PTPC-FP8:在 AMD ROCm 上提升 vLLM 效能
TL;DR:AMD ROCm 上的 vLLM 現在具有更佳的 FP8 效能!
- 最新動態? vLLM (v0.7.3+) 在 AMD ROCm 上現已支援 PTPC-FP8 量化。
- 為何如此出色? 您將獲得與其他 FP8 方法相似的速度,但準確性卻更接近原始 (BF16) 模型質量。這是 ROCm 的最佳 FP8 選項。
- 如何使用
- 安裝 ROCm。
- 獲取最新的 vLLM (v0.7.3 或更高版本)。
- 執行 Hugging Face 模型時,新增
--quantization ptpc_fp8標誌。無需預量化!
什麼是 PTPC-FP8? 它是一種用於 FP8 權重和啟用量化的方法。它對啟用使用逐令牌縮放,對權重使用逐通道縮放,從而為您提供比傳統逐張量 FP8 更好的準確性。
簡介
大型語言模型 (LLM) 正在徹底改變我們與技術的互動方式,但它們巨大的計算需求可能成為障礙。如果您能在 AMD GPU 上更快速、更高效地執行這些強大的模型,而又不犧牲準確性,那會怎麼樣?現在您可以做到了!這篇文章介紹了一項突破:vLLM 中的 PTPC-FP8 量化,針對 AMD 的 ROCm 平臺進行了最佳化。準備好以 FP8 的速度獲得接近 BF16 的準確性,直接使用 Hugging Face 模型——無需預量化!我們將向您展示它的工作原理、基準測試其效能,並幫助您入門。
LLM 量化的挑戰與 PTPC-FP8 解決方案
執行大型語言模型計算成本很高。FP8(8 位浮點)透過減少記憶體佔用和加速矩陣乘法提供了一個引人注目的解決方案,但傳統的量化方法在 LLM 方面面臨著一個關鍵挑戰。
異常值問題
隨著 LLM 擴充套件到一定規模以上,它們會產生啟用異常值。這些異常大的值會帶來重大的量化挑戰
- 當使用逐張量量化時,大多數值獲得的有效精度位很少
- 異常值持續出現在不同令牌的特定通道中
- 雖然權重相對均勻且易於量化,但啟用並非如此
PTPC:一種以精度為目標的方案
PTPC-FP8(逐令牌啟用,逐通道權重 FP8)透過使用基於三個關鍵觀察結果的定製縮放因子來解決這一挑戰
- 異常值始終出現在相同的通道中
- 令牌內的通道幅度變化很大
- 同一通道在不同令牌之間的幅度保持相對穩定
這種洞察力催生了一種雙粒度方法
- 逐令牌啟用量化:每個輸入令牌都獲得其自身的縮放因子
- 逐通道權重量化:每個權重列都獲得唯一的縮放因子
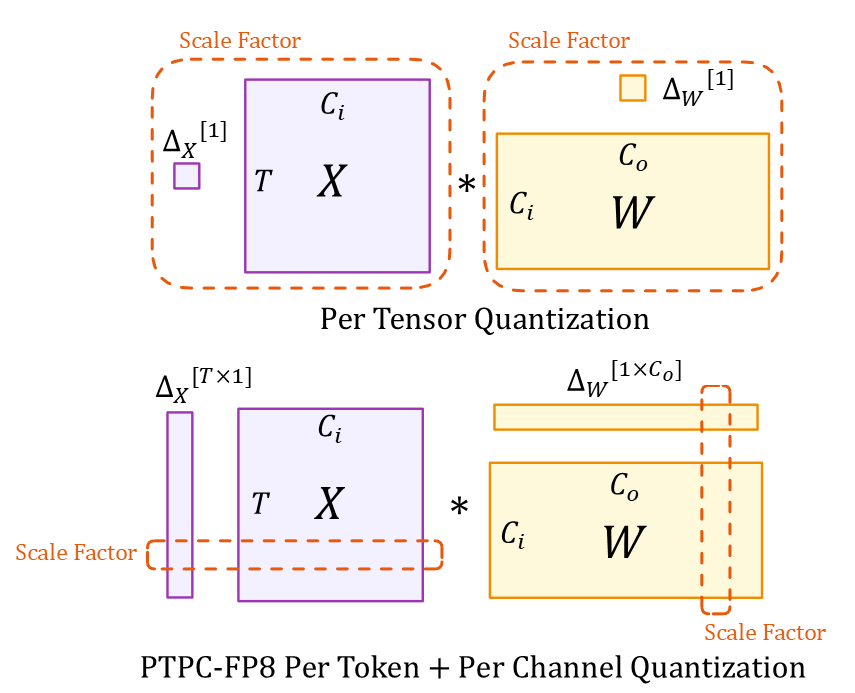
理解圖示
該圖示展示了兩種量化方法
張量維度(兩種方法)
- $X$:輸入啟用張量 ($T \times C_i$)
- $W$:權重張量 ($C_i \times C_o$)
- $T$:令牌序列長度
- $C_i/C_o$:輸入/輸出通道
- $*$:矩陣乘法
縮放因子
- 頂部(逐張量):整個張量的單個標量 $\Delta_X[1]$ 和 $\Delta_W[1]$
- 底部 (PTPC):向量 $\Delta_X[T \times 1]$,每個令牌一個縮放因子,以及 $\Delta_W[1 \times C_o]$,每個輸入通道一個縮放因子
