vLLM V1:vLLM 核心架構的重大升級
![]()
我們激動地宣佈 vLLM V1 的 alpha 版本釋出,這是對 vLLM 核心架構的重大升級。基於我們在過去 1.5 年 vLLM 開發中吸取的經驗教訓,我們重新審視了關鍵的設計決策,整合了各種功能,並簡化了程式碼庫,以增強靈活性和可擴充套件性。V1 已經實現了最先進的效能,並且有望獲得更多的最佳化。最棒的是,使用者可以無縫啟用 V1 —— 只需設定 VLLM_USE_V1=1 環境變數,無需對現有 API 進行任何更改。在未來幾周的測試和反饋收集之後,我們計劃將 V1 過渡為預設引擎。
為什麼選擇 vLLM V1?
從 vLLM V0 中學習
在過去的 1.5 年中,vLLM 在支援各種模型、功能和硬體後端方面取得了顯著成功。然而,當我們的社群橫向擴充套件時,我們在簡化系統以及在堆疊中垂直整合各種最佳化方面面臨挑戰。功能通常是獨立開發的,使得有效且清晰地組合它們變得困難。隨著時間的推移,技術債務累積,促使我們重新審視我們的基礎設計。
V1 的目標
基於上述動機,vLLM V1 的設計目標是:
- 提供一個簡單、模組化且易於 hack 的程式碼庫。
- 確保高效能,並且 CPU 開銷接近於零。
