在 AMD MI300X 上部署 LLM:最佳實踐
TL;DR(太長不看版): vLLM 在 AMD MI300X 上釋放了驚人的效能,對於 Llama 3.1 405B 模型,吞吐量比 Text Generation Inference (TGI) 高 1.5 倍,首個令牌生成時間 (TTFT) 快 1.7 倍。對於 Llama 3.1 70B 模型,吞吐量比 TGI 高 1.8 倍,TTFT 快 5.1 倍。本指南探討了 8 個關鍵的 vLLM 設定,以最大限度地提高效率,向您展示如何利用 AMD 上的開源 LLM 推理能力。如果您只想檢視最佳引數,請跳轉至快速入門指南。
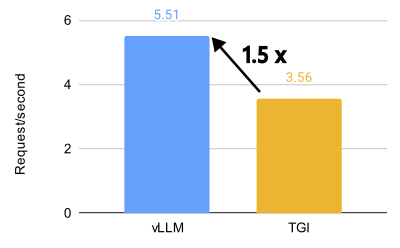
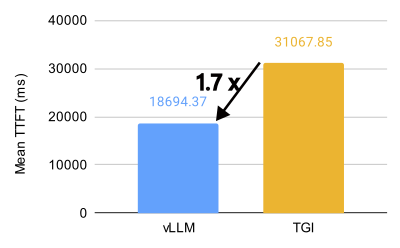
vLLM 與 TGI 在 8 個 MI300X 上對 Llama 3.1 405B 模型的效能比較(BF16,32 QPS)。
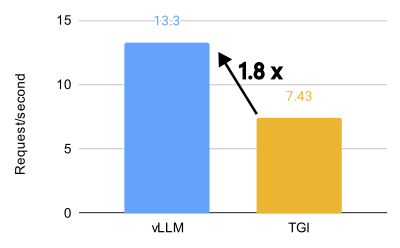
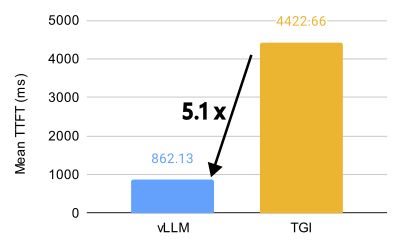
vLLM 與 TGI 在 8 個 MI300X 上對 Llama 3.1 70B 模型的效能比較(BF16,32 QPS)。
簡介
Meta 最近宣佈,他們正在 AMD MI300X GPU 上執行 100% 的即時 Llama 3.1 405B 模型流量,展示了 AMD 的 ROCm 平臺在大型語言模型 (LLM) 推理方面的強大效能和就緒狀態。這一令人振奮的訊息恰逢 ROCm 6.2 釋出,新版本顯著改進了對 vLLM 的支援,使得利用 AMD GPU 的強大功能進行 LLM 推理變得比以往任何時候都更容易。
ROCm 是 AMD 對 CUDA 的回應,可能對某些人來說不太熟悉,但它正迅速成熟為一個強大且高效能的替代方案。藉助 vLLM,利用這種強大功能比以往任何時候都更容易。我們將向您展示如何操作。
vLLM 與 TGI 對比
vLLM 在 AMD MI300X 上釋放了驚人的效能,對於 Llama 3.1 405B 模型,吞吐量比 Text Generation Inference (TGI) 高 1.5 倍,首個令牌生成時間 (TTFT) 快 1.7 倍。對於 Llama 3.1 70B 模型,吞吐量比 TGI 高 1.8 倍,TTFT 快 5.1 倍。
在 Llama 3.1 405B 模型上,在各種每秒查詢數 (QPS) 場景中,vLLM 在首個令牌生成時間 (TTFT) 和吞吐量方面都表現出明顯優於 TGI 的效能。對於 TTFT,在最佳化的配置中,16 QPS 下,vLLM 的平均響應時間比 TGI 快約 3.8 倍。在吞吐量方面,vLLM 始終優於 TGI,在最佳化的設定中,在 1000 QPS 下,ShareGPT 資料集上的最高吞吐量為 5.76 個請求/秒,而 TGI 為 3.55 個請求/秒。
即使在預設配置中,vLLM 也顯示出優於 TGI 的效能。例如,在 16 QPS 下,vLLM 的預設配置實現了 4.05 個請求/秒的吞吐量,而 TGI 為 2.58 個請求/秒。這種效能優勢在不同的 QPS 水平上都得以保持,突顯了 vLLM 在處理大型語言模型推理任務方面的效率。