這種細粒度的縮放方法使 PTPC-FP8 能夠在保持 8 位計算的速度和記憶體優勢的同時,實現接近 BF16 的準確性。
深入探討:PTPC-FP8 在 vLLM 中的工作原理(以及融合核心)
如果沒有適當的最佳化,PTPC-FP8 的細粒度縮放可能會降低速度。保持速度的關鍵是 AMD ROCm 對融合 FP8 行式縮放 GEMM 操作的實現。
挑戰:兩步法與融合方法
在沒有最佳化的情況下,使用逐令牌和逐通道縮放進行矩陣乘法將需要兩個代價高昂的步驟
# Naive 2-step approach:
output = torch._scaled_mm(input, weight) # Step 1: FP8 GEMM
output = output * token_scales * channel_scales # Step 2: Apply scaling factors
這會造成效能瓶頸
- 將大型中間結果寫入記憶體
- 讀取它們以進行縮放操作
- 浪費記憶體頻寬和計算週期
解決方案:融合
融合方法將矩陣乘法和縮放合併為單個硬體操作
# Optimized fused operation:
output = torch._scaled_mm(input, weight,
scale_a=token_scales,
scale_b=channel_scales)

為何這很重要
這種融合利用了 AMD GPU 的專用硬體(特別是在具有原生 FP8 支援的 MI300X 上)
- 記憶體效率:縮放在片上記憶體中進行,然後在寫入結果之前完成
- 計算效率:消除冗餘操作
- 效能提升:我們的測試表明,與樸素實現相比,速度提升高達 2.5 倍
融合操作使 PTPC-FP8 能夠實際用於真實世界的部署,消除了使用更細粒度縮放因子帶來的效能損失,同時保持了準確性優勢。
PTPC-FP8 基準測試:MI300X 上的速度和準確性
我們使用 vLLM 在 AMD MI300X GPU 上廣泛地對 PTPC-FP8 進行了基準測試(commit 4ea48fb35cf67d61a1c3f18e3981c362e1d8e26f)。以下是我們的發現
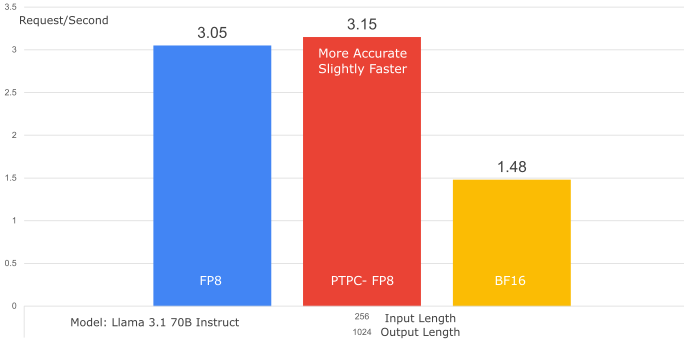
1. 吞吐量比較(PTPC-FP8 vs. 逐張量 FP8)
- 模型: Llama-3.1-70B-Instruct
- 資料集: SharedGPT
- GPU: 1x MI300X
- 結果: PTPC-FP8 實現了與逐張量 FP8 幾乎相同的吞吐量(甚至略微更好——提升了 1.01 倍)。這表明融合核心完全克服了 PTPC-FP8 更復雜縮放的潛在開銷。


2.1. 準確性:困惑度(越低越好)
- 模型: Llama-3.1-8B-Instruct
- 資料集: Wikitext
- 設定: 2× MI300X GPU,採用張量並行
理解困惑度:預測能力測試
將困惑度視為衡量模型在預測文字時有多“困惑”的指標。就像學生參加測驗一樣
- 較低的困惑度 = 更好的預測(模型自信地為正確的下一個詞分配高機率)
- 較高的困惑度 = 更多的不確定性(模型經常對接下來發生的事情感到驚訝)
