vLLM 中的 Llama 4
我們激動地宣佈,vLLM 現在支援 Llama 4 系列模型:Scout (17B-16E) 和 Maverick (17B-128E)。您今天即可在 vLLM 中執行這些強大的長上下文、原生多模態(最高支援 8-10 張影像並獲得良好結果)以及混合專家模型,只需更新到 v0.8.3 或更高版本即可。
pip install -U vllm
下方提供了入門示例命令。或者,您也可以將 CLI 命令替換為 docker run (說明在此),或使用我們的 Python 介面 LLM 類進行本地批處理推理。我們還建議您檢視 Meta 團隊的演示,其中展示了 vLLM 支援 1M 長上下文的能力。
使用指南
以下是如何使用不同的硬體配置來服務 Llama 4 模型。
使用 8x H100,vLLM 可以服務 Scout 模型,支援 1M 上下文;服務 Maverick 模型,支援約 430K 上下文。請參閱下方更多關於效能提升和利用長上下文的技巧。
在 8x H100 GPU 上
- Scout(最高支援 1M 上下文)
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 8 \
--max-model-len 1000000 --override-generation-config='{"attn_temperature_tuning": true}'
- Maverick(最高支援約 430K 上下文)
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 \
--tensor-parallel-size 8 \
--max-model-len 430000'
在 8x H200 GPU 上
- Scout(最高支援 3.6M 上下文)
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 8 \
--max-model-len 3600000'
- Maverick(最高支援 1M 上下文)
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 \
--tensor-parallel-size 8
--max-model-len 1000000'
多模態能力
Llama 4 模型在影像理解方面表現出色,最高支援 8-10 張影像。預設情況下,vLLM 服務端每次請求接受 1 張影像。請傳遞 --limit-mm-per-prompt image=10 引數,以使用 OpenAI 相容 API 支援每次請求最多 10 張影像。我們還建議您檢視我們的 Llama-4 多影像離線推理示例 此處。
效能
在上述配置下,我們觀察到 Scout-BF16 和 Maverick-FP8 的輸出 token/秒 如下
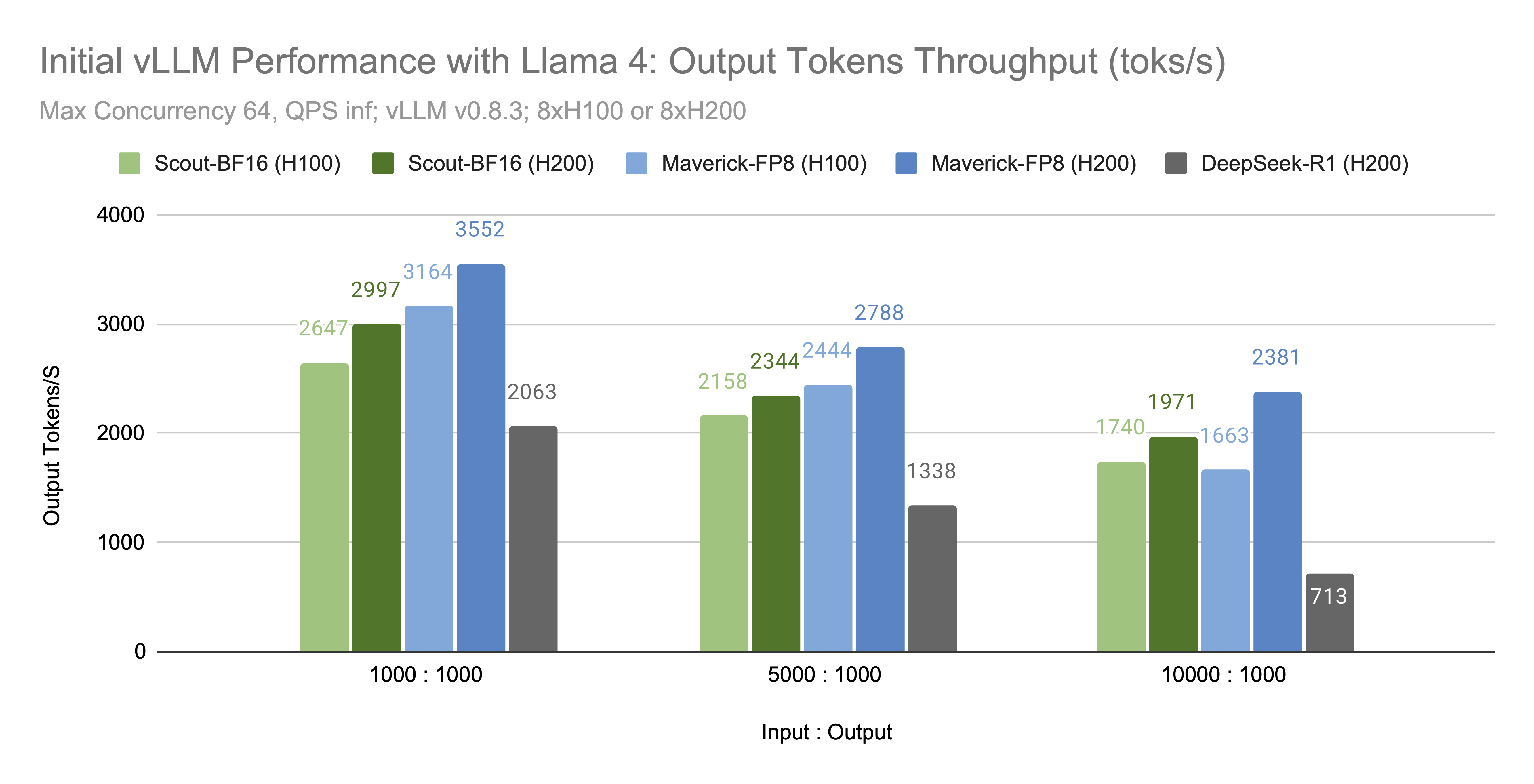
雖然更多效能最佳化正在進行中,但我們相信 Llama 4 模型高效的架構和相對較小的尺寸使其在今天的規模化使用中具有實用性。
效能和長上下文技巧
- 提升效能和上下文長度:設定