.png)
.png)
vLLM 與 TGI 在 8 個 MI300X 上對 Llama 3.1 405B 模型的效能比較(BF16,QPS 16、32、1000;命令參見附錄)。
如何以最佳效能執行 vLLM
關鍵設定和配置
我們已經廣泛測試了各種 vLLM 設定,以確定 MI300X 的最佳配置。以下是我們所瞭解到的
- 分塊預填充 (Chunked Prefill):經驗法則是,在大多數情況下,在 MI300X 上停用它以獲得更好的效能。
- 多步排程 (Multi-Step Scheduling):使用多步排程可以顯著提高 GPU 利用率和整體效能。將
--num-scheduler-steps設定為 10 到 15 之間的值,以最佳化 GPU 利用率和效能。 - 字首快取 (Prefix Caching):在特定場景中,將字首快取與分塊預填充相結合可以提高效能。但是,如果使用者請求的字首快取命中率較低,則可能建議停用分塊預填充和字首快取。
- 圖捕獲 (Graph Capture):當處理支援長上下文長度的模型時,將
--max-seq-len-to-capture設定為 16384。但是,請注意,增加此值並不總是保證效能提升,有時甚至可能由於次優的 bucket 大小而導致效能下降。 - AMD 特定最佳化:停用 NUMA 平衡和調整
NCCL_MIN_NCHANNELS可以進一步提高效能。 - KV 快取資料型別:為了獲得最佳效能,請使用預設的 KV 快取資料型別,它會自動匹配模型的資料型別。
- 張量並行 (Tensor Parallelism):為了最佳化吞吐量,請使用可容納模型權重和上下文的最小張量並行度 (TP),並執行多個 vLLM 例項。為了最佳化延遲,請將 TP 設定為節點中 GPU 的數量。
- 最大序列數:為了最佳化效能,請根據 GPU 的記憶體和計算資源將
--max-num-seqs增加到 512 或更高。這可以顯著提高資源利用率和吞吐量,特別是對於處理較短輸入和輸出的模型。 - 使用 CK Flash Attention:CK Flash Attention 實現比 triton 實現快得多。
詳細分析和實驗
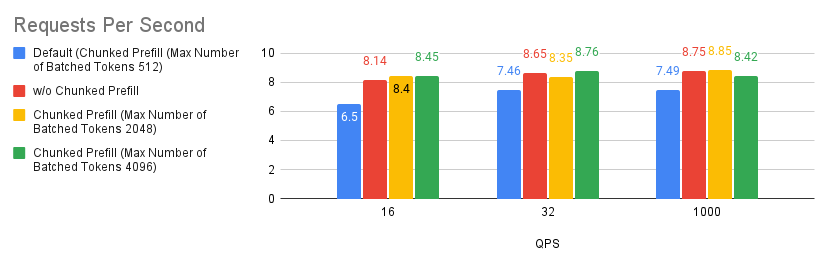
案例 1:分塊預填充
分塊預填充是 vLLM 中的一項實驗性功能,允許將大型預填充請求分成較小的塊,並與解碼請求一起批次處理。這透過將計算密集型預填充請求與記憶體密集型解碼請求重疊來提高系統效率。您可以透過在 LLM 建構函式中設定 --enable_chunked_prefill=True 或使用 --enable-chunked-prefill 命令列選項來啟用它。
根據我們執行的實驗,我們發現調整分塊預填充值比停用分塊預填充功能略有改進。但是,如果您不確定是否啟用分塊預填充,只需從停用它開始,您通常應該期望獲得比使用預設設定更好的效能。這僅適用於 MI300X GPU。
.png)
.png)
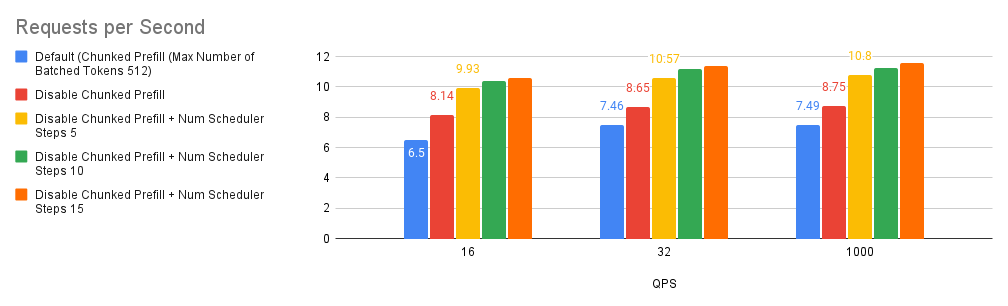
案例 2:排程器步數