困惑度的小幅增加(即使是 0.1)也可能表明模型質量的顯著下降,特別是對於經過廣泛最佳化的大型語言模型而言。
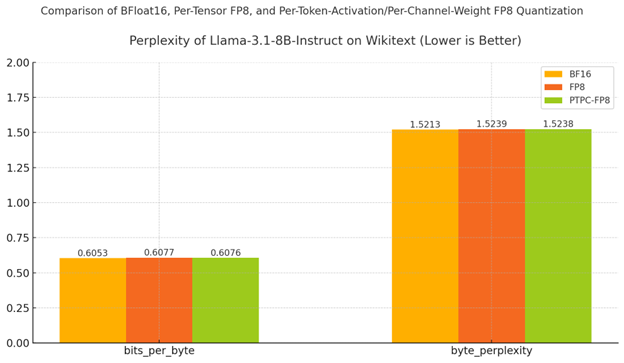
結果:PTPC-FP8 保持了類似 BF16 的質量
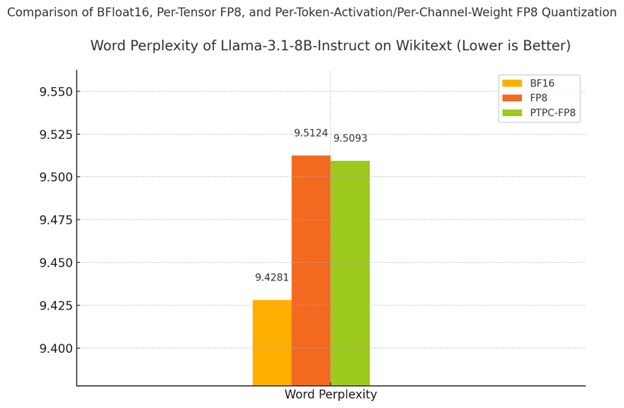
| 精度 | 單詞困惑度 | % 降級 |
|---|---|---|
| BF16(基線) | 9.4281 | - |
| PTPC-FP8 | 9.5093 | 0.86% |
| 標準 FP8 | 9.5124 | 0.89% |
如表格和圖表所示
- PTPC-FP8 優於標準 FP8 量化(9.5093 vs 9.5124)
- 與 BF16 的差距非常小——僅比全精度基線降低 0.86%
- 位元組級指標(bits_per_byte 和 byte_perplexity)顯示了相同的結果模式
為何這很重要: 雖然標準 FP8 已經提供了不錯的結果,但 PTPC-FP8 更低的困惑度表明它更好地保留了模型進行準確預測的能力。這對於複雜的推理和生成任務尤為重要,在這些任務中,小的質量下降可能會累積成輸出質量上的顯著差異。
2.2. GSM8K 上的準確性:數學推理測試**
什麼是 GSM8K 以及為何它很重要
GSM8K 測試模型解決小學數學應用題的能力——這是 LLM 最具挑戰性的任務之一。與簡單的文字預測不同,這些問題需要
- 多步驟推理
- 數值準確性
- 邏輯一致性
此基準測試有力地表明瞭量化是否保留了模型的推理能力。
理解結果
我們使用兩種方法測量了準確性
- 靈活提取:如果響應中的任何位置出現正確的數字,則接受答案
- 嚴格匹配:要求答案與預期格式完全一致
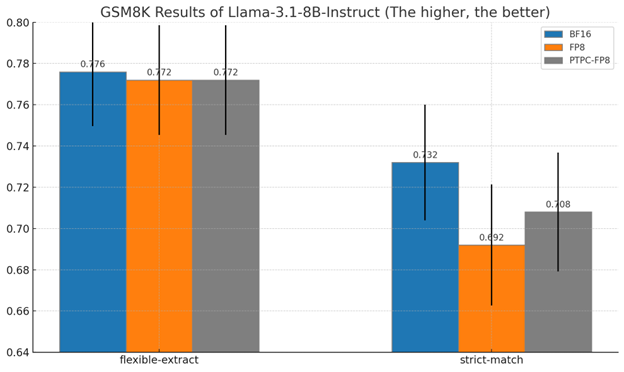
8B 模型結果概覽
| 方法 | 嚴格匹配準確率 | BF16 效能的百分比 |
|---|---|---|
| BF16(基線) | 73.2% | 100% |
| PTPC-FP8 | 70.8% | 96.7% |
| 標準 FP8 | 69.2% | 94.5% |
70B 模型結果
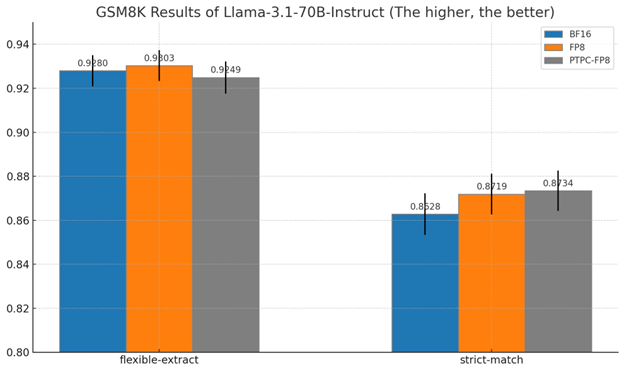
對於更大的 70B 模型
- PTPC-FP8 實現了 87.3% 的嚴格匹配準確率
- 這實際上略好於 BF16 的 86.3%
- 兩者在嚴格匹配條件下均優於標準 FP8
為何這些結果很重要
-
推理能力的保留:數學推理通常是量化後第一個退化的能力
-
PTPC-FP8 在兩種模型尺寸上始終優於標準 FP8
-
接近 BF16 的質量,同時顯著降低記憶體並提高效能
-
擴充套件優勢:量化方法之間的效能差距隨著模型尺寸的增加而縮小,這表明 PTPC-FP8 對於大型模型尤其有價值
這些結果表明,PTPC-FP8 量化在提供 8 位精度的速度和效率優勢的同時,保留了模型執行復雜推理任務的能力。
開始入門
- 安裝 ROCm: 確保您擁有最新版本。
- 立即克隆最新的 vLLM commit!設定並開始探索這項新功能!
