vLLM production-stack 在 K8S 中的高效能和簡易部署
TL;DR(摘要)
- vLLM 擁有最大的開源社群,但是要將 vLLM 從最佳單節點 LLM 引擎轉變為一流的 LLM 服務系統,還需要做些什麼呢?
- 今天,我們釋出 “vLLM production-stack”,這是一個基於 vLLM 的完整推理堆疊,它引入了兩大主要優勢
- 效能提升 10 倍(響應延遲降低 3-10 倍,吞吐量提高 2-5 倍),這得益於字首感知請求路由和 KV 快取共享。
- 簡易的叢集部署,內建支援容錯、自動擴縮容和可觀測性。
- 最棒的是,它是開源的——因此每個人都可以立即開始使用! [https://github.com/vllm-project/production-stack]
背景
在 AI 軍備競賽中,重要的不再僅僅是誰擁有最好的模型,而是誰擁有最好的 LLM 服務系統。
vLLM 以其無與倫比的硬體和模型支援,以及由頂尖貢獻者組成的活躍生態系統,在開源社群中掀起了一股熱潮。但到目前為止,vLLM 主要專注於單節點部署。
我們如何將其能力擴充套件到一個全棧推理系統,以便任何組織都能夠以高可靠性、高吞吐量和低延遲進行大規模部署?這正是 LMCache 團隊和 vLLM 團隊構建 vLLM production-stack 的原因。
隆重推出 “vLLM Production-Stack”
vLLM Production-stack 是一個開源的 參考實現,它是一個構建在 vLLM 之上的 推理堆疊,旨在叢集 GPU 節點上無縫執行。它添加了四個關鍵功能,以補充 vLLM 的原生優勢
