使用 vLLM 進行分散式推理
動機
服務大型模型通常會導致記憶體瓶頸,例如可怕的 CUDA 記憶體不足錯誤。為了解決這個問題,主要有兩種方案
- 降低精度 – 利用 FP8 和更低位數的量化方法可以減少記憶體使用。然而,這種方法可能會影響準確性和可擴充套件性,並且隨著模型規模增長到數千億引數以上,它本身是不夠的。
- 分散式推理 – 將模型計算分佈在多個 GPU 或節點上可以實現可擴充套件性和效率。這就是張量並行和流水線並行等分散式架構發揮作用的地方。
vLLM 架構和大型語言模型推理挑戰
與訓練相比,LLM 推理提出了獨特的挑戰
- 與純粹關注具有已知靜態形狀的吞吐量的訓練不同,推理需要低延遲和動態工作負載處理。
- 推理工作負載必須有效管理 KV 快取、推測解碼和預填充到解碼的轉換。
- 大型模型通常超出單 GPU 容量,需要先進的並行化策略。
為了解決這些問題,vLLM 提供了
- 張量並行,用於將每個模型層分片到節點內的多個 GPU 上。
- 流水線並行,用於將模型層的連續部分分佈到多個節點上。
- 最佳化的通訊核心和控制平面架構,以最大限度地減少 CPU 開銷並最大限度地提高 GPU 利用率。
