torch.compile 簡介及其在 vLLM 中的工作原理
說明
這篇部落格源自我們每兩週舉辦一次的 vLLM office hours,這是一個由 Red Hat 與 vLLM 專案提交者及加州大學伯克利分校團隊共同主持的社群論壇。每次會議都會涵蓋最新動態、特邀嘉賓的深度分享以及開放問答環節。歡迎每隔一個週四美國東部時間下午 2:00 / 太平洋時間上午 11:00 在 Google Meet 上加入我們,會後可以在我們的 YouTube 播放列表上獲取錄影和幻燈片。
引言
如今,要實現大型語言模型(LLM)的快速推理,需要在多樣化的硬體、工作負載和規模下儘可能高效地執行模型。高效執行需要高度最佳化的運算元(kernel),而這些運算元通常需要針對不同的模型和平臺進行手動調優。torch.compile 是 PyTorch 的即時(JIT)編譯器,它可以自動生成最佳化的運算元,從而顯著加快 PyTorch 程式碼的執行速度,而無需開發者為所有支援的硬體平臺手動最佳化運算元。
對於 vLLM 這個用於可移植和高效 LLM 推理的事實標準開源推理引擎來說,torch.compile 不僅僅是一個性能增強器。它是一個核心元件,將最佳化的責任從模型開發者轉移到了編譯器。最佳化是在編譯期間應用的,而不是要求修改模型定義,從而實現了更清晰的關注點分離,並獲得了最大的效能。在這篇文章中,我們將詳細介紹 torch.compile 的工作原理、它如何整合到 vLLM 中,以及 vLLM 如何使用自定義編譯器通道(pass)來最大化效能。我們還將討論 vLLM 中 torch.compile 整合的正在進行和未來的工作,以進一步提高其可用性和效能。
什麼是 torch.compile?
torch.compile 讓您能以最小的努力最佳化 PyTorch 程式碼:使用 torch.compile 非常簡單,就像給一個函式或 torch.nn.Module 新增一個裝飾器一樣。torch.compile 會自動將張量操作捕獲到一個計算圖中,然後為該圖生成最佳化的程式碼。
在下面的例子中,torch.compile 為函式 fn 中所有的逐點(pointwise)操作生成了一個單一的融合運算元。它會即時捕獲並編譯該函式,如果任何捕獲條件(例如輸入形狀)發生變化,可能會重新編譯。

圖 1:torch.compile 是 PyTorch 程式碼的 JIT 編譯器。你可以用 torch.compile 包裝函式、nn.Module 和其他可呼叫物件。
有多種使用 torch.compile 的方式。你可以將它用作運算元生成器(如圖 1 所示),我們編譯一個函式。但你也可以將 torch.compile 應用於你的整個 nn.Module 模型或其子模組。根據模型的結構和你的需求(例如編譯時間),我們建議在不同的地方應用 torch.compile。
為什麼要使用 torch.compile?