- KV 快取共享和儲存,以加速上下文重用時的推理速度(由 LMCache 專案驅動)。
- 字首感知路由,將查詢傳送到已持有相關上下文 KV 快取的 vLLM 例項。
- 可觀測性,用於監控各個引擎狀態和查詢級別的指標(首個令牌時間 TTFT、令牌間時間 TBT、吞吐量)。
- 自動擴縮容,以應對工作負載的動態變化。
與替代方案的比較
以下是一個快速快照,將 vLLM production-stack 與其最接近的競爭對手進行了比較

設計
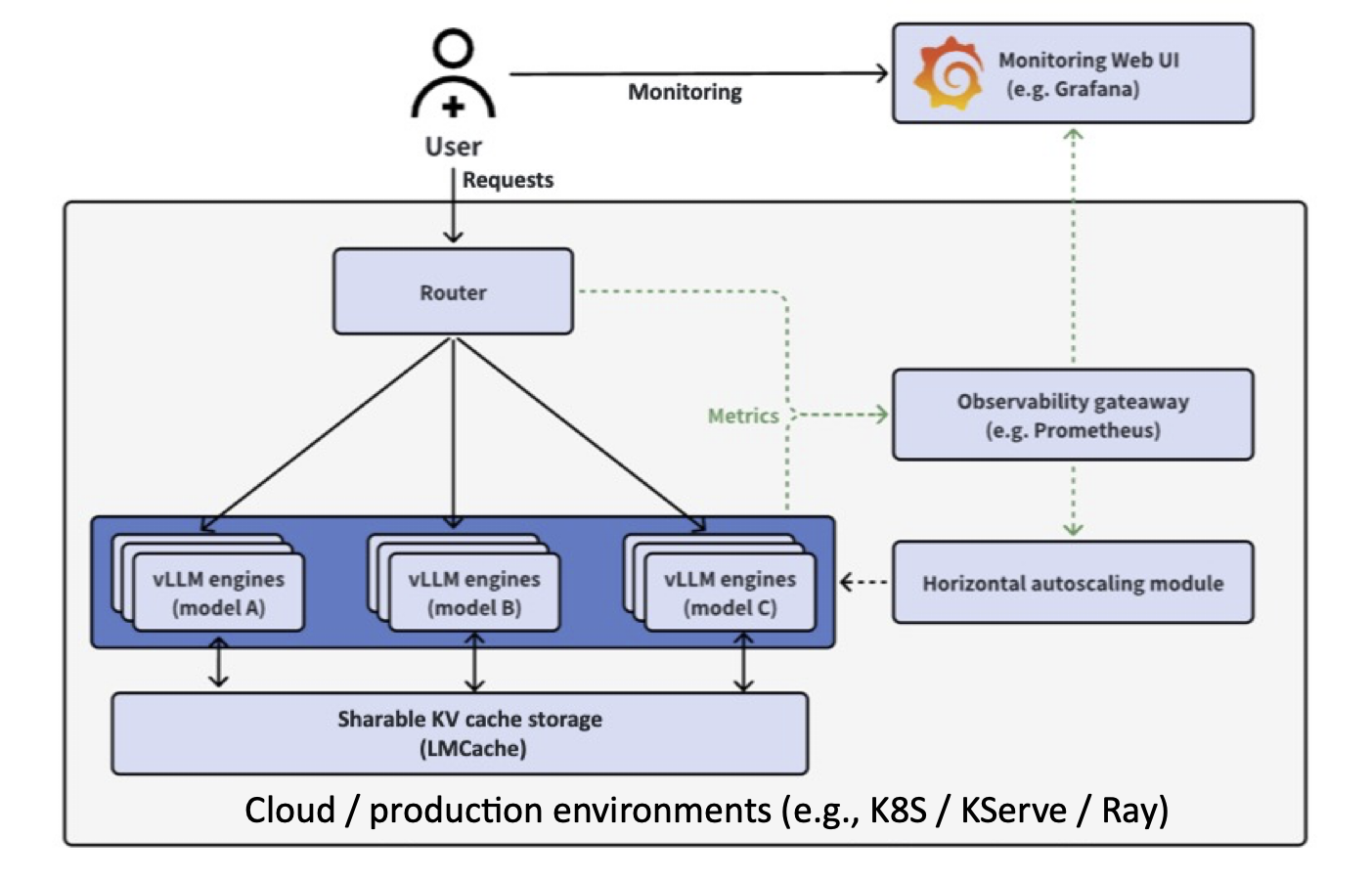
vLLM production-stack 架構構建在 vLLM 強大的單節點引擎之上,以提供叢集範圍的解決方案。
在高層次上
- 應用程式傳送 LLM 推理請求。
- 字首感知路由檢查請求的上下文是否已快取在某個例項的記憶體池中。然後,它將請求轉發到具有預計算快取的節點。
- 自動擴縮容和叢集管理器監視整體負載,並在需要時啟動新的 vLLM 節點。
- 可觀測性模組收集諸如 TTFT(首個令牌時間)、TBT(令牌間時間)和吞吐量等指標,讓您可以即時瞭解系統的健康狀況。
優勢 #1:簡易部署
透過執行單個命令,使用 helm chart 將 vLLM production-stack 部署到您的 k8s 叢集
sudo helm repo add llmstack-repo https://lmcache.github.io/helm/ &&\
sudo helm install llmstack llmstack-repo/vllm-stack