- 將關鍵最佳化整合到一個統一的架構中。
- 透過預設啟用功能/最佳化,實現 零配置。
V1 的範圍
vLLM V1 引入了對其核心元件的全面重新架構,包括排程器、KV 快取管理器、worker、取樣器和 API 伺服器。然而,它仍然與 vLLM V0 共享許多程式碼,例如模型實現、GPU 核心、分散式控制平面和各種實用函式。這種方法使 V1 能夠在利用 V0 建立的廣泛覆蓋範圍和穩定性的同時,顯著增強效能和降低程式碼複雜性。
vLLM V1 的新特性?
1. 最佳化的執行迴圈和 API 伺服器
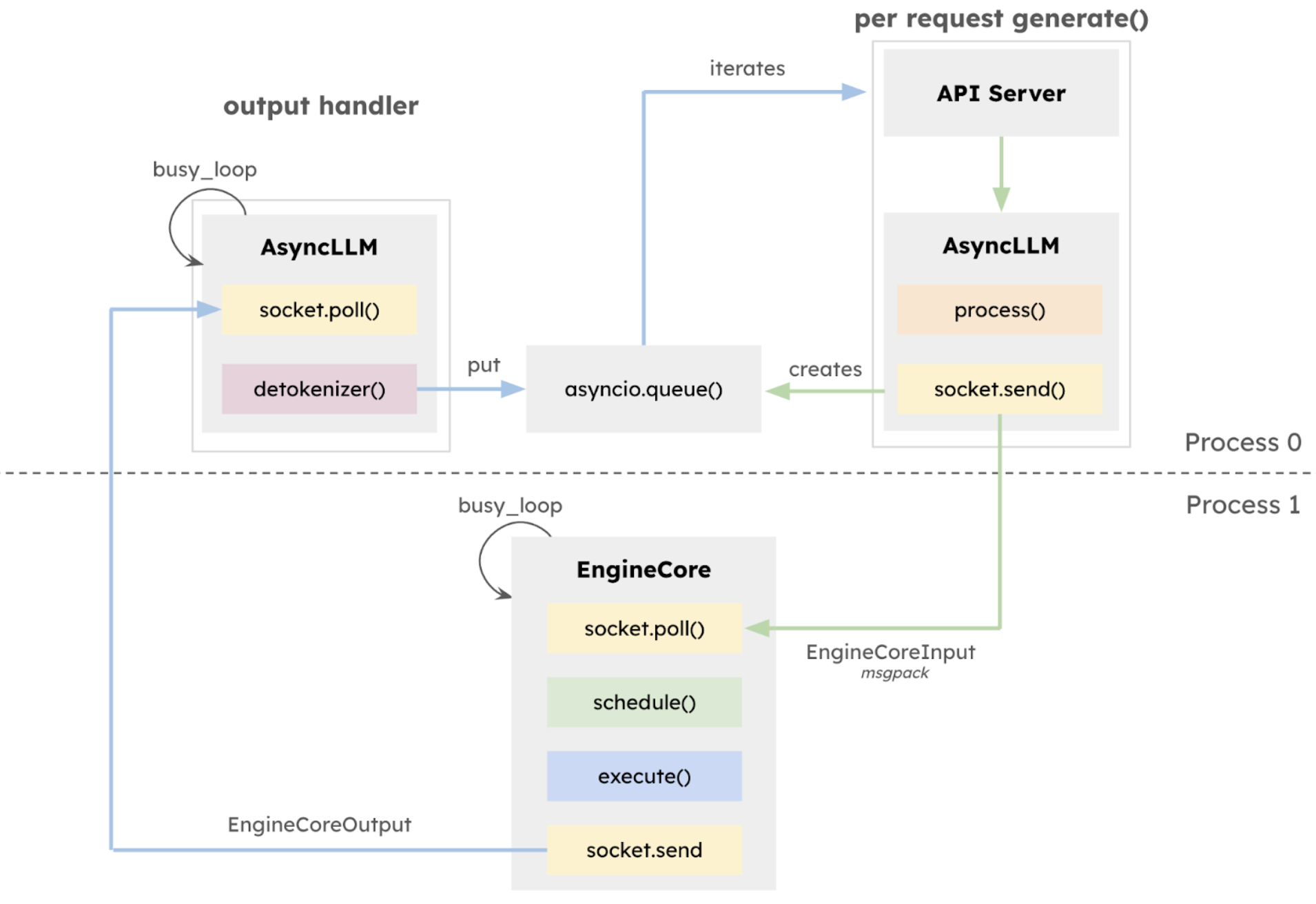
作為一個成熟的連續批處理引擎和相容 OpenAI 的 API 伺服器,vLLM 的核心執行迴圈依賴 CPU 操作來管理模型前向傳遞之間的請求狀態。隨著 GPU 變得越來越快,並顯著減少了模型執行時間,用於執行 API 伺服器、排程工作、準備輸入、反token化輸出以及向用戶流式傳輸響應等任務的 CPU 開銷變得越來越明顯。對於像 Llama-8B 這樣在 NVIDIA H100 GPU 上執行的小型模型,這個問題尤其突出,因為在 GPU 上的執行時間低至約 5 毫秒。