vLLM 中的 GPU 並行技術
張量並行
問題:模型超出單 GPU 容量
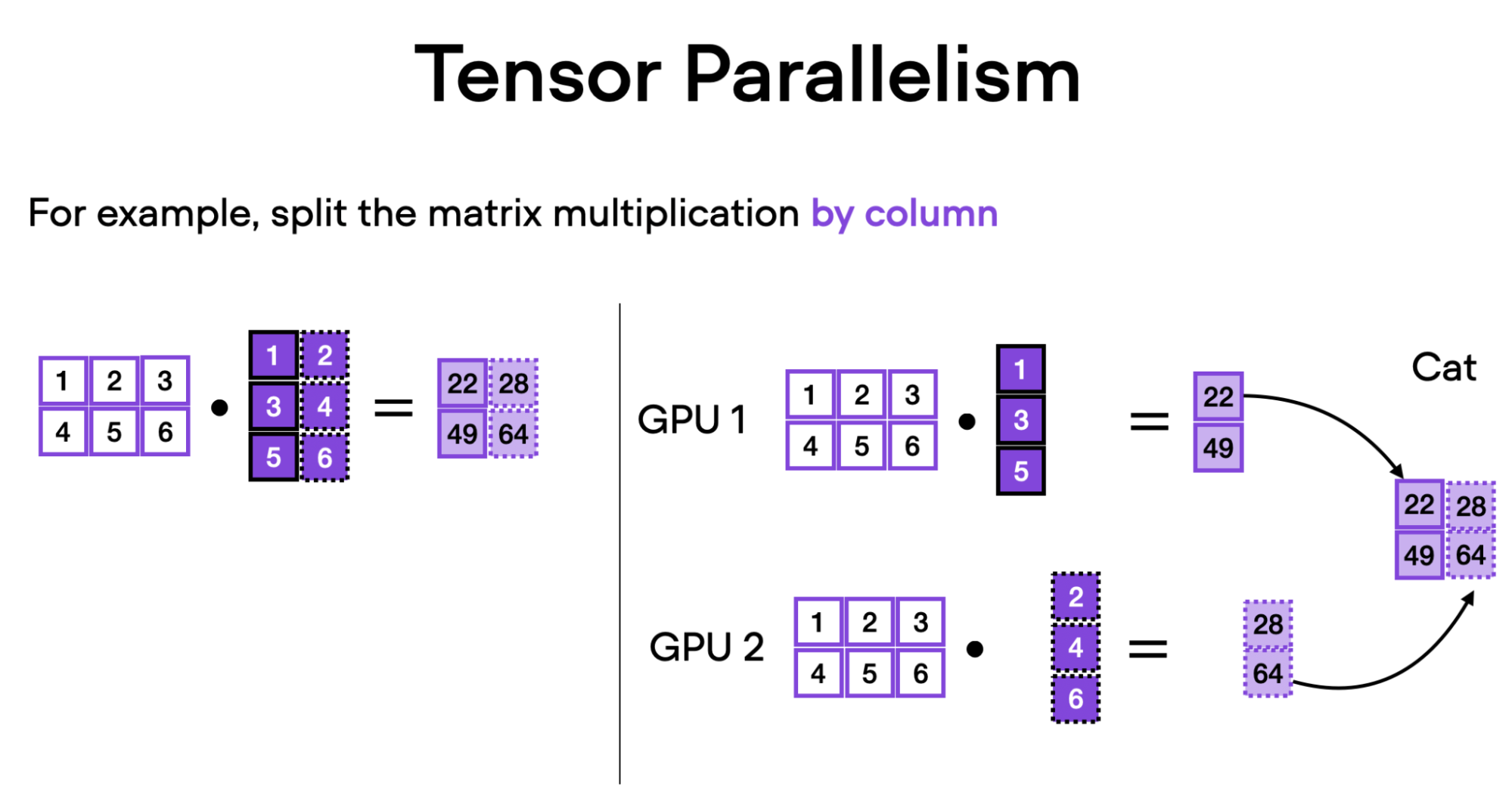
隨著模型規模的增長,單個 GPU 無法容納它們,因此需要多 GPU 策略。張量並行將模型權重分片到多個 GPU 上,從而允許併發計算,以實現更低的延遲和增強的可擴充套件性。
這種方法最初是在 Megatron-LM (Shoeybi 等人,2019) 中為訓練而開發的,已經在 vLLM 中針對推理工作負載進行了調整和最佳化。
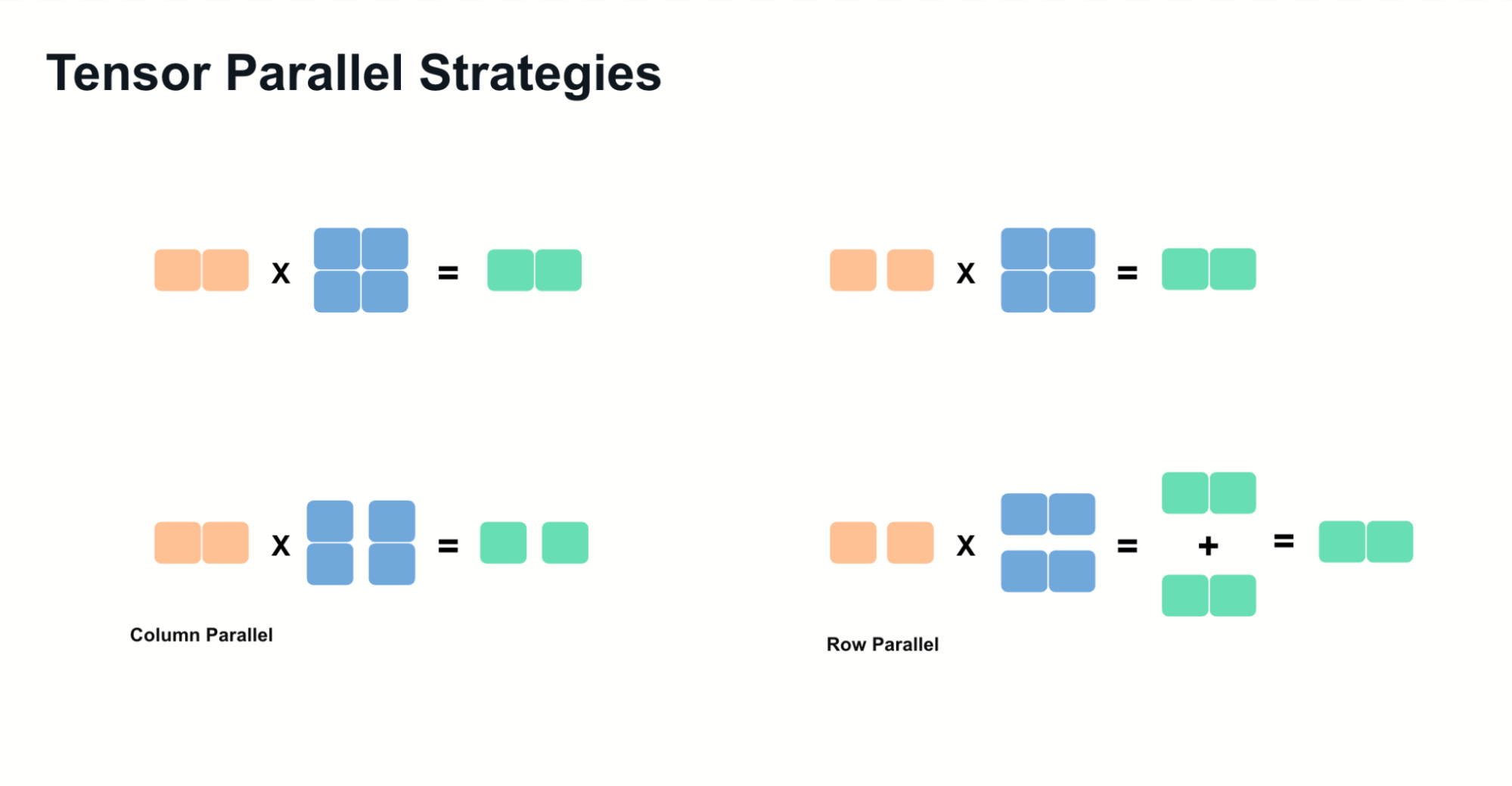
張量並行依賴於兩種主要技術
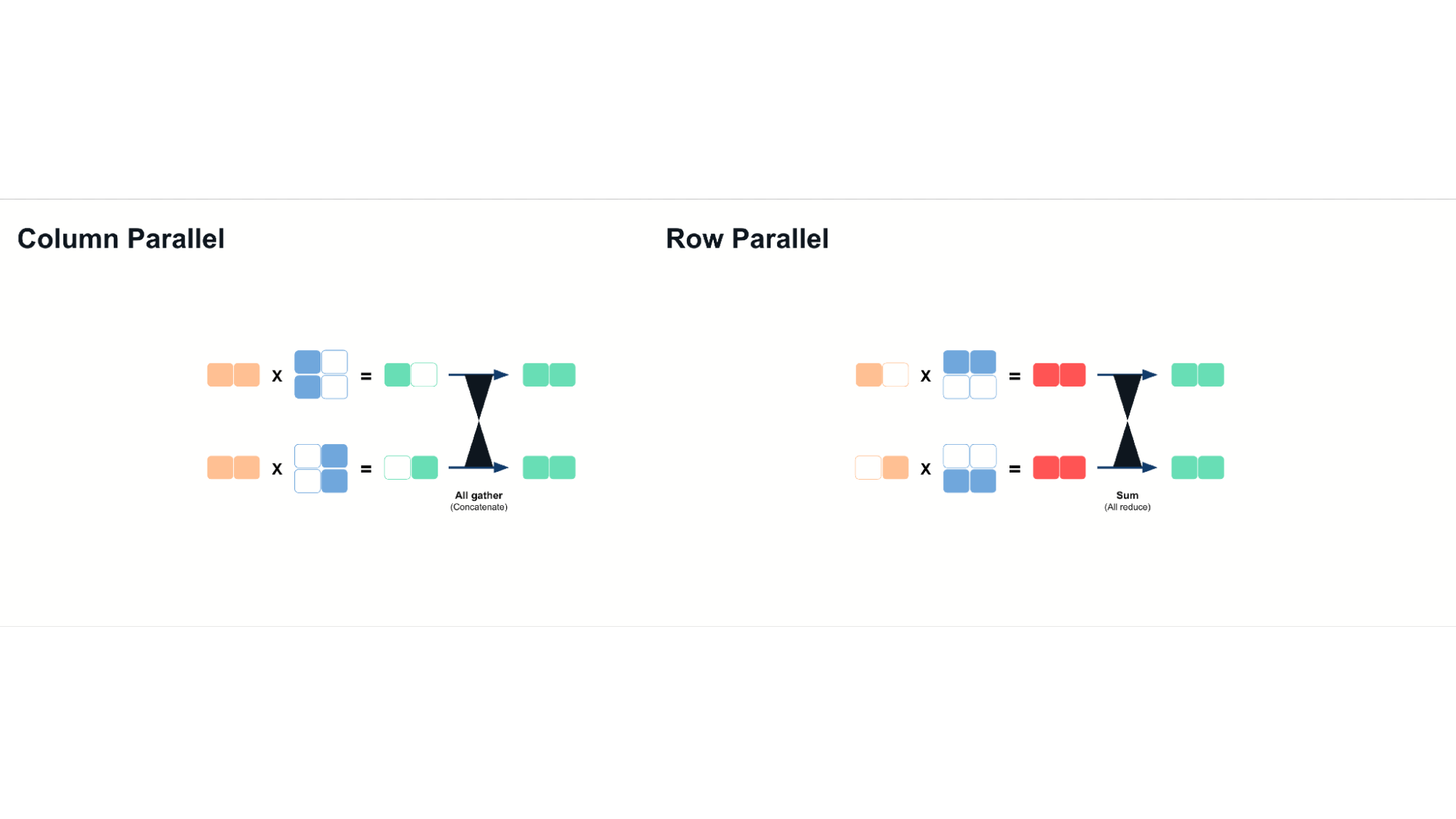
- 列並行:沿列拆分權重矩陣,並在計算後連線結果。
- 行並行:沿行拆分矩陣,並在計算後對部分結果求和。
作為一個具體的例子,讓我們分解一下這種並行性如何在 Llama 模型中的 MLP(多層感知器)層中工作
- 列並行適用於上投影操作。
- 逐元素啟用函式(例如,SILU)對分片輸出進行操作。