多步排程已在 vLLM v0.6.0 中引入,有望提高 GPU 利用率和整體效能。正如這篇部落格文章中詳細介紹的那樣,這種效能提升背後的魔力在於它能夠執行一次排程和輸入準備,並連續執行模型多個步驟而不會中斷 GPU。透過巧妙地將 CPU 開銷分散到這些步驟中,它可以顯著減少 GPU 空閒時間並大幅提升效能。
要啟用多步排程,請將 --num-scheduler-steps 引數設定為大於 1 的數字,這是預設值(值得一提的是,我們發現使用多步排程可能會隨著值的升高而提供遞減的回報,因此,我們將上限保持在 15)。
.png)
.png)
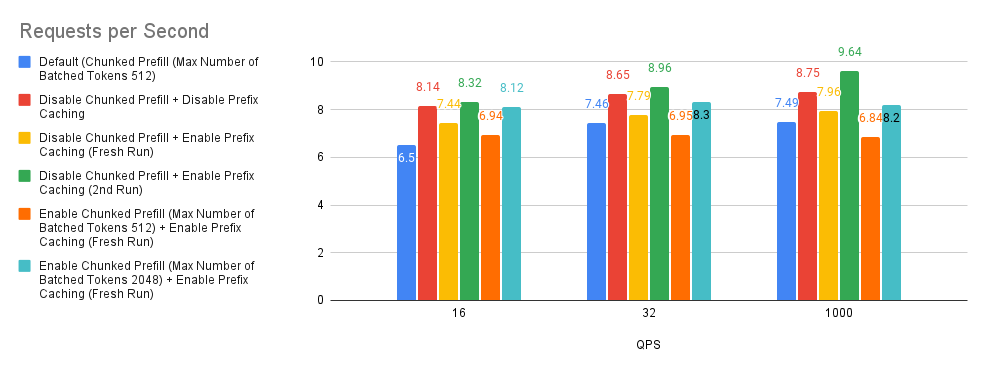
案例 3:分塊預填充和字首快取
分塊預填充和字首快取是 vLLM 中的最佳化技術,它們透過將大型預填充分解為更小的塊以實現高效批處理,以及重用跨查詢共享字首的快取 KV(鍵值)計算來提高效能。
預設情況下,如果模型的上下文長度超過 32k 個令牌,vLLM 將自動啟用分塊預填充功能。預設情況下,要分塊預填充的最大令牌數設定為 512。
在我們深入研究圖表之前,我們將首先嚐試解釋實驗中使用的術語。Fresh Run(全新執行) 指的是字首快取記憶體根本未填充的情況。2nd Run(第二次執行) 指的是在 Fresh Run 之後再次重新執行基準測試指令碼。一般來說,當在 2nd Run 上重新執行 ShareGPT 基準資料集時,我們獲得大約 50% 的字首快取命中率。
檢視下面的圖表,我們可以對這個實驗做出三個觀察結果。
- 基於 Bar 2(紅色)與基線(藍色)的比較,效能有巨大提升。
- 基於 Bar 3(黃色)、Bar 5(橙色)和 Bar 6(青色)與基線的比較,分塊預填充效能取決於使用者請求輸入提示長度分佈。
- 在我們的實驗中,我們發現 Bar 3(黃色)和 Bar 4(綠色)的字首快取命中率約為 0.9% 和 50%。基於 Bar 3(黃色)和 Bar 4(綠色)與基線和 Bar 2(紅色)的比較,這告訴我們,如果使用者請求沒有高字首快取命中率,則可以考慮停用分塊預填充和字首快取,這可能是一個好的經驗法則。
.png)
.png)
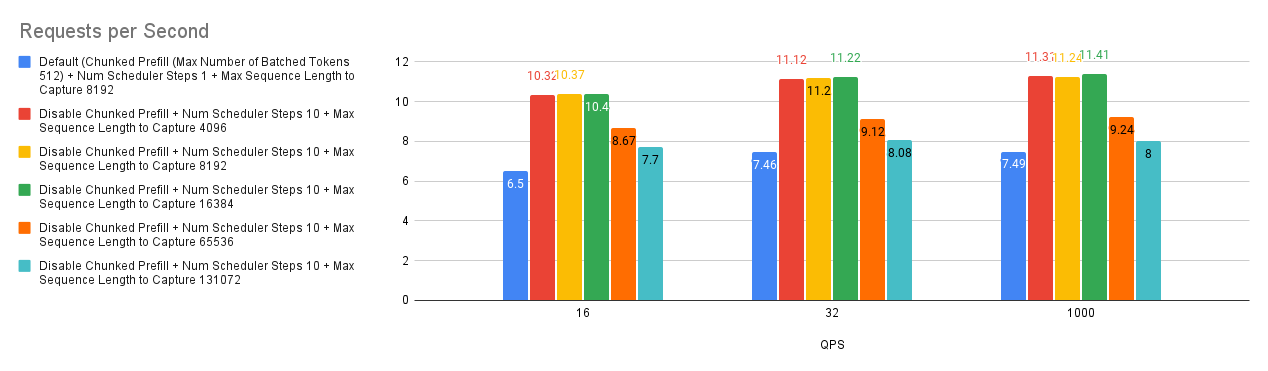
案例 4:最大序列長度捕獲
vLLM 中的 --max-seq-len-to-capture 引數控制 CUDA/HIP 圖可以處理的最大序列長度,這透過捕獲和重放 GPU 操作來最佳化效能。如果序列超過此長度,系統將恢復為 eager 模式,逐個執行操作,這可能效率較低。這適用於常規模型和編碼器-解碼器模型。
我們的基準測試揭示了一個有趣的趨勢:增加 --max-seq-len-to-capture 並不總是能提高效能,有時甚至會降低效能。這可能是由於 vLLM 如何為不同的序列長度建立 bucket。
原因如下
- Bucketing(分桶):vLLM 使用 bucket 對相似長度的序列進行分組,從而最佳化每個 bucket 的圖捕獲。
- Optimal Buckets(最佳 Bucket):最初,bucket 是細粒度的(例如,[4, 8, 12,…, 2048, 4096]),從而允許對各種序列長度進行有效的圖捕獲。
- Coarser Buckets(更粗糙的 Bucket):增加
