AIBrix 簡介:vLLM 的可擴充套件、高性價比控制面板
今天,我們激動地宣佈 vllm-project/aibrix:一個由字節跳動開發的開箱即用的 vLLM Kubernetes 服務堆疊。AIBrix 於 2024 年初啟動,已成功部署以支援字節跳動的多個業務用例,證明了其在大規模部署中的可擴充套件性和有效性。
雖然 vLLM 使部署單個服務例項變得容易,但在大規模部署 vLLM 時,路由、自動擴縮和容錯方面會面臨獨特的挑戰。AIBrix 是一項開源計劃,旨在提供構建可擴充套件推理基礎設施的基本構建塊。它提供了一個雲原生解決方案,專門為部署、管理和擴充套件大型語言模型 (LLM) 推理而最佳化,並根據企業需求量身定製。
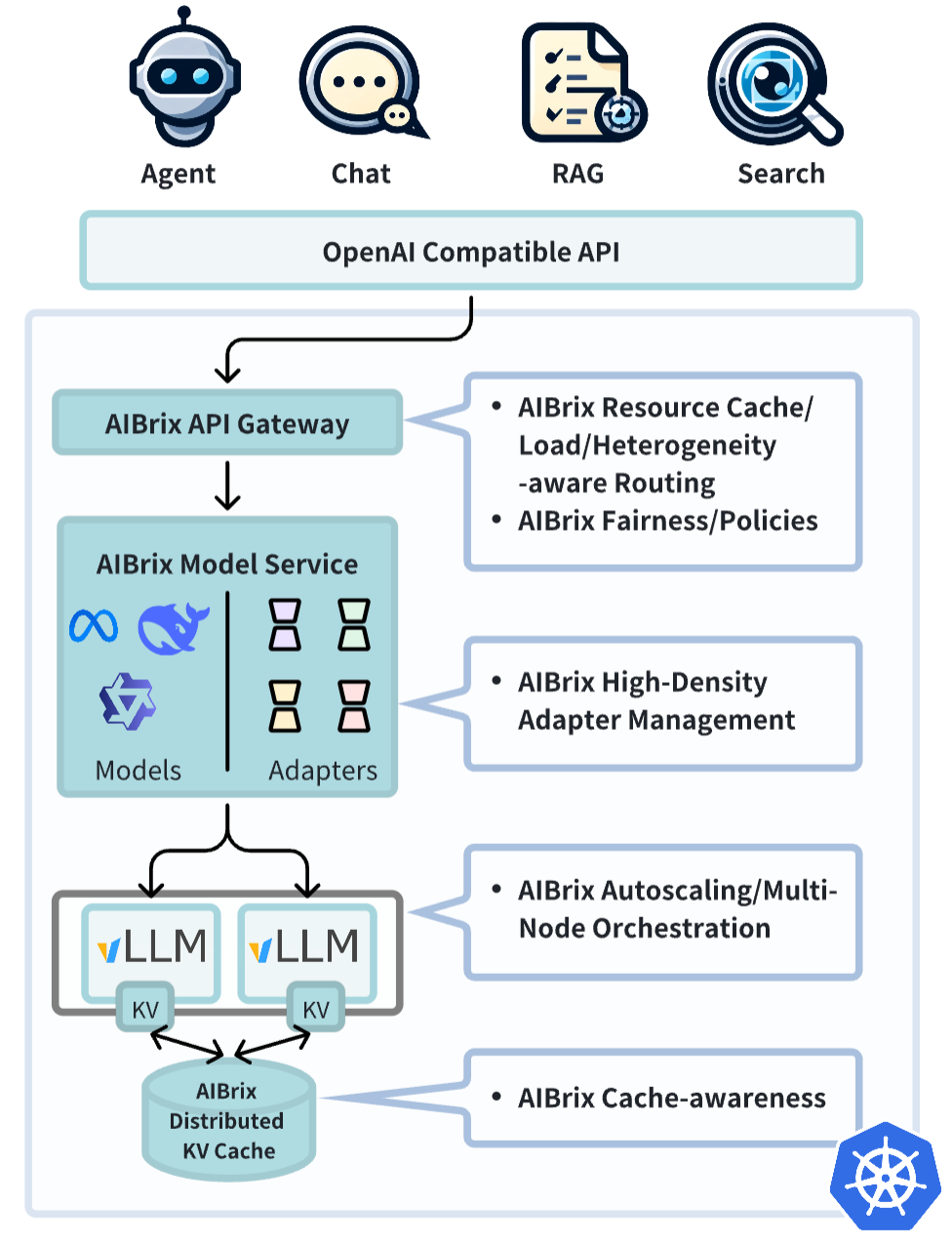
初始版本側重於以下關鍵功能
- 高密度 LoRA 管理:簡化了對模型輕量級、低秩自適應的支援。
- LLM 閘道器和路由:高效管理和引導跨多個模型和副本的流量。
- LLM 應用定製自動擴縮器:根據即時需求動態擴充套件推理資源。
- 統一 AI 執行時:一個通用的 Sidecar,支援指標標準化、模型下載和管理。
- 分散式推理:可擴充套件的架構,可處理跨多個節點的大型工作負載。
- 分散式 KV 快取:支援高容量、跨引擎的 KV 重用。
- 高性價比的異構服務:支援混合 GPU 推理,以在 SLO 保證下降低成本
- GPU 硬體故障檢測:主動檢測 GPU 硬體問題。
AIBrix 願景和行業合作
AIBrix 構建於系統和推理引擎協同設計的原則之上,主要側重於以雲原生方式在 Kubernetes 上構建可擴充套件的推理系統。展望未來,我們將繼續透過以下舉措探索協同設計方法:
- 擴充套件分散式 KV 快取以支援更廣泛的場景,包括 Prefill & Decode (P&D) 聚合、請求遷移和跨例項 KV 重用,從而提高記憶體效率和推理靈活性。
- 將傳統的資源管理原則(如 QoS、優先順序、公平性)應用於 LLM 推理,以實現請求級別的多租戶,從而確保高效的資源分配。
- 應用基於屋頂線模型的效能分析來最佳化計算效率,並在各種工作負載中提供強大的 SLO 保證的推理效能。
作為這項使命的一部分,我們積極與行業領導者合作,推動用於 LLM 服務的開放、雲原生解決方案。