最佳化模型的一種方法是編寫自定義的 CPU/CUDA 操作,這些操作執行與模型中相同的運算但速度更快。為每個模型編寫自定義運算元非常耗時,並且需要對效能和硬體有深入的理解。torch.compile 幾乎不需要額外的工程努力就能讓你達到接近峰值效能。例如,PyTorch 的開源 TorchBench 基準測試套件顯示,在 80 多個模型上,幾何平均速度提升了 1.8-2 倍。
圖 2:torch.compile 為您提供了快速的基線效能,從而節省了您調優模型效能的開發時間。
torch.compile 的工作原理
torch.compile 流水線包括兩個主要階段:前端(TorchDynamo)和後端(TorchInductor)。我們將做一個簡要概述,更多詳情請參閱官方 PyTorch 2 論文。
1. 前端(TorchDynamo):圖捕獲
torch.compile 的前端是一個自定義的位元組碼直譯器。它追蹤任意的 Python 函式,並提取出僅包含張量操作的線性 torch.fx 圖。torch.compile 的一個關鍵特性是圖斷點(graph breaks),這使其能夠很好地覆蓋所有 Python 程式碼。每當 torch.compile 遇到它不支援的操作時,它不會報錯。相反,它會結束當前正在追蹤的圖,執行該操作,然後開始追蹤一個新的圖。torch.compile 將每個追蹤到的圖傳送到後端進行最佳化。
在下面的程式碼示例中,torch.save 是一個不支援的操作:torch.compile 不知道如何執行磁碟 I/O。將 torch.compile 應用於函式 f,相當於將 torch.compile 分別應用於呼叫 torch.save 之前的計算區域和呼叫 torch.save 之後的區域。
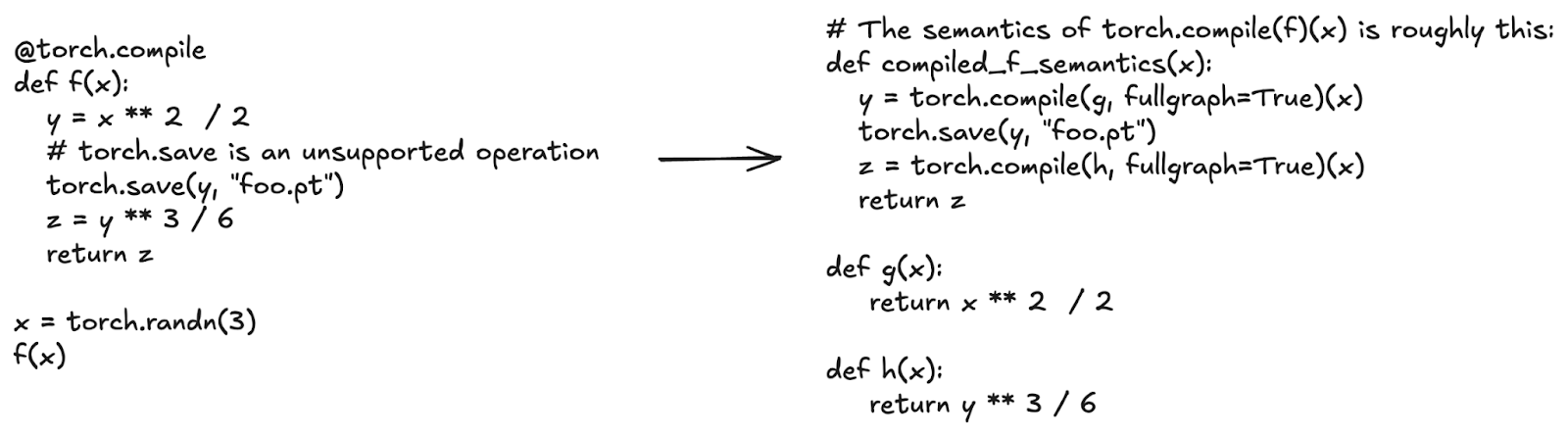