--max-seq-len-to-capture可能會導致更粗糙的 bucket(例如,[4, 8, 12, 2048, 8192])。 - Performance Impact(效能影響):當輸入序列落入這些更大、精度較低的 bucket 中時,捕獲的 CUDA/HIP 圖可能不是最優的,這可能會導致效能下降。
因此,雖然使用 CUDA/HIP 圖捕獲更長的序列看起來是有益的,但至關重要的是要考慮對 bucketing 和整體效能的潛在影響。找到最佳的 --max-seq-len-to-capture 值可能需要進行實驗,以平衡圖捕獲效率與適用於您的特定工作負載的適當 bucket 大小。
.png)
.png)
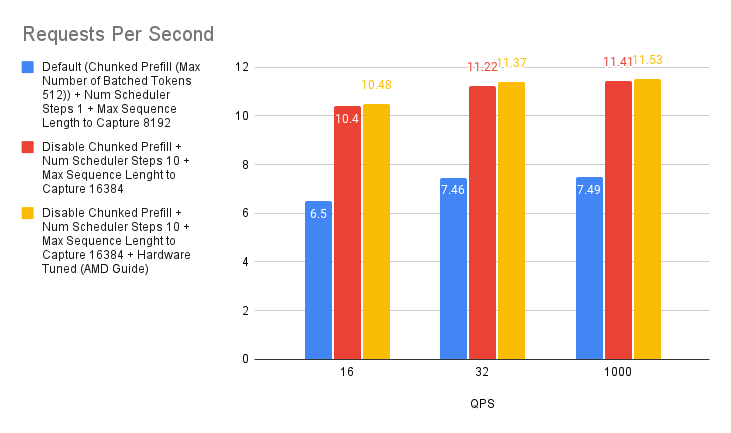
案例 5:AMD 推薦的環境變數
為了進一步最佳化 vLLM 在 AMD MI300X 上的效能,我們可以利用 AMD 特定的環境變數。
- 停用 NUMA 平衡:非統一記憶體訪問 (NUMA) 平衡有時會阻礙 GPU 效能。正如 AMD MAD 倉庫中建議的那樣,停用它可以防止潛在的 GPU 掛起並提高整體效率。可以使用以下命令實現此目的
# disable automatic NUMA balancing sh -c 'echo 0 > /proc/sys/kernel/numa_balancing' # check if NUMA balancing is disabled (returns 0 if disabled) cat /proc/sys/kernel/numa_balancing 0 - 調整 NCCL 通訊:NVIDIA Collective Communications Library (NCCL) 用於 GPU 間通訊。對於 MI300X,AMD vLLM 分支效能文件建議將
NCCL_MIN_NCHANNELS環境變數設定為 112,以潛在地提高效能。
在我們的測試中,啟用這兩個配置產生了輕微的效能提升。這與 “NanoFlow: Towards Optimal Large Language Model Serving Throughput” 論文中的發現一致,該論文表明,雖然最佳化網路通訊是有益的,但由於 LLM 推理主要由計算密集型和記憶體密集型操作主導,因此影響可能有限。
即使收益可能很小,微調這些環境變數也有助於從您的 AMD 系統中榨取最大效能。
.png)
.png)
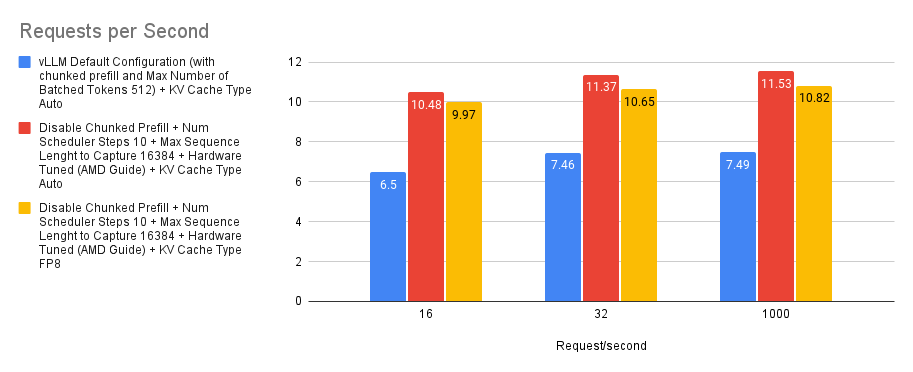
案例 6:KVCache 型別 Auto/FP8
預設情況下,vLLM 將自動分配與模型資料型別匹配的 KV 快取型別。但是,vLLM 也支援 MI300X 上的原生 FP8,我們可以利用它來減少 KVCache 的記憶體需求,從而增加模型的可部署上下文長度。
我們透過使用 Auto KVCache 型別和 KV 快取型別 FP8 進行實驗,並將其與預設基線進行比較。我們可以從下圖看到,使用 Auto KVCache 型別(紅色)比使用設定為 FP8 的 KV 快取型別(黃色)實現了更高的每秒請求數。理論上,這可能是由於 Llama-3.1-70B-Instruct (bfloat16) 模型中的量化開銷造成的,但由於開銷成本似乎很小,因此在某些情況下,為了獲得 KVCache 需求的巨大減少,這仍然可能是一個很好的權衡。
.png)