“字節跳動一直是 Google 的卓越合作伙伴,透過 Working Group Serving 推動 Kubernetes 中 LLM 服務的標準化,併為 Gateway API Inference Extension 做出貢獻。我們很高興繼續合作開發共享元件,這些元件將支援 AIBrix 和大規模推理平臺” - Clayton Coleman,GKE 傑出工程師和推理主管
“vLLM 在全球範圍內經歷了爆炸式增長,成為 LLM 推理的基石。AIBrix 是一個有前景的專案,它建立在這個勢頭之上,提供強大的功能來生產化 vLLM,同時推動開源 LLM 推理的創新” - Robert Nishihara,Anyscale 聯合創始人兼 Ray 聯合創始人
探索更多
檢視 https://github.com/vllm-project/aibrix 上的程式碼倉庫,並深入閱讀我們的部落格文章,詳細瞭解 AIBrix 的架構和關鍵功能。為了更深入地瞭解,請查閱我們在設計理念和結果方面的白皮書,並按照文件開始部署和整合,並加入 vLLM Slack 的 aibrix 頻道 與開發者討論。
常見問題解答
AIBrix 與 vLLM 生產堆疊 有何不同?
-
AIBrix 是字節跳動開源釋出的版本,專注於大規模用例和雲原生解決方案。生產堆疊由 UChicago LMCache 團隊管理,是一個開放框架,歡迎所有人擴充套件、實驗和貢獻。您可以在此處檢視生產堆疊的路線圖。
-
AIBrix 是一個強大的 K8s 堆疊的例項化,並且已經在生產環境中運行了 6 個多月。生產堆疊從頭開始實施,專注於迭代每個構建塊,並結合社群的反饋和貢獻。
-
生產堆疊的期望優勢是利用內建的以 KV 快取為中心的最佳化(傳輸、混合、路由),這在長上下文和預填充密集型工作負載中尤其有利。在短期內,生產堆疊計劃利用 AIBrix 的元件。
AIBrix 是一個社群驅動的專案嗎?
當然。在 vLLM 專案組織下開源它的目的是為了與實踐者和研究人員展開協作。有許多增強領域正在計劃中,核心開發者相信未來是開源的!
AIBrix 與其他雲原生解決方案(如 KServe、KubeAI 等)有何不同?
AIBrix 提供與 vLLM 更原生的整合。透過僅考慮推理引擎進行設計,AIBrix 可以優先考慮快速模型載入、自動擴縮和 LoRA 管理等功能。