--kv-cache-dtype fp8引數,這可能使可用上下文視窗翻倍並提升效能。我們發現在相關評估中,此設定對精度幾乎沒有影響。 - 最大化上下文視窗(最高 10M):為了充分利用最大上下文視窗(Scout 最高可達 10M),我們建議使用張量並行或流水線並行在多個節點上進行服務。請遵循我們的分散式推理指南 此處。
其他硬體支援和量化
- A100:我們已驗證模型的 bf16 版本在 A100 GPU 上執行良好。
- INT4:目前正在開發 Scout 模型檢查點的 INT4 量化版本,該版本可在單個 H100 GPU 上執行。敬請關注更新。
- AMD MI300X:您可以透過從原始碼構建 vLLM 並在 AMD MI300X GPU 上執行 Llama 4,使用與上述相同的命令。
推理精度驗證:我們使用 lm-eval-harness 工具對照 Meta 的官方報告驗證了推理精度。以下是 meta-llama/Llama-4-Maverick-17B-128E-Instruct 的結果
| MMLU Pro | ChartQA | |
|---|---|---|
| 報告結果 | 80.5 | 90 |
| H100 FP8 | 80.4 | 89.4 |
| AMD MI300x BF16 | 80.4 | 89.4 |
| H200 BF16 | 80.2 | 89.3 |
高效架構和叢集規模服務
Llama 4 的模型架構特別適合高效的長上下文推理,這得益於以下特性:
- 混合專家模型 (MoE):Scout 使用 16 個專家(啟用引數 17B),Maverick 使用 128 個專家(啟用引數 17B)。每個 token 只啟用一個專家,從而保持效率。
- 交錯式 RoPE (iRoPE):Llama 4 以 1:3 的比例將全域性注意力(不含 RoPE)與分塊區域性注意力(含 RoPE)交錯使用。區域性注意力層處理非重疊塊中的 token,隨著上下文長度的增加,顯著降低了注意力的二次方複雜度。
vLLM 最近釋出了 V1 引擎,在單節點上實現了顯著的效能提升,並支援原生的 torch.compile。我們的 第二季度路線圖 專注於增強 vLLM 的多節點擴充套件能力,目標是實現解耦的叢集規模服務。我們正在積極新增對高效專家並行、多節點資料並行和叢集範圍預填充解耦的支援。
致謝
我們衷心感謝 Meta 團隊在模型架構實現、廣泛的精度評估和效能基準測試方面做出的貢獻:Lucia (Lu) Fang, Ye (Charlotte) Qi, Lu Fang, Yang Chen, Zijing Liu, Yong Hoon Shin, Zhewen Li, Jon Swenson, Kai Wu, Xiaodong Wang, Shiyan Deng, Wenchen Wang, Lai Wei, Matthias Reso, Chris Thi, Keyun Tong, Jinho Hwang, Driss Guessous, Aston Zhang。
我們也感謝 AMD 團隊為在 MI300X 上啟用這些模型提供的支援:Hongxia Yang 和 Weijun Jiang。
vLLM 團隊的效能基準測試執行在 Nebius 和 NVIDIA 無私提供的硬體上。