.png)
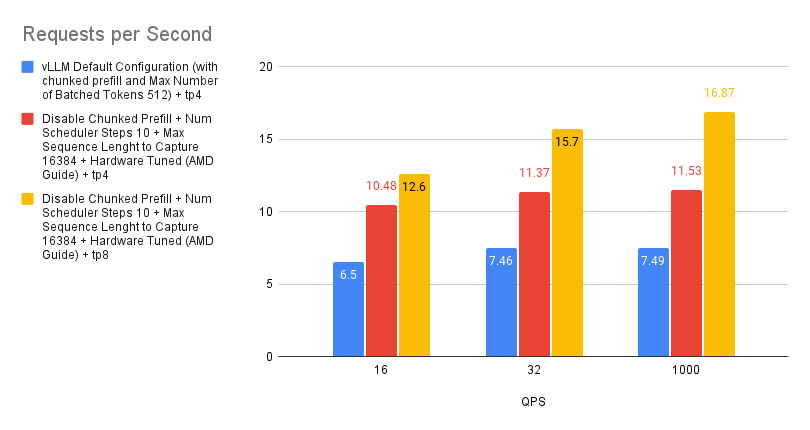
案例 7:TP 4 和 TP 8 之間的效能差異
張量並行是一種用於分配大型模型計算負載的技術。它的工作原理是將單個張量拆分到多個裝置上,從而允許並行處理特定操作或層。這種方法減少了模型的記憶體佔用,並實現了跨多個 GPU 的擴充套件。
雖然增加張量並行度可以透過提供更多計算資源來提高效能,但收益並不總是線性的。這是因為隨著更多裝置的參與,通訊開銷會增加,而每個 GPU 上的工作負載會減少。考慮到 MI300X 的強大處理能力,每個 GPU 較小的工作負載實際上可能導致利用率不足,進一步阻礙效能擴充套件。
因此,當最佳化吞吐量時,我們建議啟動多個 vLLM 例項,而不是激進地增加張量並行度。這種方法往往會產生更線性的效能提升。但是,如果最小化延遲是首要任務,則增加張量並行度可能是更有效的策略。
.png)
.png)
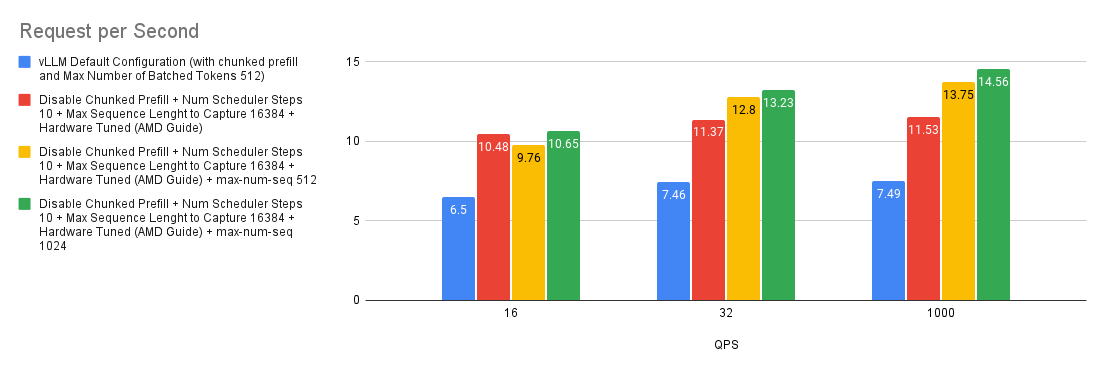
案例 8:最大(並行)序列數的影響
--max-num-seqs 引數指定每次迭代可以處理的最大序列數。此引數控制批處理中併發請求的數量,從而影響記憶體使用和效能。在 ShareGPT 基準測試中,由於樣本的輸入和輸出長度較短,因此託管在 MI300X 上的 Llama-3.1-70B-Instruct 可以在每次迭代中處理大量請求。在我們的實驗中,即使 --max-num-seqs 設定為 1024,--max-num-seqs 仍然是一個限制因素。
.png)
.png)
快速入門指南
如果您不確定部署設定和使用者請求的分佈,您可以
- 使用 CK Flash Attention*(雖然我們在此處沒有展示,但 CK Flash Attention 實現比 triton 對應實現快得多)
export VLLM_USE_TRITON_FLASH_ATTN=0
- 停用分塊預填充
--enable-chunked-prefill=False - 停用字首快取
- 如果模型支援長上下文長度,請將
--max-seq-len-to-capture設定為 16384 - 將
--num-scheduler-steps設定為 10 或 15。 - 設定 AMD 環境
sh -c 'echo 0 > /proc/sys/kernel/numa_balancing'export NCCL_MIN_NCHANNELS=112
- 將
--max-num-seqs增加到 512 及以上,具體取決於 GPU 的記憶體和計算資源。
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve meta-llama/Llama-3.1-70B-Instruct --host 0.0.0.0 --port 8000 -tp 4 --max-num-seqs 1024 --max-seq-len-to-capture 16384 --served-model-name meta-llama/Llama-3.1-70B-Instruct --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024