圖 3:torch.compile 捕獲張量操作的線性圖,並繞過像 torch.save 這樣的不支援的操作。
2. 後端(TorchInductor):最佳化與運算元生成
torch.compile 的後端接收來自前端的圖,並透過圖最佳化通道以及降級(lowering)到最佳化的 C++、Triton 或其他運算元來進行最佳化。它能夠:
- 融合逐點和歸約(reduction)操作
- 自動調優運算元配置,如塊大小
- 為矩陣乘法(matmul)選擇不同的後端(cuBLAS, Triton, CUTLASS),並執行前序(prologue)和後序(epilogue)融合
- 使用 CUDA Graphs 高效地快取和重放運算元啟動
CUDA Graphs 是一個例子,說明了擁有一個編譯器是多麼有幫助。CUDA Graphs 減少了啟動開銷,但要求你的程式碼滿足某些假設(例如,它必須只使用 CUDA 操作,輸入張量必須有靜態記憶體地址)。torch.compile 能夠自動在不支援的操作處分割圖,建立更小的、可以安全使用 CUDA Graph 的圖,並自動管理靜態輸入緩衝區。
vLLM 整合
vLLM V1 預設集成了 torch.compile,用於線上和離線推理。你可以使用 -O0 或 --enforce-eager 來停用它,但在大多數用例中,保持開啟狀態會帶來效能優勢。更多詳情請參見文件。
編譯快取
vLLM 在冷啟動期間編譯模型,並將產物(FX 圖、Triton 運算元)儲存在一個快取目錄中(預設為 ~/.cache/vllm/torch_compile_cache)。在熱啟動時,會從快取中檢索這些產物。你可以透過 VLLM_DISABLE_COMPILE_CACHE=1 或刪除快取目錄來停用快取。
編譯的產物和快取可以在具有相同環境的機器之間重用。如果你有自動擴充套件的用例,請確保只生成一次快取目錄並在例項之間共享它。