在 v0.6.0 版本 中,vLLM 引入了一個利用 ZeroMQ for IPC 的多程序 API 伺服器,實現了 API 伺服器和 AsyncLLM 之間的重疊。vLLM V1 透過將多程序架構更深入地整合到 AsyncLLM 的核心中來擴充套件這一點,建立了一個隔離的 EngineCore 執行迴圈,該迴圈專門專注於排程器和模型執行器。這種設計允許 CPU 密集型任務(如 token 化、多模態輸入處理、反token化和請求流式傳輸)與核心執行迴圈之間更大的重疊,從而最大化模型吞吐量。
2. 簡單且靈活的排程器
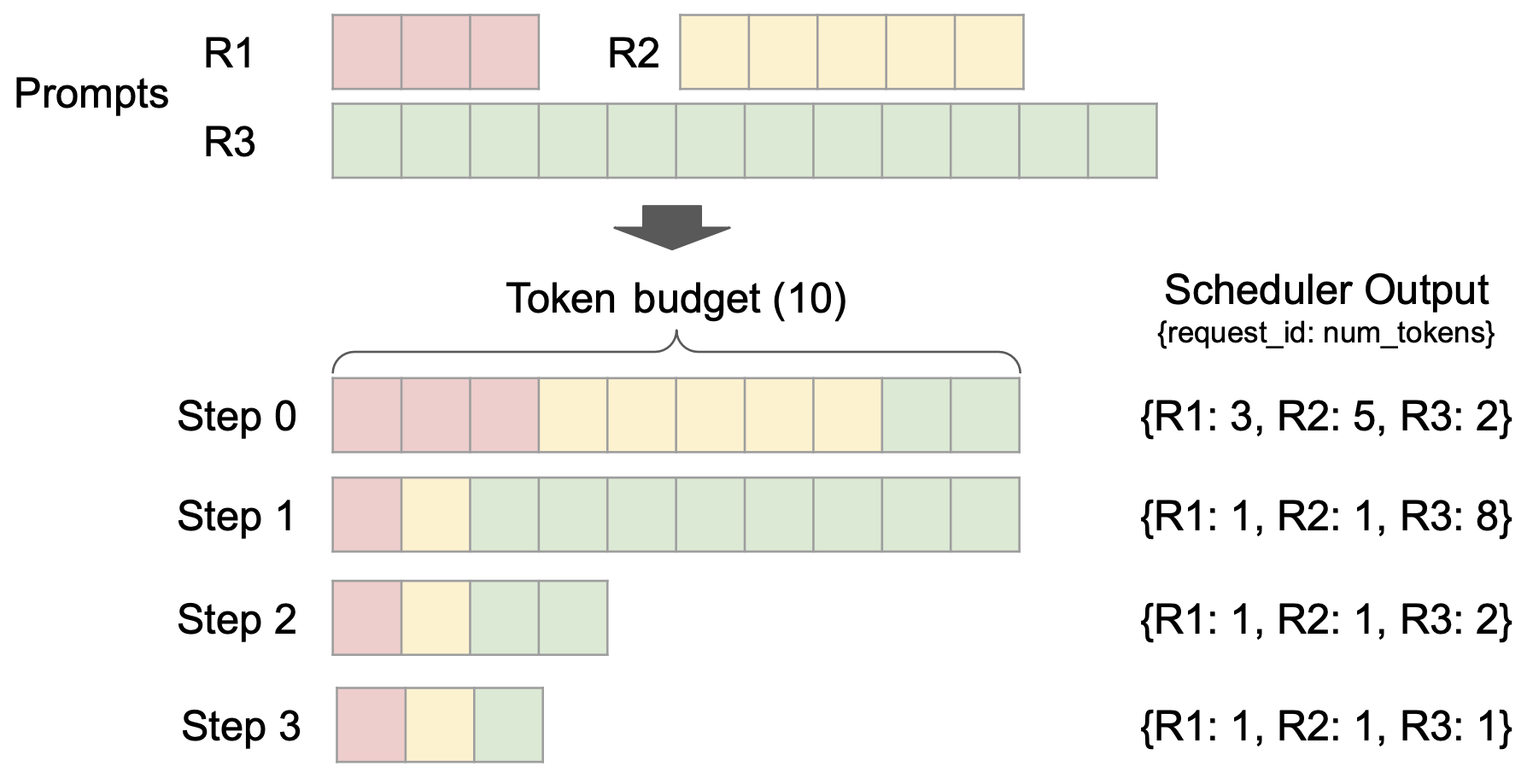
vLLM V1 引入了一個簡單而靈活的排程器。它消除了傳統的“預填充”和“解碼”階段之間的區別,統一對待使用者給定的 prompt tokens 和模型生成的輸出 tokens。排程決策表示為一個簡單的字典,例如,{request_id: num_tokens},它指定了在每個步驟中要為每個請求處理的 tokens 數量。我們發現這種表示足夠通用,可以支援分塊預填充、字首快取和推測解碼等功能。例如,分塊預填充排程可以無縫實現:在固定的 tokens 預算下,排程器動態決定為每個請求分配多少 tokens(如上圖所示)。
