vLLM 中的結構化解碼:簡要介紹
TL/DR(太長不看):
- 結構化解碼允許精確控制 LLM 輸出格式
- vLLM 現在支援 outlines 和 XGrammar 後端,用於結構化解碼
- 最近 XGrammar 的整合使每個輸出 token 的時間 (TPOT) 在負載下提高了 5 倍
- 即將釋出的 v1 版本專注於增強效能和混合請求批處理支援的計劃級掩碼廣播
vLLM 是用於執行大型語言模型 (LLM) 的高吞吐量和高效推理引擎。在這篇文章中,我們將探討語言模型的註釋歷史,描述 vLLM 中結構化解碼的當前狀態,以及最近與 XGrammar 的整合,以及 分享我們對未來改進的初步路線圖。
我們還邀請使用者從哲學的角度看待這篇博文,並在此過程中嘗試假設結構化解碼代表了我們思考 LLM 輸出方式的根本轉變。它在構建複雜的代理系統中也起著重要作用。
有關 vLLM 的更多資訊,請檢視我們的文件。
語言模型:簡要的歷史背景
1950 年,艾倫·圖靈提出,一臺高速數字計算機,如果用規則程式設計,可以表現出智慧的<0xE2><0x80><0xAF>湧現行為<0xE2><0x80><0xAF>(圖靈,1950 年)。這導致了人工智慧發展的兩種主要方法
-
傳統人工智慧 (GOFAI):20 世紀 50 年代,研究人員迅速興起了一種正規化,即專家系統被設計用來複制人類專家的決策能力1,(或符號<0xE2><0x80><0xAF>推理<0xE2><0x80><0xAF>系統),Haugland 將其稱為傳統人工智慧 (GOFAI)<0xE2><0x80><0xAF>(Haugeland, 1997)。然而,由於其語義表示無法擴充套件到通用任務(也稱為“人工智慧寒冬”<0xE2><0x80><0xAF>(Hendler, 2008)),它很快就遇到了資金問題。
-
新潮人工智慧 (NFAI):與此同時,唐納德·諾曼的並行分散式處理<0xE2><0x80><0xAF>(Rumelhart et al., 1986)<0xE2><0x80><0xAF>小組研究了羅森布拉特的感知<0xE2><0x80><0xAF>(Rosenblatt, 1958)<0xE2><0x80><0xAF>的變體,他們提出在網路中除了輸入和輸出之外,還要設定隱藏層,以便根據訓練過程中學到的內容推斷出適當的響應。這些連線主義網路通常建立在統計方法之上2。鑑於資料的豐富性和摩爾定律3<0xE2><0x80><0xAF>導致了前所未有的計算量,我們看到連線主義網路在研究和生產用例中都佔據了完全的主導地位,最值得注意的是<0xE2><0x80><0xAF>僅解碼器<0xE2><0x80><0xAF>轉換器的變體4<0xE2><0x80><0xAF>用於<0xE2><0x80><0xAF>文字生成<0xE2><0x80><0xAF>任務。因此,大多數現代轉換器變體都被認為是 NFAI 系統。
總結
- GOFAI 是確定性的和基於規則的,因為它的意圖是透過顯式程式設計注入的
- NFAI 通常被認為是“黑盒”模型(輸入:輸入 - 輸出:一些輸出),資料驅動的,因為其內部表示的網路複雜性
為什麼我們需要結構化解碼?
LLM 在以下啟發式方法中表現出色:給定一段文字,模型將生成一段連續的文字,它預測該文字是最有可能的 token。例如,如果您給它一篇維基百科文章,模型應該生成與該文章其餘部分一致的文字。
在以下假設下,這些模型執行良好:輸入提示必須是連貫且結構良好的,圍繞使用者想要實現的給定問題。換句話說,當您需要特定格式的輸出時,LLM 可能是不可預測的。想想讓模型生成 JSON——如果沒有指導,它可能會生成有效的文字,但會破壞 JSON 規範5。
這就是結構化解碼的用武之地。它使 LLM 能夠生成遵循所需結構的輸出,同時保留系統的非確定性性質。
像 OpenAI 這樣的公司已經認識到這種需求,並實施了諸如 JSON 模式 等功能來約束6 輸出格式。如果您之前使用過這些功能(例如代理工作流、函式呼叫、編碼助手),那麼您很可能正在使用底層結構化解碼。
引導解碼對於 LLM 就像 驗證 對於 API 一樣——它保證輸出與您的期望相符。引導解碼確保結構完整性,使開發人員能夠輕鬆地將 LLM 整合到他們的應用程式中!