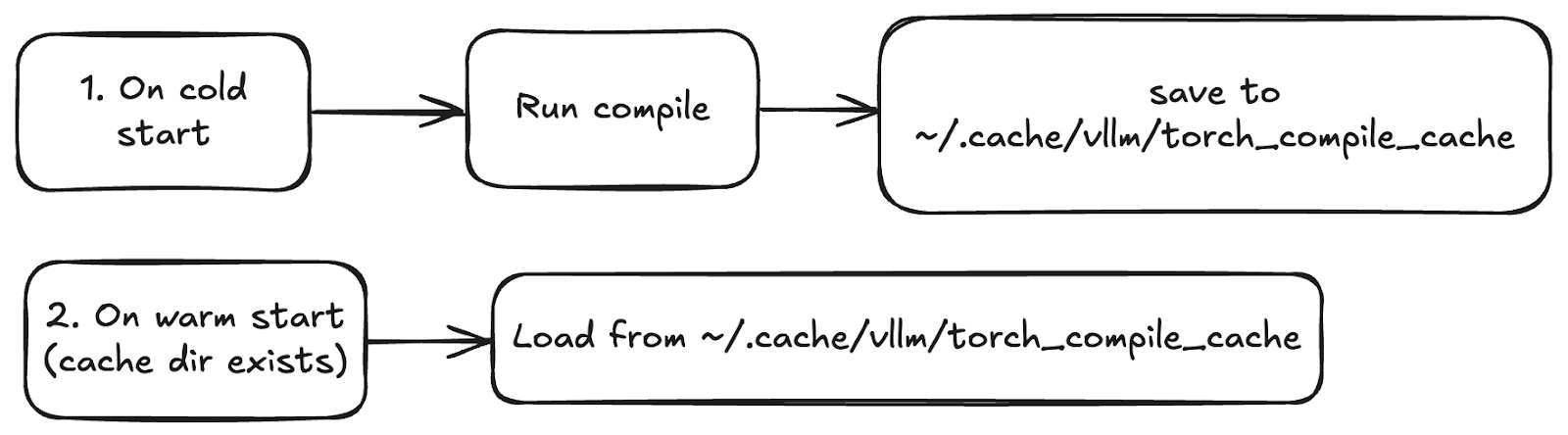
圖 4:編譯產物在冷啟動後被快取,並且可以在機器之間重用,以確保在正確設定下實現快速、一致的啟動。
動態批處理大小和特化
預設情況下,vLLM 編譯一個具有動態批處理大小的圖,該圖支援所有可能的批處理大小。這意味著一個產物可以服務於可變的輸入大小。然而,針對已知的批處理大小(如 1、2 或 4)進行特化可以帶來效能提升。
在你的配置中使用 compile_sizes: [1, 2, 4] 來觸發這種特化。在底層,這會告訴 torch.compile 針對這些靜態大小進行編譯,並可能執行更多的自動調優來選擇最佳的運算元。

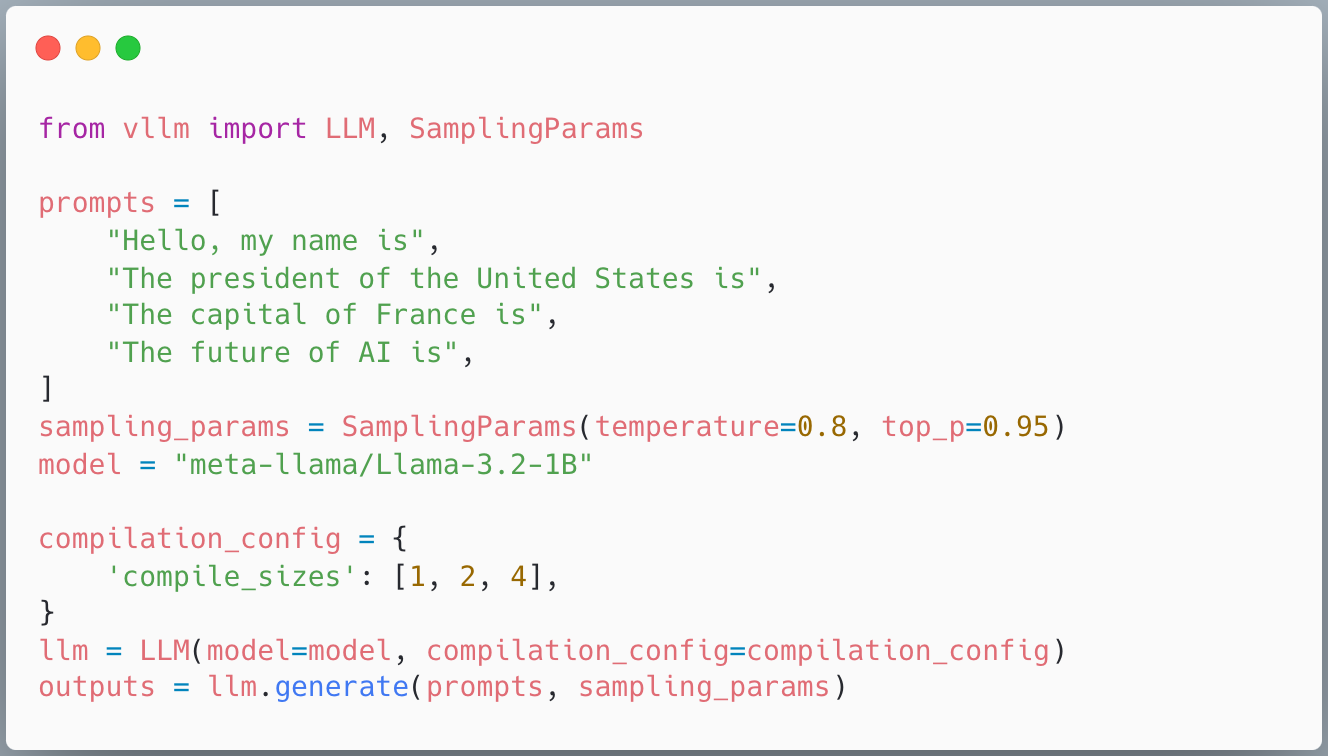
圖 5:如何指定針對特定批處理大小進行特化編譯。
分段 CUDA Graphs
並非所有操作都與 CUDA Graphs 相容;例如,級聯注意力(cascade attention)就不相容。vLLM 透過將捕獲的圖分解為 CUDA Graph 安全和不安全的部分,並分別執行它們來解決這個問題。這使我們既能獲得 CUDA Graphs 的效能優勢,又不會損失正確性。
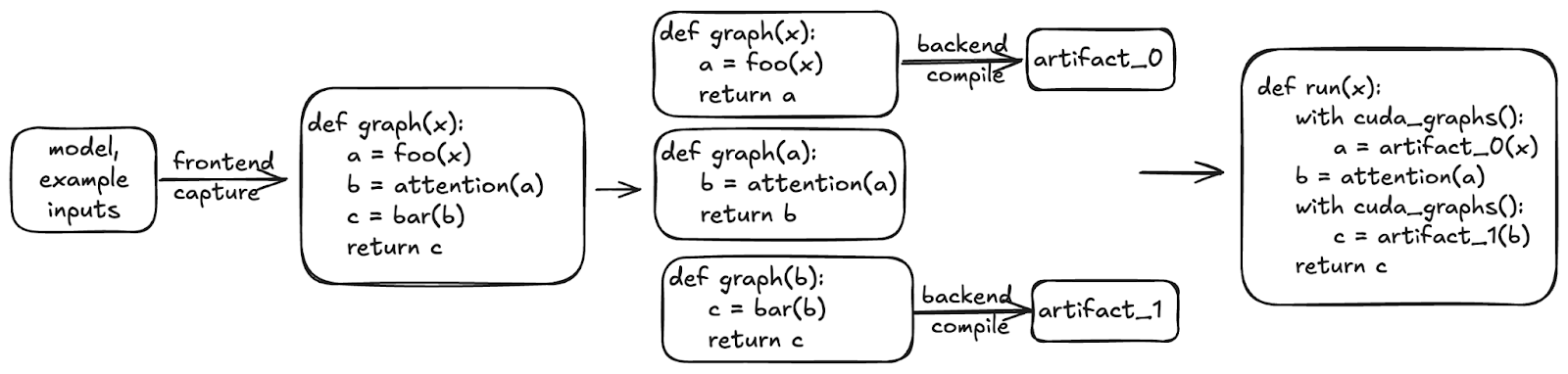
圖 6:vLLM 中的分段 CUDA Graphs 捕獲並重放支援的 GPU 運算元序列以實現低開銷執行,同時跳過不支援的操作,如級聯注意力。
vLLM 中的自定義編譯器通道
雖然 torch.compile 包含許多內建最佳化,但 vLLM 添加了自定義編譯器通道,應用額外的最佳化以進一步提高效能。
為何需要自定義通道?