$ git clone https://github.com/vllm-project/vllm.git
$ cd vllm
$ DOCKER_BUILDKIT=1 docker build -f Dockerfile.rocm -t vllm-rocm .
$ docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v <path/to/model>:/app/model \
vllm-rocm \
bash
- 使用
--quantization ptpc_fp8標誌執行 vLLM
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve <your-model> --max-seq-len-to-capture 16384 --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024 --quantization ptpc_fp8
(將 <your-model> 替換為任何 hugging face 模型;它將自動即時量化權重。)
結論:準確性與速度的最佳平衡點
AMD ROCm 上 vLLM 中的 PTPC-FP8 量化代表著在普及強大 LLM 方面邁出了重要一步。透過使接近 BF16 的準確性以 FP8 的速度實現,我們正在打破限制更廣泛應用的計算壁壘。這項進步使更廣泛的社群——從個人研究人員到資源受限的組織——能夠在可訪問的 AMD 硬體上利用大型語言模型的強大功能。我們邀請您探索 PTPC-FP8,分享您的經驗,為 vLLM 專案做出貢獻,並幫助我們構建一個人人都能獲得高效且準確的 AI 的未來。
附錄
lm-evaluation-harness 命令
# Unquantized (Bfloat16)
MODEL=meta-llama/Llama-3.1-8B-Instruct
HIP_VISIBLE_DEVICES=0,1 lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,tensor_parallel_size=2,kv_cache_dtype=auto,max_model_len=2048,gpu_memory_utilization=0.6 \
--tasks wikitext --batch_size 16
# Per-Tensor FP8 Quantization
MODEL=meta-llama/Llama-3.1-8B-Instruct
HIP_VISIBLE_DEVICES=0,1 lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,tensor_parallel_size=2,quantization=fp8,kv_cache_dtype=fp8_e4m3,max_model_len=2048,gpu_memory_utilization=0.6 \
--tasks wikitext --batch_size 16
# Per-Token-Activation Per-Channel-Weight FP8 Quantization
MODEL=meta-llama/Llama-3.1-8B-Instruct
HIP_VISIBLE_DEVICES=0,1 lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,tensor_parallel_size=2,quantization=ptpc_fp8,kv_cache_dtype=fp8_e4m3,max_model_len=2048,gpu_memory_utilization=0.6 \
--tasks wikitext --batch_size 16
lm-evaluation-harness 命令(8B 模型 - 針對 70B 進行調整)
# FP8 (Per-Tensor)
MODEL=/app/model/Llama-3.1-8B-Instruct/ # Or Llama-3.1-70B-Instruct
lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,quantization=fp8,kv_cache_dtype=fp8_e4m3 \
--tasks gsm8k --num_fewshot 5 --batch_size auto --limit 250
# PTPC FP8
MODEL=/app/model/Llama-3.1-8B-Instruct/ # Or Llama-3.1-70B-Instruct
lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,quantization=ptpc_fp8,kv_cache_dtype=fp8_e4m3 \
--tasks gsm8k --num_fewshot 5 --batch_size auto --limit 250
# BF16
MODEL=/app/model/Llama-3.1-8B-Instruct/ # Or Llama-3.1-70B-Instruct
lm_eval \
--model vllm \
--model_args pretrained=$MODEL,add_bos_token=True,kv_cache_dtype=auto \
--tasks gsm8k --num_fewshot 5 --batch_size auto --limit 250