結構化解碼和 vLLM
簡單來說,結構化解碼為 LLM 提供了一個要遵循的“模板”。使用者提供一個“影響”模型輸出的模式,確保符合所需的結構

從技術角度來看,推理引擎可以透過為任何給定模式的所有 token 應用偏差(通常透過 logits 掩碼)來修改下一個 token 的機率分佈。為了應用這些偏差,outlines 提出了透過有限狀態機 (FSM) 為任何給定模式進行引導生成<0xE2><0x80><0xAF>(Willard & Louf, 2023)。這使我們能夠在解碼期間跟蹤當前狀態,並透過對輸出應用 logits 偏差來過濾掉無效 token。
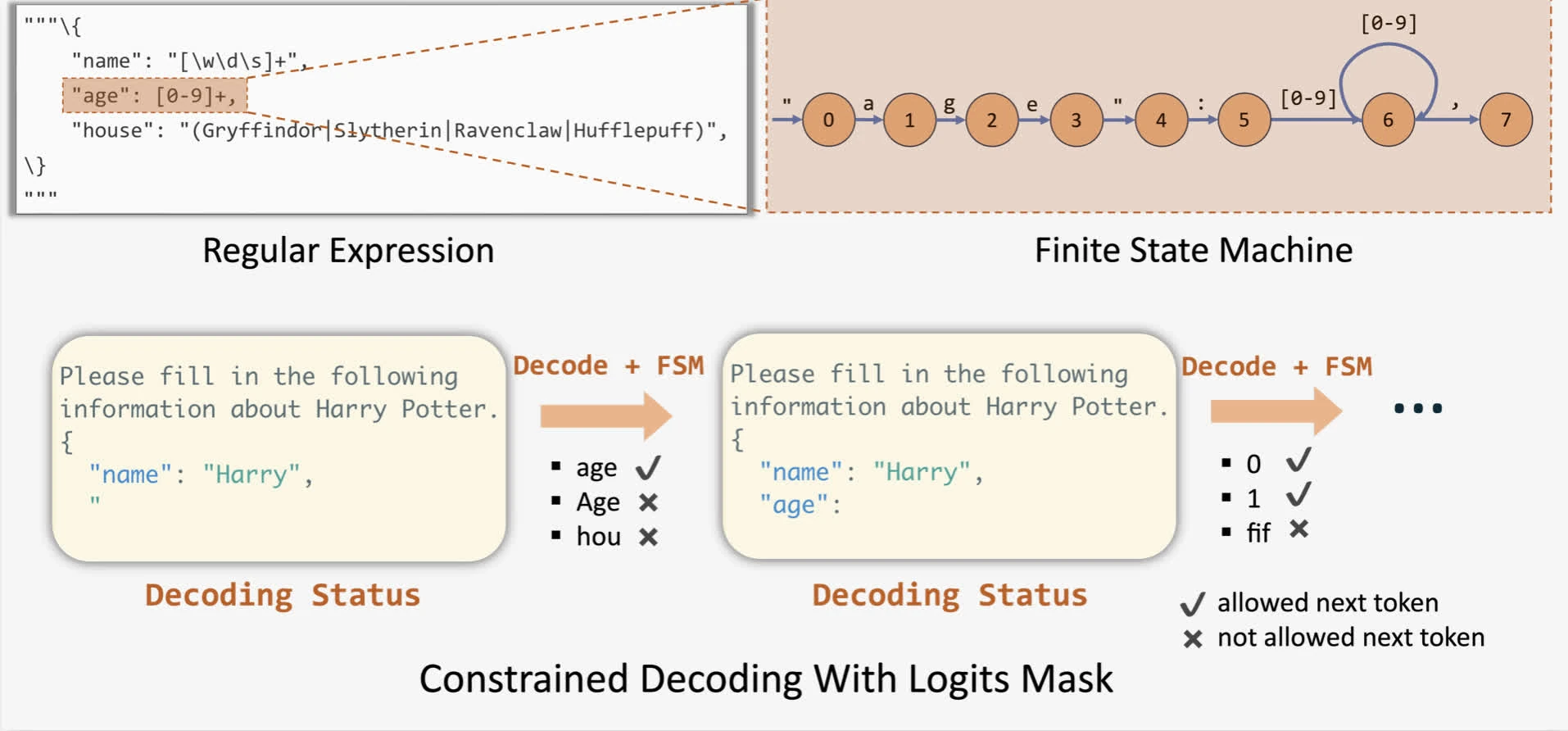
在 vLLM 中,您可以透過將 JSON 模式傳遞給取樣引數(透過 Python SDK 或 HTTP 請求)來使用它。
注意:在某些情況下,它甚至可以提高 LLM 的原生解碼效能!
vLLM 之前的限制
當前 vLLM 對 Outlines 後端的支援存在一些限制
- 解碼速度慢:FSM 必須在 token 級別構建,這意味著它每步只能轉換一個 token 的狀態。因此,它一次只能解碼一個 token,導致解碼速度緩慢。
- 批處理瓶頸:vLLM 中的實現嚴重依賴 logits 處理器7。因此,這是取樣過程的關鍵路徑。在批處理用例中,為每個請求編譯 FSM 以及同步計算掩碼意味著任何給定批次中的所有請求都將被阻止,從而導致較高的首個 token 時間 (TTFT) 和較低的吞吐量。
- 我們發現編譯 FSM 被證明是一項相對昂貴的任務,使其成為 TTFT 增加的重要因素。
- CFG 模式下的效能問題:透過 outlines 整合,雖然 JSON 模式相對較快,但 CFG 模式執行速度明顯較慢,並且偶爾會崩潰引擎。
- 有限的高階功能支援:像 jump-forward decoding 這樣的技術目前在 logits 處理器方法中是不可行的。它需要預填充一組 k-next token,而對於 logits 處理器,我們只能處理下一個 token。
與 XGrammar 整合