模型作者編寫宣告式的、模組化的程式碼,側重於正確性並使用清晰的抽象,將更高級別的操作分離到不同的子模組中,並按層進行分組。然而,要達到峰值效能,通常需要打破這些抽象,比如跨子模組和層融合操作。vLLM 的自定義通道重寫 torch.fx 圖,而不是重寫模型本身。
這些通道:
- 融合記憶體密集型的自定義操作,如啟用函式和量化
- 新增 Inductor 中沒有的最佳化(例如移除多餘的無操作)
示例:SiLU + 量化融合
在量化的 MLP 中,一個常見的模式是 SiLU 啟用函式後接一個量化的下投影線性層。量化的線性層包括對輸入進行量化操作,然後是量化的矩陣乘法。單獨來看,SiLU 和量化操作速度慢且受記憶體限制。利用 Inductor 的模式匹配器工具,vLLM 中的 ActivationFusionPass 自定義通道將它們替換為單個融合運算元,吞吐量提升高達 8%。
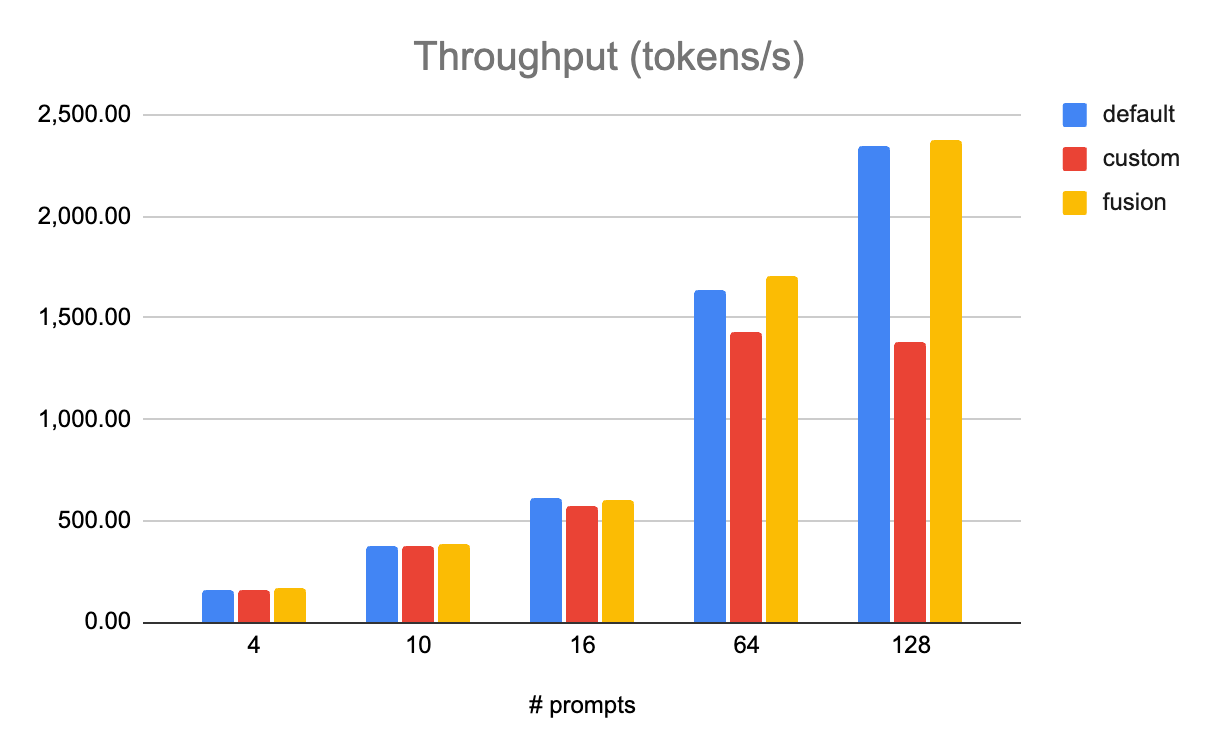
圖 7:在 8x AMD MI300s 上對 Llama 3.1 405B 模型進行 FP8 量化測試,融合運算元(`fusion`,黃色)的效能優於 `default`(使用 torch ops 實現 RMSNorm 和 SiLU,以及自定義 FP8 量化運算元)和 `custom`(未融合的自定義運算元)。
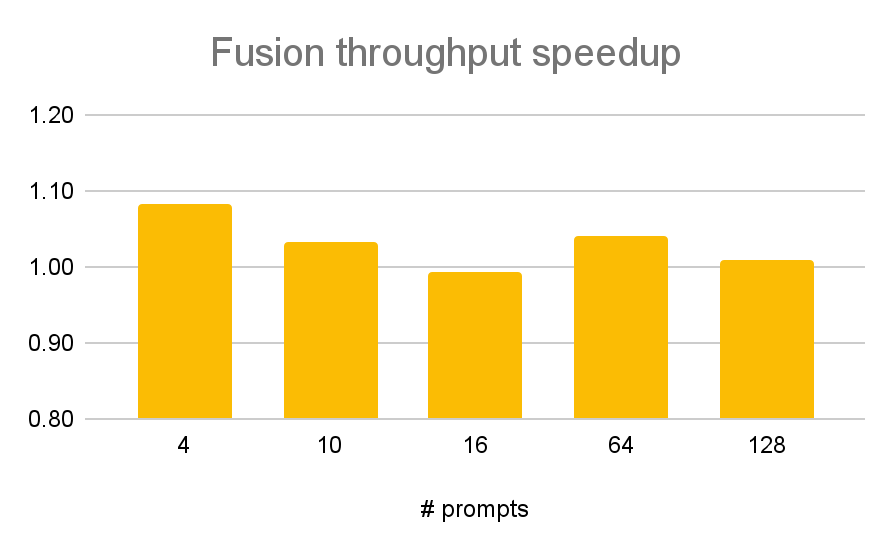
圖 8:詳細的吞吐量加速對比,比較了上述的 `fusion` 和 `default` 兩種模式。如果透過融合完全消除了所有量化開銷(8%),理論上吞吐量的最大提升將是 8%,我們可以看到在某些情況下確實達到了這個提升。
說明