3. 零開銷字首快取
與 V0 一樣,vLLM V1 使用基於雜湊的字首快取和基於 LRU 的快取驅逐。在 V0 中,啟用字首快取有時會導致顯著的 CPU 開銷,當快取命中率較低時,會導致效能明顯下降。因此,預設情況下它是停用的。在 V1 中,我們優化了資料結構以實現恆定時間的快取驅逐,並仔細地最小化了 Python 物件建立開銷。這使得 V1 的字首快取引入的效能下降幾乎為零,即使快取命中率為 0% 也是如此。
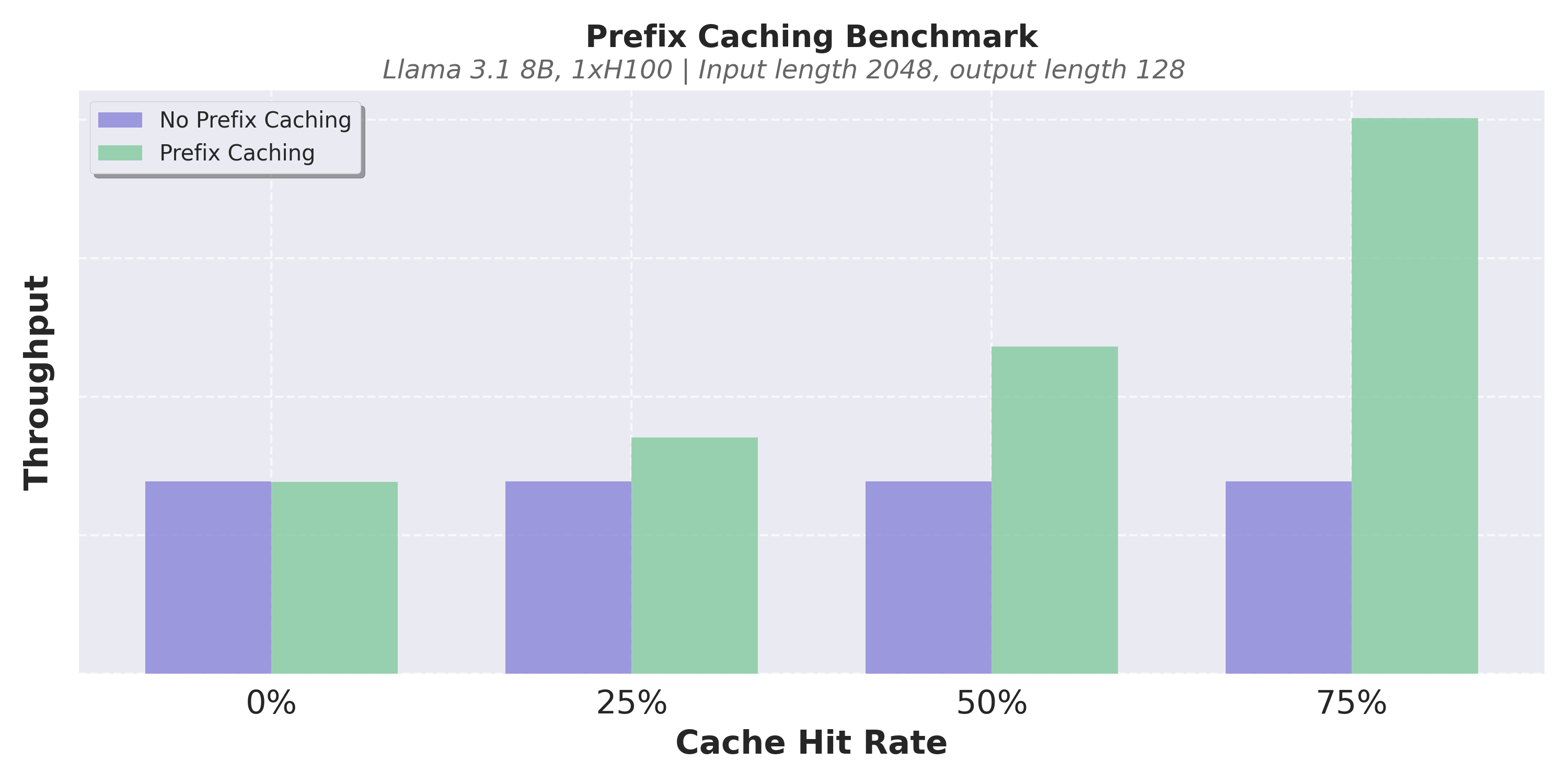
以下是一些基準測試結果。在我們的實驗中,我們觀察到,即使快取命中率為 0%,V1 的字首快取也只會導致吞吐量下降不到 1%,而當快取命中率較高時,它可以將效能提高數倍。由於近乎零開銷,我們現在在 V1 中預設啟用字首快取。
4. 用於張量並行推理的清晰架構
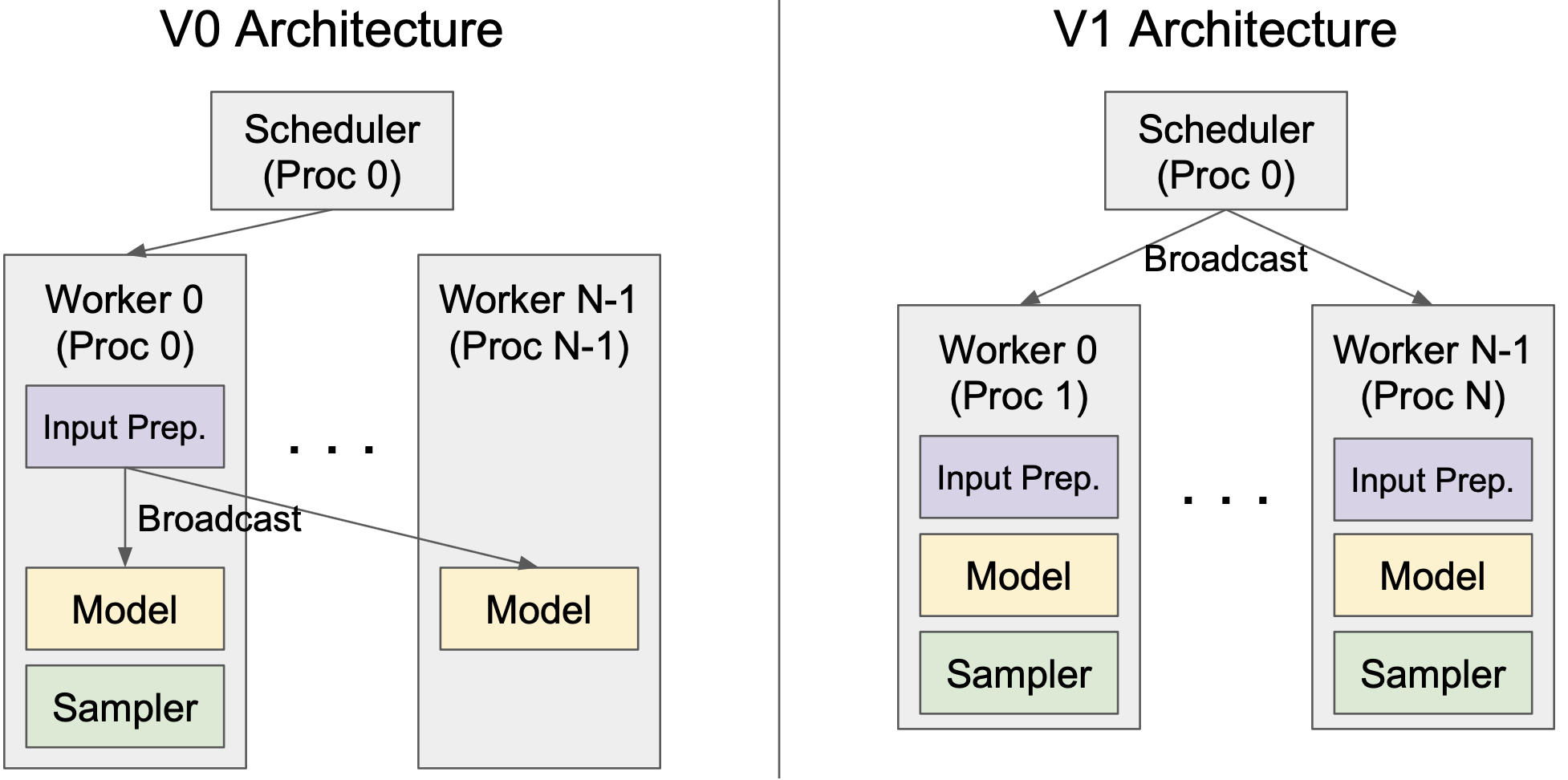
vLLM V1 引入了一個用於張量並行推理的清晰高效的架構,有效地解決了 V0 的侷限性。在 V0 中,排程器和 Worker 0 位於同一程序中,以減少將輸入資料廣播到 workers 時的程序間通訊開銷。然而,這種設計引入了不對稱架構,增加了複雜性。