XGrammar 引入了一種新技術,透過下推自動機 (PDA) 批次約束解碼。您可以將 PDA 視為“FSM 的集合,每個 FSM 代表一個上下文無關文法 (CFG)”。PDA 的一個顯著優勢是其遞迴性質,允許我們執行多個狀態轉換。它們還包括額外的最佳化(對於那些感興趣的人)以減少文法編譯開銷。
這項進步透過將文法編譯從 Python 移至 C,利用 pthread,解決了限制 (1)。此外,XGrammar 為解決未來版本中的限制 (4) 奠定了基礎。以下是 XGrammar 和 Outlines 後端之間的效能比較
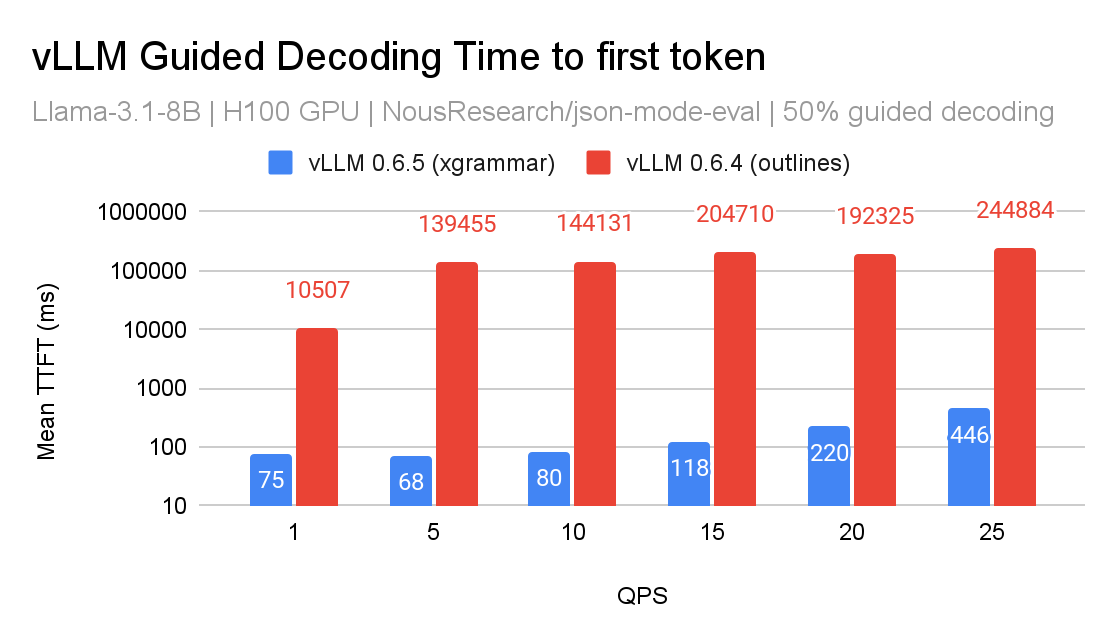
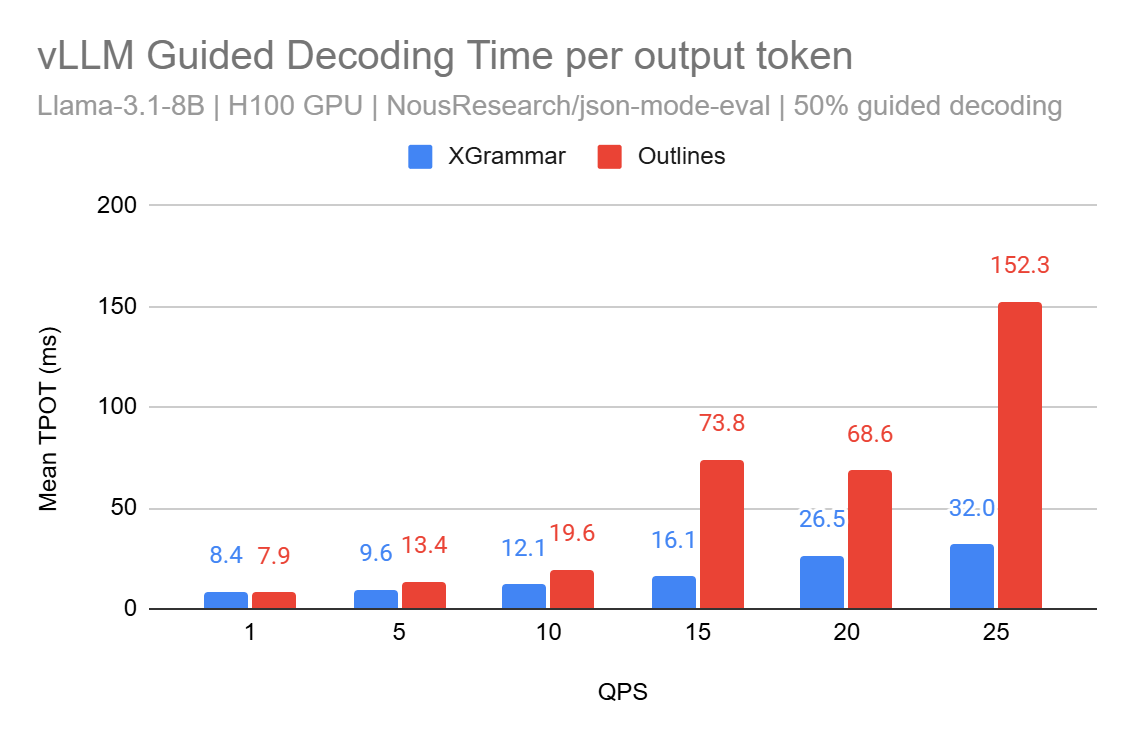
在 vLLM 的 v0 架構中,我們將 XGrammar 實現為 logits 處理器,並透過快取 tokenizer 資料對其進行最佳化。雖然效能改進令人鼓舞,但我們相信仍有很大的最佳化空間。
在 XGrammar v0 整合中,仍然存在一些可用性問題,無法與所有用例的功能對等
- 它尚不支援 GBNF 格式以外的文法(vLLM 上的 PR:github)
- 它尚不支援正則表示式
- 它尚不支援使用正則表示式模式或數值範圍的複雜 JSON
- 有一些 PR 試圖涵蓋這種用法。有一個 vLLM 上的 bugfix PR 和一個 上游
vLLM 現在預設基本支援 XGrammar。在我們知道 XGrammar 不足以滿足請求的情況下,我們會回退到 Outlines。
請注意,vLLM 還包括對 lm-format-enforcer 的支援。但是,從我們的測試中,我們發現,在某些長上下文測試用例中,lm-format-enforcer 無法強制執行正確的輸出,並且在效能方面不如 Outlines。
v1 的初步計劃
隨著 v1 即將釋出,我們正在制定結構化解碼的初步計劃
- 將引導解碼轉移到排程器級別
- 原因:我們在排程器級別有更多關於哪些請求使用結構化解碼的上下文,因此它不應阻止批處理中的其他請求(初步解決限制 (2))。從某種意義上說,這會將引導解碼移出關鍵路徑。
- 這將允許與 jump-forward decoding 更自然的垂直整合(解決限制 (4))。
- 允許在一個程序中而不是每個 GPU 工作人員中進行位掩碼計算
- 原因:我們可以將此位掩碼廣播到每個 GPU 工作人員,而不是為每個 GPU 工作人員重複此過程。