為了快速設定,我們已將 vLLM 0.6.2(commit:cb3b2b9ba4a95c413a879e30e2b8674187519a93)的 Docker 映象編譯到 Github Container Registry。要獲取下載映象
# v0.6.2 post
docker pull ghcr.io/embeddedllm/vllm-rocm:cb3b2b9
# P.S. We also have compiled the image for v0.6.3.post1 at commit 717a5f8
docker pull ghcr.io/embeddedllm/vllm-rocm:v0.6.3.post1-717a5f8
要使用映象啟動 docker 容器,請執行
sudo docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v /path/to/hfmodels:/app/model \ # if you have pre-downloaded the model weight, else ignore
ghcr.io/embeddedllm/vllm-rocm:cb3b2b9 \
bash
現在使用我們找到的引數啟動 LLM 伺服器
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve meta-llama/Llama-3.1-70B-Instruct --host 0.0.0.0 --port 8000 -tp 4 --max-num-seqs 1024 --max-seq-len-to-capture 16384 --served-model-name meta-llama/Llama-3.1-70B-Instruct --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024
結論
本指南探討了 vLLM 在 AMD MI300X GPU 上部署大型語言模型的強大功能。透過細緻地調整分塊預填充、多步排程和 CUDA 圖捕獲等關鍵設定,我們展示瞭如何實現相對於標準配置和替代服務解決方案的顯著效能提升。vLLM 釋放了顯著更高的吞吐量和更快的響應時間,使其成為在 AMD 硬體上部署 LLM 的理想選擇。
但是,重要的是要承認我們的探索主要集中在具有短輸入和輸出的通用聊天機器人使用上。還需要進一步研究以最佳化 vLLM 用於特定用例,如摘要或長篇內容生成。此外,深入研究 Triton 和 CK attention 核心之間的效能差異可能會產生進一步的見解。
我們還要感謝 Leonard Lin 的 這篇精彩的部落格文章,它介紹瞭如何進一步最佳化 vLLM for MI300X,包括 hipBLAS vs hipBLASLt、CK Flash Attention vs Triton Flash Attention、張量並行 vs 流水線並行等。
致謝
本部落格文章由 Embedded LLM 團隊起草,感謝 Hot Aisle Inc. 贊助 MI300X 用於 vLLM 基準測試。
附錄
伺服器規格
以下是驚人的 Hot Aisle 伺服器的配置
- CPU:2 個 Intel Xeon Platinum 8470
