水線並行和分解預填充,以有效地跨 GPU 和節點擴充套件工作負載。
我們的 2025 年展望
在 2025 年,我們預計預訓練和推理時擴充套件的邊界將迎來重大突破。 我們相信開源模型正在迅速趕上專有模型,並且透過蒸餾,這些龐大的模型正變得更小、更智慧、更適合生產部署。
新興模型能力:在單節點上服務的 GPT-4o 級別模型
我們的願景是雄心勃勃且具體的:在單個 GPU 上實現 GPT-4o 級別的效能,在單個節點上實現 GPT-4o,並在適度的叢集上實現下一代規模能力。 為了實現這一目標,我們專注於三個關鍵的最佳化前沿
-
KV 快取和注意力最佳化,包括滑動視窗、跨層注意力以及原生量化
-
MoE 最佳化,目標是具有共享專家和大量細粒度專家的架構
-
透過狀態空間模型等替代架構擴充套件長上下文支援
除了原始效能之外,我們還在為專門的垂直應用定製 vLLM。 每個用例都需要特定的最佳化:推理應用需要自定義令牌和靈活的推理步驟,編碼需要中間填充功能和提示查詢解碼,Agent 框架受益於基於樹的快取,而創意應用需要多樣化的取樣策略,包括束搜尋變體和對比解碼。
我們還在擴充套件 vLLM 在模型訓練過程中的作用。 最近像 John Schulman 這樣的著名研究人員的採用表明我們在後訓練工作流程中的重要性日益增加。 我們將提供與資料整理和後訓練流程的緊密整合,使 vLLM 成為整個 AI 開發生命週期中的重要工具。
實際規模:為數千個生產叢集提供動力
隨著 LLM 成為現代應用的主幹,我們設想 vLLM 為數千個 24/7 全天候執行的生產叢集提供動力。 這些不是實驗性部署,而是處理產品功能持續流量的關鍵任務系統,由專門的平臺團隊維護。
為了支援這種規模,我們正在使 vLLM 真正成為生產應用的開箱即用解決方案。 量化、字首快取和推測性解碼將成為預設功能,而不是可選最佳化。 結構化輸出生成將成為標準而不是例外。 我們正在開發全面的路由、快取和自動擴充套件方案,涵蓋生產部署的完整生命週期。
隨著部署規模超出單個副本,我們正在為叢集級解決方案建立穩定的介面。 這包括針對常用模型和硬體平臺調整的穩健預設配置,以及針對各種用例的靈活最佳化路徑。 我們正在培養一個致力於推動 vLLM 效率邊界的社群,確保我們的平臺不斷發展以迎接新的挑戰。
開放架構:我們未來的基礎
vLLM 持續成功的關鍵在於其開放架構。 我們正在推出 V1 版本的全新架構,這體現了這一理念。 從模型架構到排程策略,從記憶體管理到取樣策略,每個元件都旨在在研究和私有分支中進行修改和擴充套件。
我們對開放性的承諾不僅限於程式碼。 我們正在引入
-
用於無縫整合新模型、硬體後端和自定義擴充套件的可插拔架構
-
一流的
torch.compile支援,實現自定義操作融合傳遞和快速實驗 -
一個靈活的元件系統,在保持核心穩定性的同時支援私有擴充套件
我們正在加倍投入社群發展,協調跨組織的工程工作,同時慶祝生態系統專案。 這包括透過明確的招聘流程和組織結構來壯大我們的核心團隊。 我們的目標不僅僅是使 vLLM 在技術上成為最佳選擇,而是確保每個投資 vLLM 的人都因這樣做而變得更好。
我們的架構不僅僅是一個技術選擇; 它更是透過可擴充套件性和修改而不是鎖定來建立一個互聯生態系統的承諾。 透過使 vLLM 既強大又可定製,我們確保了它在 AI 推理生態系統中的核心地位。
一點反思
當我們回顧 vLLM 的歷程時,一些關鍵主題浮現出來,這些主題塑造了我們的增長並繼續指導我們前進的道路。
在 AI 生態系統中架起橋樑