自從那次 office hours 之後,我們增加了一個使用 torch 操作實現量化的方法,該方法(經 Inductor 編譯後)比自定義的 CUDA/ROCm 運算元更快。因為 Inductor 可以自動將這些 torch 操作與 SiLU 的 torch 操作融合,所以在某些情況下,SiLU+量化和 RMSNorm+量化通道現在已經過時了。然而,任何涉及自定義操作(注意力、集合通訊、亞位元組量化)的融合仍然需要自定義通道。我們在這裡展示 SiLU+量化的例子是為了與 office hours 的幻燈片和錄影保持一致,但其他融合通道的工作方式非常相似。
示例:序列並行 + 非同步張量並行
當使用張量並行(TP)時,線性層會對權重進行分片並計算不完整的矩陣乘法結果,這些結果需要在 GPU 之間同步。如果對計算和通訊部分使用獨立的運算元,我們會因為 GPU 在等待通訊結果的網路延遲時處於空閒狀態而產生通訊開銷。
相反,我們可以透過使用融合了 GEMM 和集合通訊的運算元來重疊計算和通訊。這類運算元的一個例子是 GEMM+reduce_scatter 和 all_gather+GEMM 運算元。為了利用這些運算元,我們需要將 all_reduce 集合操作分解為 reduce_scatter 和 all_gather,同時將 all_gather 推遲到 layernorm 之後,以便它能與接下來的 GEMM 融合。
如果我們要將這種最佳化實現在模型定義中,我們就必須修改 vLLM 支援的每一個模型(有數百個!)。這將是侵入性的,會破壞抽象,增加開發者摩擦,並且很可能一開始就不會被 vLLM 接受。相反,透過在 torch.compile 中實現該最佳化,它被限制在僅僅 2 個自定義通道中,並且可以透過命令列標誌開啟,為 vLLM 支援的所有模型提供更好的效能。
說明
這項最佳化由社群成員 @cascade812 完全實現,我們感謝他做出的卓越貢獻。關於非同步 TP 的更多資訊可以在 PyTorch 部落格上找到。
當前和即將推出的通道
今日可用
- 融合通道
- RMSNorm + 量化 (FP8) 融合