- 我們將仔細分析對每個使用引導解碼的請求的每個樣本廣播掩碼的頻寬影響。
- 推測性解碼和工具使用的良好基線
- 原因:XGrammar 包括支援工具使用的計劃,這樣我們就可以擺脫 Python 的 tool parser。
- 推測性解碼中的樹評分然後可以使用與 jump-forward decoding 相同的 API(這取決於引導解碼在排程器級別的整合)。
注意:如果您有任何更多建議,我們非常樂意考慮。考慮透過 #feat-structured-output 加入 vLLM slack。
致謝
我們要感謝 vLLM 團隊、XGrammar 團隊、Aaron Pham (BentoML)、Michael Goin (Red Hat)、Chendi Xue (Intel) 和 Russell Bryant (Red Hat) 在將 XGrammar 引入 vLLM 以及不斷努力改進 vLLM 中的結構化解碼方面的寶貴反饋和協作。
參考文獻
- Bahdanau, D., Cho, K., & Bengio, Y. (2016). 透過聯合學習對齊和翻譯進行神經機器翻譯. arXiv 預印本 arXiv:1409.0473
- Haugeland, J. (1997). 心靈設計 II:哲學、心理學和人工智慧. MIT 出版社。 https://doi.org/10.7551/mitpress/4626.001.0001
- Hendler, J. (2008). 避免另一次人工智慧寒冬。 IEEE 智慧系統, 23(2), 2–4. https://doi.org/10.1109/MIS.2008.20
- Hochreiter, S., & Schmidhuber, J. (1997). 長短期記憶。 神經計算。
- Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). 神經語言模型的縮放定律. arXiv 預印本 arXiv:2001.08361
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). 向量空間中詞表示的有效估計. arXiv 預印本 arXiv:1301.3781