V1 透過在 worker 端快取請求狀態並在每個步驟僅傳輸增量更新(差異)來克服這一點。這種最佳化最大限度地減少了程序間通訊,允許排程器和 Worker 0 在單獨的程序中執行,從而產生清晰的對稱架構。此外,V1 抽象出了大部分分散式邏輯,使 workers 在單 GPU 和多 GPU 設定中都以相同的方式執行。
5. 高效的輸入準備

在 vLLM V0 中,模型的輸入張量和元資料在每個步驟都會重新建立,這通常會導致顯著的 CPU 開銷。為了最佳化這一點,V1 實現了 Persistent Batch 技術,該技術快取輸入張量,並在每個步驟僅對其應用差異。此外,V1 透過廣泛使用 Numpy 操作而不是 Python 的原生操作,最大限度地減少了更新張量時的 CPU 開銷。
6. torch.compile 和分段 CUDA 圖

V1 利用 vLLM 的 torch.compile 整合來自動最佳化模型。這使得 V1 能夠高效地支援各種模型,同時最大限度地減少編寫自定義核心的需求。此外,V1 引入了分段 CUDA 圖,以緩解 CUDA 圖的侷限性。我們正在準備關於 torch.compile 整合和分段 CUDA 圖的專門部落格文章,所以請繼續關注更多更新!