- SiLU-Mul + 量化 (FP8) 融合
- Attention + 量化 (FP8) 融合(最高提升 7%)
- AllReduce + RMSNorm 融合(最高提升 15%)
- AllReduce + RMSNorm + 量化 (FP8) 融合(最高提升 8%)
- AllReduce + RMSNorm + 量化 (FP4) 融合(最高提升 10%)
- 序列並行 & 非同步 TP(最高提升 10%)
- 其他通道
- 無操作消除:消除或簡化冗餘的 reshape 操作
- 修復函式化:手動替換 auto_functionalized 操作,以避免冗餘複製和記憶體使用
即將推出
通道可以透過 PostGradPassManager、命令列(--compilation-config)或在離線模式下指定一個配置物件來新增。這允許 vLLM 使用者執行其用例所需的自定義圖轉換(運算元替換或其他),而無需修改 vLLM 原始碼。
未來工作
我們在 vLLM-torch.compile 整合方面已經取得了很大進展。以下是我們未來六個月將重點關注的一些領域。
提高穩定性
vLLM-torch.compile 整合使用了許多私有的(以下劃線開頭)torch.compile API,並依賴於不穩定的實現細節。我們這樣做是因為使用公共的 torch.compile API 不足以滿足我們的需求——vLLM 需要快速的服務效能,並且在模型服務期間不能有重新編譯。這導致了一些問題,比如奇怪的快取問題,或者需要為某些模型停用 vLLM 的 torch.compile 快取。PyTorch 編譯器團隊正在努力將 vLLM(以及通用推理)相關的功能從 vLLM 上游貢獻到 torch.compile,並將 vLLM 遷移到使用更穩定的 API。其中許多功能已經存在於 torch 2.8 中,該版本將很快登陸 vLLM!