有關更多詳細資訊,請參閱 vLLM production-stack repo 中的詳細 README。關於設定 k8s 叢集和自定義 helm charts 的 教程 也已提供。
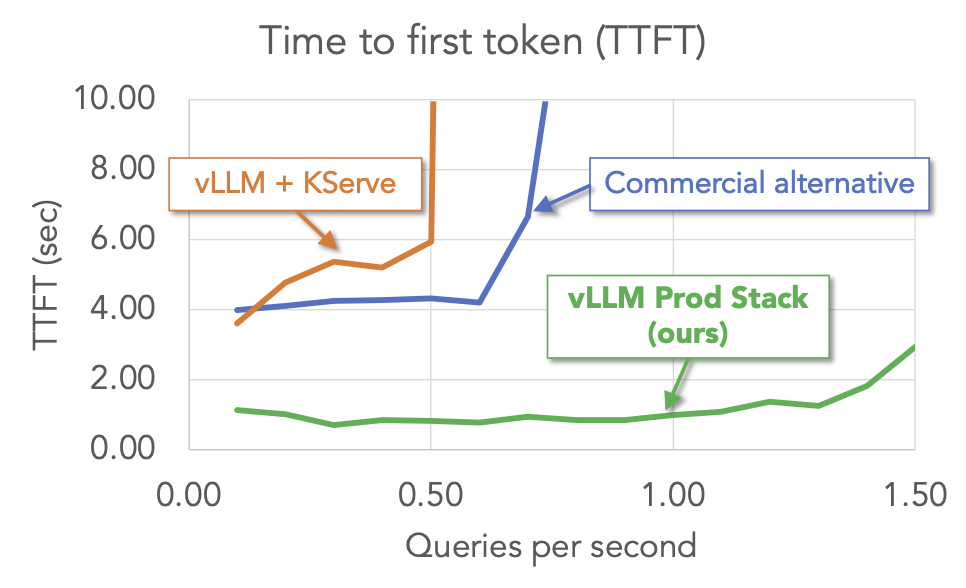
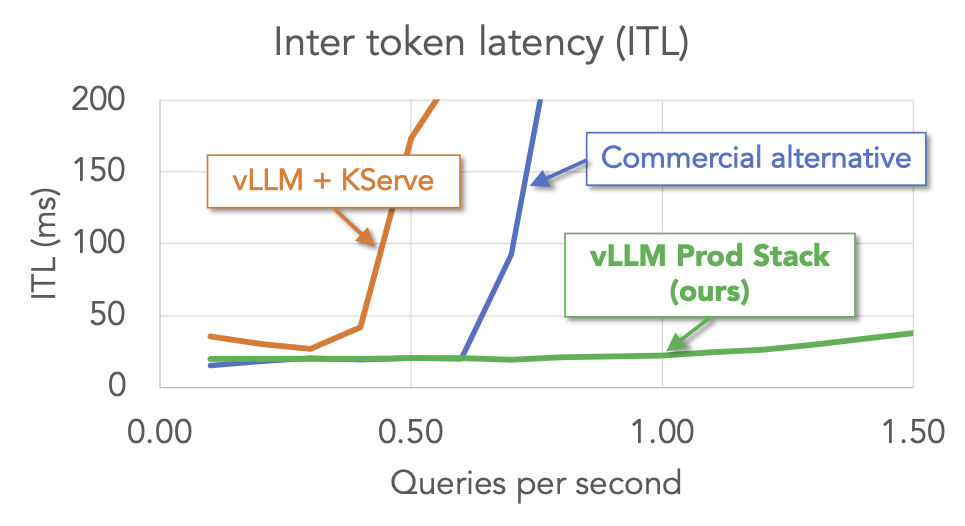
優勢 #2:更佳效能
我們對 vLLM production-stack 和其他設定(包括 vLLM + KServe 和商業端點服務)進行了多輪問答工作負載的基準測試。結果表明,在關鍵指標(首個令牌時間和令牌間延遲)方面,vLLM stack 優於其他設定。
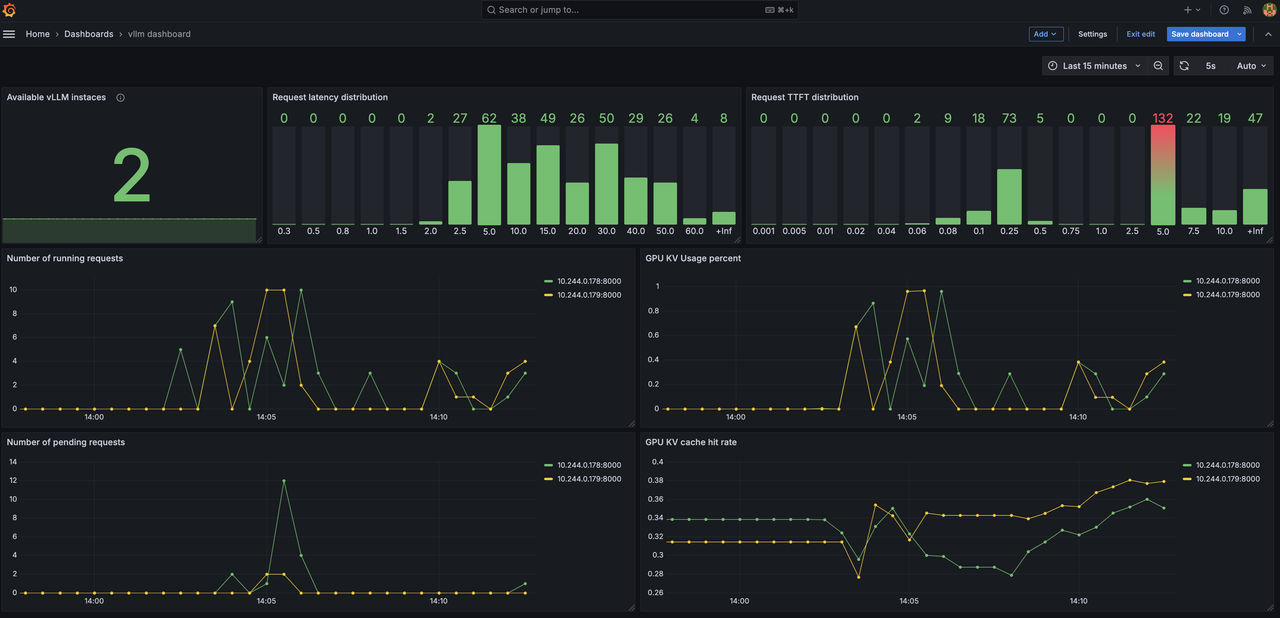
優勢 #3:輕鬆監控
透過關鍵指標(包括延遲分佈、隨時間變化的請求數量、KV 快取命中率),即時跟蹤您的 LLM 推理叢集。
結論
我們很高興推出 vLLM Production Stack——將 vLLM 從一流的單節點引擎轉變為全規模 LLM 服務系統的下一步。我們相信 vLL stack 將為尋求構建、測試和部署大規模 LLM 應用程式的組織開啟新的大門,同時不犧牲效能或簡易性。
如果您和我們一樣興奮,請不要等待!
- 克隆倉庫:https://github.com/vllm-project/production-stack
- 試用一下
- 請告訴我們您的想法!
- 興趣表單
加入我們,共同構建一個未來,讓每個應用程式都能可靠地、大規模地、輕鬆地利用 LLM 推理的力量。部署愉快!
聯絡方式