- Rosenblatt, F. (1958). 感知器:大腦中資訊儲存和組織的機率模型。 心理學評論, 65(6), 386–408. https://doi.org/10.1037/h0042519
- Rumelhart, D. E., McClelland, J. L., & Group, P. R. (1986). 並行分散式處理,第 1 卷:認知微觀結構探索:基礎. MIT 出版社。 https://doi.org/10.7551/mitpress/5236.001.0001
- Shortliffe, E. H. (1974). MYCIN:用於為醫生提供抗菌治療選擇建議的基於規則的計算機程式 (技術報告 STAN-CS-74-465)。斯坦福大學。
- 統計機器翻譯。(n.d.). IBM 模型. 統計機器翻譯調查。 http://www2.statmt.org/survey/Topic/IBMModels
- Turing, A. M. (1950). i.—計算機械與智慧。 心靈, LIX(236), 433–460. https://doi.org/10.1093/mind/LIX.236.433
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). 注意力機制是你所需要的一切. arXiv 預印本 arXiv:1706.03762
- Willard, B. T., & Louf, R. (2023). 大型語言模型的高效引導生成. arXiv 預印本 arXiv:2307.09702
-
艾倫·紐厄爾和赫伯特·西蒙在蘭德公司的工作最初表明,計算機可以模擬智慧的重要方面。
另一個值得注意的應用是在醫學領域 (Haugeland, 1997)。MYCIN 是 20 世紀 70 年代在斯坦福大學開發的,用於診斷和推薦血液感染的治療方法 (Shortliffe, 1974)。MYCIN 的開發者認識到證明建議合理性的重要性,並實施了所謂的“規則追蹤”來以人類易於理解的方式解釋系統的推理。↩
-
在 20 世紀 90 年代,IBM 釋出了一系列複雜的統計模型,這些模型經過訓練以執行機器翻譯 任務(統計機器翻譯,n.d.)(另請參閱:康奈爾大學的這份講義)。