改善啟動時間
我們瞭解到,對於 vLLM torch.compile 和 CUDAGraphs 來說,啟動時間是一個巨大的痛點,尤其是在自動擴充套件的場景中,需要根據需求動態啟動新機器。我們計劃顯著減少 vLLM 的冷啟動(首次)和熱啟動(第二次及以後)時間,特別是與 Dynamo 和 Inductor 編譯相關的時間。請關注 GitHub 上的 startup-ux 標籤或加入 vLLM Slack 上的 #feat-startup-ux 頻道以獲取最新進展!
一個重要的使用者體驗改進是計劃中的對 -O 命令列標誌的改造。透過在 vLLM 命令列中指定 -O<n>(其中 n 是 0-3 之間的整數),使用者將能更輕鬆地直接控制在啟動時間和效能之間進行權衡。其中 -O0 幾乎不執行任何最佳化,以最快速度啟動,而 -O3 則會花費更長的時間,但能提供最佳效能。
自定義通道改進
我們計劃對自定義通道機制進行一些廣泛的改進,以增加其靈活性並使其更易於編寫,同時提高應用最佳化後的最終效能。
- 編譯多個動態形狀的
torch.fx圖。這將使我們能夠根據批次的大小來特化前向傳遞圖,而無需為每個靜態大小單獨編譯。更多資訊請參見 RFC。 - 啟用對自定義操作的 torch 實現的匹配。目前,需要啟用自定義操作(rms_norm、quant 等)才能進行模式匹配和融合,但可能有些自定義操作最終沒有被融合(特別是對於每層發生 4 次的量化)。這些操作比它們的 torch 等價物慢,從而降低了融合帶來的好處。我們有一個工作原型,可以對自定義操作的 torch 實現進行模式匹配,有望帶來進一步的效能提升。
實驗性的 torch.compile 後端整合
我們還在探索一個實驗性的 MPK/Mirage 編譯器整合。MPK 是一個精度排程的大運算元(megakernel)編譯器,這意味著它為整個模型的前向傳遞生成一個單一的運算元,與 CUDA Graphs 相比,這可以進一步減少 CPU 開銷並消除運算元啟動開銷。關於提議的整合的更多資訊請參見 RFC。
其他效能改進
vLLM 的 torch.compile 整合的目標是提供良好的基線效能,以避免需要編寫和維護大量的自定義運算元。我們將繼續維護和提高效能。正在進行的工作的一些亮點包括:
- 改進的 FlexAttention 支援。FlexAttention 是一個 API,它允許使用不同的注意力變體,而無需為每種變體編寫自定義的注意力運算元。在底層,它使用 torch.compile 來生成一個自定義的 Triton 模板。
- 對 Flash Attention v2 和 FlashInfer 的完整 CUDA Graphs 支援。完整的 CUDAGraphs 比分段 CUDA Graphs 的開銷更小,應該能在那些高開銷的場景中提高效能。
結論
torch.compile 提供了一種強大且易於使用的方式來加速 PyTorch 模型。在 vLLM 中,它是推理流水線的核心部分。結合快取、動態形狀支援、CUDA Graphs 和自定義通道,它實現了在任何環境下的高效、可擴充套件的 LLM 服務。
隨著編譯器堆疊的成熟和對新硬體支援的擴充套件,torch.compile 和 vLLM 將繼續推動推理效能的邊界——同時保持模型開發的整潔和模組化。閱讀更多關於 torch.compile 的資訊,請參閱 PyTorch 文件和 vLLM 文件,並加入 vLLM Slack 上的 #sig-torch-compile 頻道來提問、分享反饋,並貢獻您自己的自定義通道!