- 行並行用於下投影,並使用 all-reduce 操作來聚合最終結果。
張量並行確保推理計算分佈在多個 GPU 上,最大限度地利用可用的記憶體頻寬和計算能力。使用張量並行時,我們可以透過有效提高記憶體頻寬來獲得延遲改進。這是因為分片模型權重允許多個 GPU 並行訪問記憶體,從而減少單個 GPU 可能遇到的瓶頸。
然而,它需要每個 GPU 之間具有高頻寬互連,例如 NVLink 或 InfiniBand,以最大限度地減少來自增加的通訊成本的開銷。
流水線並行
問題:模型超出多 GPU 容量
對於極大型模型(例如,DeepSeek R1、Llama 3.1 405B),單個節點可能不足以滿足需求。流水線並行將模型分片到多個節點上,每個節點處理特定的連續模型層。
工作原理
- 每個 GPU 載入和處理一組不同的層。
- 傳送/接收操作:中間啟用在 GPU 之間傳輸,隨著計算的進行。
與張量並行相比,這降低了通訊開銷,因為資料傳輸在每個流水線階段發生一次。
流水線並行減少了跨 GPU 的記憶體限制,但不會像張量並行那樣固有地減少推理延遲。為了緩解吞吐量效率低下問題,vLLM 結合了先進的流水線排程,透過最佳化微批處理執行來確保所有 GPU 保持活動狀態。