2001 年,詞袋 (BoW) 變體模型在 0.3B token 上進行了訓練,當時被認為是 SOTA (Mikolov et al., 2013)。這些早期的工作向研究界證明,考慮到統計建模可以捕獲大型文字語料庫的一般模式,統計建模優於用於語言處理的符號對應物。↩
-
2017 年,具有里程碑意義的論文“注意力機制是你所需要的一切”為神經機器翻譯任務引入了 Transformer 架構 (Vaswani et al., 2023),該架構基於 (Bahdanau et al., 2016) 首次提出的注意力機制。
然後,OpenAI 引入了神經語言模型的縮放定律 (Kaplan et al., 2020),這引發了基於基礎語言模型構建這些系統的競賽。↩
-
在基於注意力的 Transformer 之前,seq-to-seq 模型使用 RNN,因為它具有更長的上下文長度和更好的記憶體。但是,與前饋網路相比,它們更容易受到梯度消失/爆炸的影響,因此提出了 LSTM (Hochreiter & Schmidhuber, 1997) 來解決這個問題。然而,LSTM 的主要問題之一是,對於很久以前看到的資料,它們的記憶力往往很差。
注意力機制論文透過將額外的位置資料編碼到輸入中來解決這個問題。該論文還額外提出了一種用於翻譯任務的編碼器-解碼器架構,但是,鑑於其在零樣本任務中的卓越效能,現在大多數文字生成模型都是僅解碼器模型。
基於注意力的 Transformer 比 LSTM 效果更好的眾多原因之一是因為 Transformer 非常可擴充套件且硬體感知(您不能隨意新增更多 LSTM 塊並期望獲得更好的長期保留)。有關更多資訊,請參閱原始論文。↩
-
有人可能會爭辯說,我們可以透過少樣本提示可靠地實現這些,即“給我一個 JSON,它產生使用者的地址。示例輸出可以是……”。但是,不能保證生成的輸出是有效的 JSON。這是因為這些模型是機率系統,因為它們是根據模型訓練資料的分佈“取樣”下一個結果。
有人可能還會爭辯說,應該使用特定的微調模型進行 JSON 輸出以執行此類情況。但是,微調通常需要大量的訓練和更多的人工來管理資料、監控進度和執行評估,這不是每個人都能負擔得起的巨大資源。↩
-
請注意,短語“[結構化/約束/引導]解碼”可以互換使用,但它們都指的是“使用格式讓模型結構化取樣輸出”的相同機制。↩