7. 增強對多模態 LLM 的支援
vLLM V1 將多模態大型語言模型 (MLLM) 視為一等公民,並在其支援中引入了多項關鍵改進。
首先,V1 透過將多模態輸入預處理移動到非阻塞程序來最佳化它。例如,影像檔案(例如,JPG 或 PNG)必須轉換為畫素值張量,裁剪和轉換後才能饋送到模型中。這種預處理可能會消耗大量的 CPU 週期,可能會使 GPU 處於空閒狀態。為了解決這個問題,V1 將預處理任務解除安裝到單獨的程序,防止它阻塞 GPU worker,並新增預處理快取,以便在請求之間共享相同的多模態輸入時可以重用已處理的輸入。
其次,V1 為多模態輸入引入了字首快取。除了 token ID 的雜湊值之外,影像雜湊值也用於識別影像輸入的 KV 快取。這種改進對於包含影像輸入的多輪對話尤其有利。
第三,V1 為帶有“encoder cache”的 MLLM 啟用了分塊預填充排程。在 V0 中,影像輸入和文字輸入必須在同一步驟中處理,因為 LLM 解碼器的 token 依賴於視覺嵌入,而視覺嵌入在步驟後會被丟棄。藉助 encoder cache,V1 臨時儲存視覺嵌入,允許排程器將文字輸入分成塊並在多個步驟中處理它們,而無需在每個步驟都重新生成視覺嵌入。
8. FlashAttention 3
vLLM V1 的最後一塊拼圖是整合 FlashAttention 3。鑑於 V1 中高度的動態性(例如在同一批次中組合預填充和解碼),一個靈活且高效能的注意力核心至關重要。FlashAttention 3 有效地滿足了這一要求,為廣泛的功能提供了強大的支援,同時在各種用例中保持了出色的效能。
效能