結合張量並行和流水線並行
作為一般經驗法則,可以這樣考慮並行性的應用
- 當互連速度較慢時,跨節點使用流水線並行,節點內使用張量並行。
- 如果互連高效(例如,NVLink、InfiniBand),張量並行可以擴充套件到跨節點。
- 智慧地結合這兩種技術可以減少不必要的通訊開銷並最大限度地提高 GPU 利用率。
效能擴充套件和記憶體效應
雖然並行化的基本原理表明線性擴充套件,但在實踐中,由於記憶體效應,效能提升可能是超線性的。使用張量並行或流水線並行,吞吐量提升可能以不明顯的方式出現,這是由於 KV 快取的可用記憶體呈超線性增長。
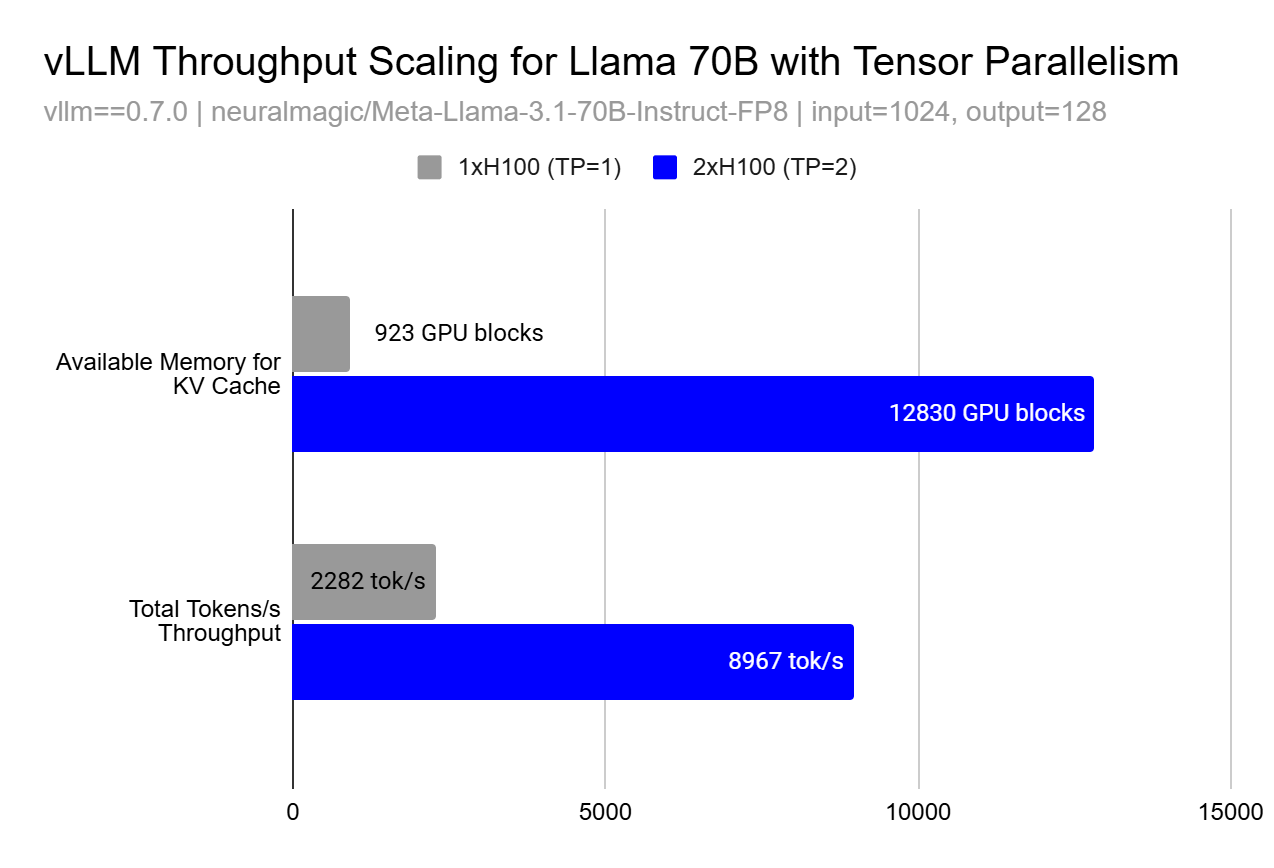
這種超線性擴充套件效應的發生是因為更大的快取允許更大的批次大小,以便並行處理更多請求和更好的記憶體區域性性,從而提高了 GPU 利用率,超過了僅僅增加更多計算資源所預期的效果。在上圖中,您可以看到在 TP=1 和 TP=2 之間,我們能夠將 KV 快取塊的數量增加 13.9 倍,這使我們能夠觀察到 3.9 倍的 token 吞吐量 - 遠高於我們期望的從使用 2 個 GPU 而不是 1 個 GPU 獲得的線性 2 倍提升。
進一步閱讀
對於有興趣深入瞭解影響 vLLM 設計的技術和系統的讀者
- Megatron-LM (Shoeybi 等人,2019) 介紹了大型語言模型中模型並行性的基礎技術
- Orca (Yu 等人,2022) 提出了一種使用迭代級排程的分散式服務的替代方法
- DeepSpeed 和 FasterTransformer 提供了關於最佳化 Transformer 推理的補充視角
結論
高效地服務大型模型需要結合張量並行、流水線並行和 效能最佳化,例如 分塊預填充。vLLM 透過利用這些技術實現可擴充套件的推理,同時確保跨不同硬體加速器的適應性。隨著我們不斷增強 vLLM,及時瞭解新的發展,例如 用於混合專家模型 (MoE) 的專家並行 和 擴充套件的量化支援,對於最佳化 AI 工作負載至關重要。
參加雙週辦公時間,瞭解更多關於 LLM 推理最佳化和 vLLM 的資訊!
致謝
感謝 Sangbin Cho (xAI) 提供了部分圖表。