最初只是一個推理引擎,現在已經發展成為更重要的東西:一個在 AI 領域中連線以前截然不同的世界的平臺。 模型建立者、硬體供應商和最佳化專家在 vLLM 中找到了獨特的貢獻放大器。 當硬體團隊開發新的加速器時,vLLM 可以立即訪問廣泛的應用生態系統。 當研究人員設計出新穎的最佳化技術時,vLLM 提供了一個生產就緒的平臺來展示現實世界的影響。 這種貢獻和放大的良性迴圈已成為我們身份的核心,推動我們不斷提高平臺的可訪問性和可擴充套件性。
在保持卓越的同時管理增長
我們在 2024 年的指數級增長帶來了機遇和挑戰。 程式碼庫和貢獻者群體的快速擴張創造了前所未有的速度,使我們能夠應對雄心勃勃的技術挑戰並快速響應社群需求。 然而,這種增長也增加了我們程式碼庫的複雜性。 我們沒有讓技術債務累積,而是果斷地選擇投資於我們的基礎。 2024 年下半年,我們對 vLLM 的核心架構進行了雄心勃勃的重新設計,最終形成了我們現在稱之為 V1 架構的架構。 這不僅僅是一次技術更新,更是一個深思熟慮的舉措,旨在確保我們的平臺在擴充套件以滿足不斷擴充套件的 AI 生態系統的需求時,仍然保持可維護性和模組化。
開創開源開發的新模式
也許我們最獨特的挑戰是透過贊助志願者網路建立一個世界一流的工程組織。 與依賴單個組織資助的傳統開源專案不同,vLLM 正在開闢一條不同的道路。 我們正在建立一個協作環境,多個組織不僅貢獻程式碼,還貢獻資源和戰略方向。 這種模式在協調、規劃和執行方面帶來了新的挑戰,但也為創新和韌性提供了前所未有的機會。 我們正在學習,有時甚至是在發明,從分散式決策到跨組織邊界的遠端協作等各個方面的最佳實踐。
我們堅定不移的承諾
縱觀所有這些變化和挑戰,我們的基本使命仍然明確:構建世界上最快、最易於使用的開源 LLM 推理和服務引擎。 我們相信,透過降低高效 AI 推理的門檻,我們可以幫助使先進的 AI 應用更實用,更易於所有人使用。 這不僅僅關乎技術卓越,更關乎建立一個基礎,使整個 AI 社群能夠更快地共同前進。
使用資料收集
本文中的指標和見解由 vLLM 的 使用系統 提供支援,該系統收集匿名部署資料。 每個 vLLM 例項都會生成一個 UUID 並報告技術指標,包括
- 硬體規格(GPU 數量/型別、CPU 架構、可用記憶體)
- 模型配置(架構、dtype、張量並行度)
- 執行時設定(量化型別、字首快取已啟用)
- 部署上下文(雲提供商、平臺、vLLM 版本)
此遙測資料有助於確定常見硬體配置的最佳化優先順序,並識別哪些功能需要效能改進。 資料在本地 ~/.config/vllm/usage_stats.json 中收集。 使用者可以透過設定 VLLM_NO_USAGE_STATS=1、DO_NOT_TRACK=1 或建立 ~/.config/vllm/do_not_track 來選擇退出。 實施細節和完整模式可在我們的 使用統計文件 中找到。
加入旅程
vLLM 2024 年的旅程展示了開源協作的變革潛力。 憑藉 2025 年的清晰願景,該專案已準備好重新定義 AI 推理,使其更易於訪問、擴充套件和高效。 無論是透過程式碼貢獻、參加 vLLM 辦公時間,還是在生產中採用 vLLM,每位參與者都在幫助塑造這個快速發展的專案的未來。
當我們進入 2025 年時,我們將繼續鼓勵社群參與,透過
- 貢獻程式碼:幫助改進 vLLM 的核心功能或擴充套件其功能 - 許多 RFC 和功能需要額外的支援
- 提供反饋:透過 GitHub、Slack、Discord 或活動分享有關功能和用例的見解,以塑造 vLLM 的路線圖
- 使用 vLLM 構建:在您的專案中採用該平臺,發展您的專業知識,並分享您的經驗
加入 vLLM 開發者 Slack,獲得專案領導者的指導,並在 AI 推理創新的前沿工作。
攜手並進,我們將在 2025 年推進開源 AI 創新!