得益於廣泛的架構增強,vLLM V1 實現了最先進的吞吐量和延遲,與 V0 相比,吞吐量提高了高達 1.7 倍(不包括多步排程)。這些顯著的效能提升源於整個堆疊中全面的 CPU 開銷降低。對於像 Qwen2-VL 這樣的視覺語言模型 (VLM),改進更加明顯,這要歸功於 V1 對 VLM 的增強支援。
- 文字模型:Llama 3.1 8B 和 Llama 3.3 70B
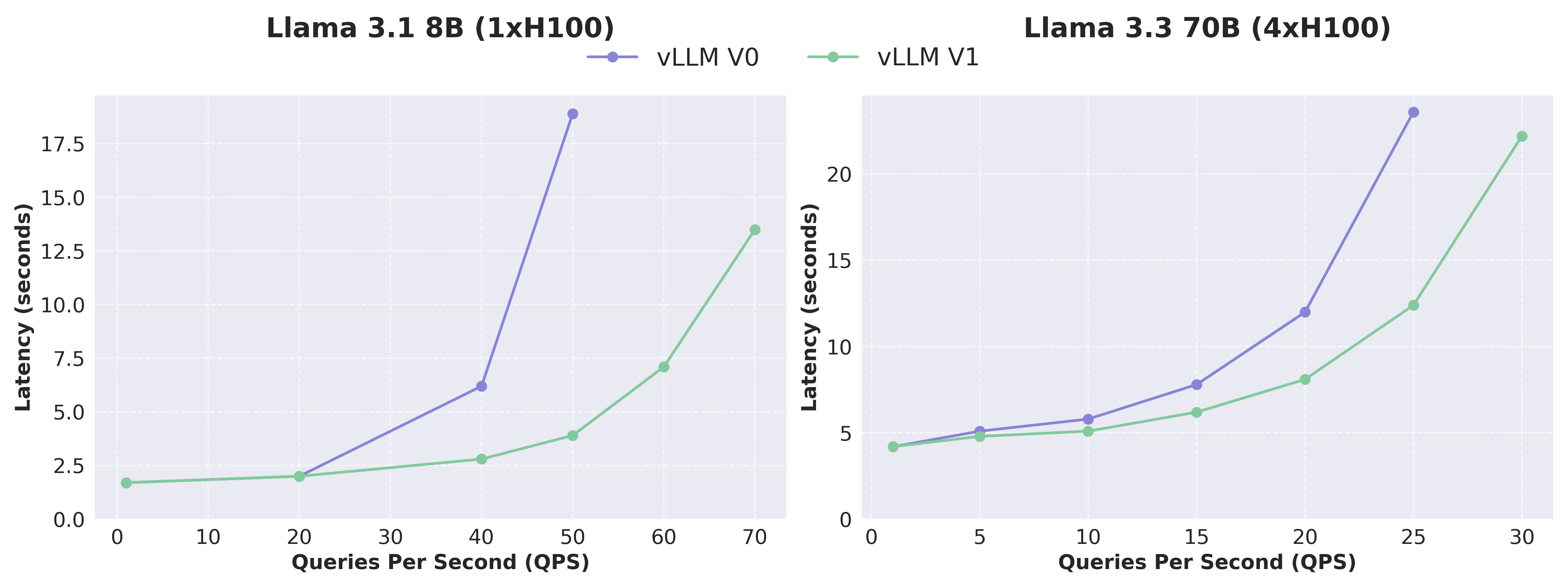
我們使用 ShareGPT 資料集測量了 vLLM V0 和 V1 在 Llama 3.1 8B 和 Llama 3.3 70B 模型上的效能。V1 展示了始終低於 V0 的延遲,尤其是在高 QPS 下,這要歸功於它實現的更高吞吐量。鑑於 V0 和 V1 使用的核心幾乎相同,效能差異主要歸因於 V1 中的架構改進(降低了 CPU 開銷)。
- 視覺語言模型:Qwen2-VL
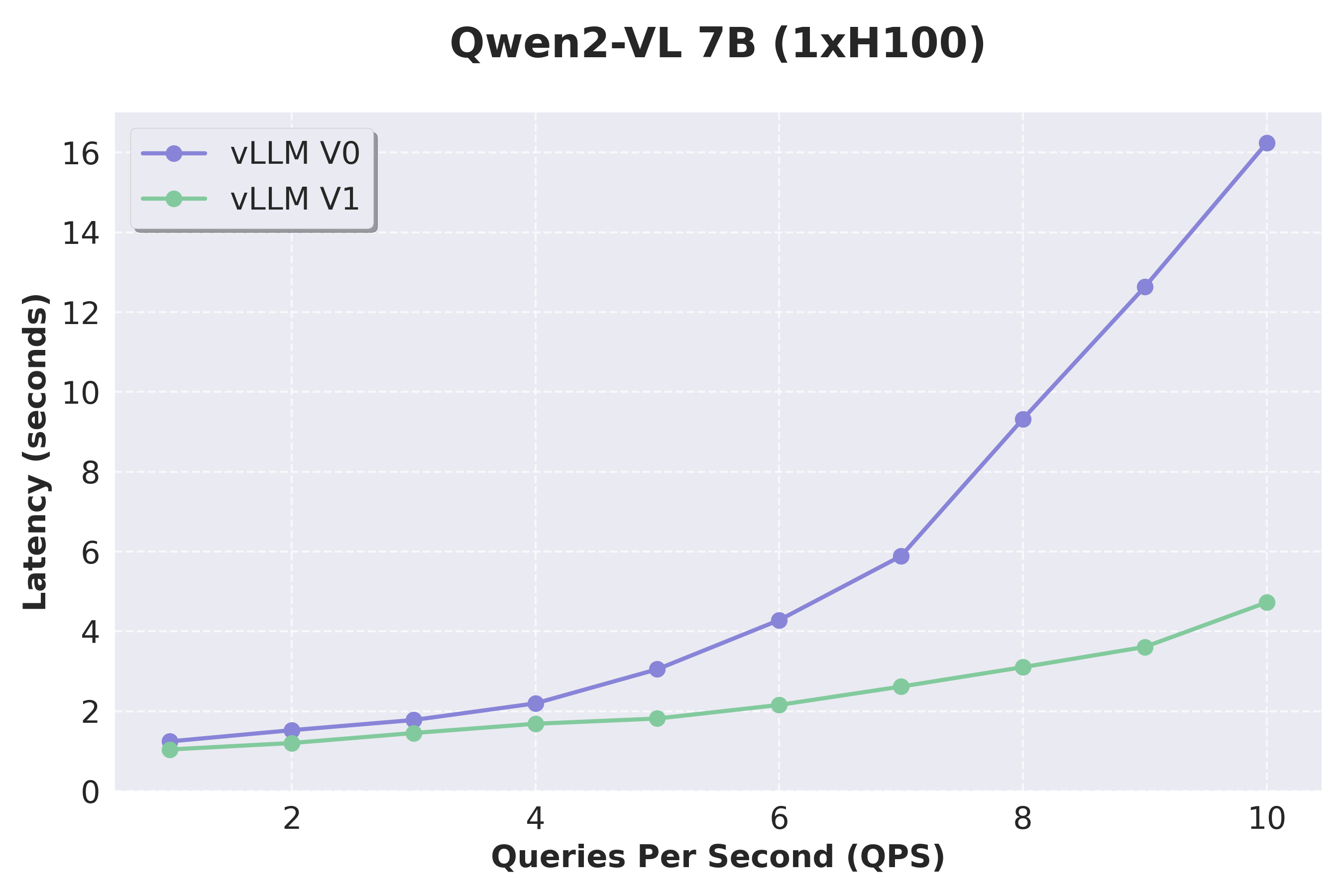
我們透過使用 VisionArena 資料集測試 Qwen2-VL 來評估 VLM 的效能。V1 實現了比 V0 更大的加速,這要歸功於其改進的 VLM 支援,這得益於兩項關鍵改進:將輸入處理解除安裝到單獨的程序,以及為多模態查詢實現更靈活的排程。我們還要指出,字首快取現在在 V1 中原生支援多模態模型,但在此處將跳過基準測試結果。
- 展望未來
雖然這些改進意義重大,但我們認為這僅僅是開始。重新設計的架構提供了一個堅實的基礎,這將有助於新功能的快速開發。我們期待在未來幾周內分享更多的增強功能。請繼續關注更多更新!