- GPU:8 個 AMD Instinct MI300X 加速器 我們在基準測試中使用的模型和軟體如下
- 模型:meta-llama/Llama-3.1-405B-Instruct 和 meta-llama/Llama-3.1-70B-Instruct
- vLLM (v0.6.2):vllm-project/vllm:用於 LLM 的高吞吐量和記憶體高效的推理和服務引擎 (github.com) commit: cb3b2b9ba4a95c413a879e30e2b8674187519a93
- 資料集:ShareGPT
- 基準測試指令碼:儲存庫中的 benchmarks/benchmark_serving.py
我們已經從儲存庫中的 Dockerfile.rocm 構建了 ROCm 相容的 vLLM docker(我們已經推送了我們用於執行基準測試的 vLLM 版本的 docker 映象。透過 docker pull ghcr.io/embeddedllm/vllm-rocm:cb3b2b9 獲取它)。所有基準測試都在 docker 容器例項中執行,並使用 4 個 MI300X GPU 和 CK Flash Attention 執行,VLLM_USE_TRITON_FLASH_ATTN=0.
詳細基準測試配置
| 配置 | 命令 |
|---|---|
| vLLM 預設配置 | VLLM_RPC_TIMEOUT=30000 VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve Llama-3.1-405B-Instruct -tp 8 --max-num-seqs 1024 --max-num-batched-tokens 1024 |
| TGI 預設配置 | ROCM_USE_FLASH_ATTN_V2_TRITON=false TRUST_REMOTE_CODE=true text-generation-launcher --num-shard 8 --sharded true --max-concurrent-requests 1024 --model-id Llama-3.1-405B-Instruct |
| vLLM(本指南) | VLLM_RPC_TIMEOUT=30000 VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve Llama-3.1-405B-Instruct -tp 8 --max-seq-len-to-capture 16384 --enable-chunked-prefill=False --num-scheduler-steps 15 --max-num-seqs 1024 |
| TGI(本指南) | ROCM_USE_FLASH_ATTN_V2_TRITON=false TRUST_REMOTE_CODE=true text-generation-launcher --num-shard 8 --sharded true --max-concurrent-requests 1024 --max-total-tokens 131072 --max-input-tokens 131000 --model-id Llama-3.1-405B-Instruct |