侷限性與未來工作
雖然 vLLM V1 顯示出令人鼓舞的結果,但它仍處於 alpha 階段,並且缺少 V0 的一些功能。以下是一些澄清:
模型支援
V1 支援僅解碼器 Transformer 模型,如 Llama,混合專家 (MoE) 模型,如 Mixtral,以及一些 VLM,如 Qwen2-VL。支援所有量化方法。但是,V1 目前不支援編碼器-解碼器架構,如多模態 Llama 3.2、基於 Mamba 的模型,如 Jamba,或嵌入模型。請檢視 我們的文件 以獲取更詳細的支援模型列表。
功能限制
V1 目前缺少對 log probs、prompt log probs 取樣引數、流水線並行、結構化解碼、推測解碼、Prometheus 指標和 LoRA 的支援。我們正在積極努力彌合這一功能差距,並向 V1 引擎新增全新的最佳化。
硬體支援
V1 目前僅支援 Ampere 或更高版本的 NVIDIA GPU。我們正在積極努力將支援擴充套件到其他硬體後端,如 TPU。
最後,請注意,您可以透過不設定 VLLM_USE_V1=1 來繼續使用 V0 並保持向後相容性。
如何開始使用
要使用 vLLM V1:
- 使用
pip install vllm --upgrade安裝最新版本的 vLLM。 - 設定環境變數
export VLLM_USE_V1=1。 - 使用 vLLM 的 Python API 或相容 OpenAI 的伺服器 (
vllm serve <model-name>)。您無需對現有 API 進行任何更改。
請試用並分享您的反饋!
致謝
我們衷心感謝 vLLM V1 的設計基於並增強了幾個開源 LLM 推理引擎,包括 LightLLM、LMDeploy、SGLang、TGI 和 TRT-LLM。這些引擎對我們的工作產生了重大影響,我們從中獲得了寶貴的見解。
V1 重新架構是整個 vLLM 團隊和社群持續共同努力的成果。以下是對此里程碑做出貢獻的不完整列表:
- UC Berkeley、Neural Magic (現為 Red Hat)、Anyscale 和 Roblox 主要共同推動了這項工作。
- Woosuk Kwon 發起了該專案並實現了排程器和模型執行器。
- Robert Shaw 實現了最佳化的執行迴圈和 API 伺服器。
- Cody Yu 實現了文字和影像輸入的高效字首快取。
- Roger Wang 領導了 V1 中整體增強的 MLLM 支援。
- Kaichao You 領導了 torch.compile 整合並實現了分段 CUDA 圖。
- Tyler Michael Smith 使用 Python 多程序實現了張量並行支援。
- Rui Qiao 使用 Ray 實現了張量並行支援,並且正在實現流水線並行支援。
- Lucas Wilkinson 添加了對 FlashAttention 3 的支援。
- Alexander Matveev 實現了多模態輸入的最佳化預處理器,並且正在實現 TPU 支援。
- Sourashis Roy 在取樣器中實現了 logit penalties。
- Cyrus Leung 領導了 MLLM 輸入處理重構工作,並幫助將其整合到 V1。
- Russell Bryant 解決了幾個與多程序相關的問題。
- Nick Hill 優化了引擎迴圈和 API 伺服器。
- Ricky Xu 和 Chen Zhang 幫助重構了 KV 快取管理器。
- Jie Li 和 Michael Goin 幫助進行了 MLLM 支援和最佳化。
- Aaron Pham 正在實現結構化解碼支援。
- Varun Sundar Rabindranath 正在實現多 LoRA 支援。
- Andrew Feldman 正在實現 log probs 和 prompt log probs 支援。
- Lily Liu 正在實現推測解碼支援。
- Kuntai Du 正在實現預填充解聚和 KV 快取傳輸支援。
- Simon Mo 和 Zhuohan Li 為 V1 系統設計做出了貢獻。