MiniMax-M1 混合架構與 vLLM 結合:長上下文、快速推理
本文探討了 MiniMax-M1 的混合架構如何在 vLLM 中得到高效支援。我們討論了該模型的獨特特性、高效推理面臨的挑戰以及 vLLM 中實現的技術解決方案。
引言
人工智慧的快速發展催生了越來越強大的大型語言模型(LLM)。MiniMax-M1 是一款流行的開源大規模混合專家(MoE)推理模型,自發布以來備受關注。其創新的混合架構預示著 LLM 的未來,在長上下文推理和複雜任務處理方面取得了突破。同時,高效能 LLM 推理和服務庫 vLLM 為 MiniMax-M1 提供了強大的支援,使得高效部署成為可能。
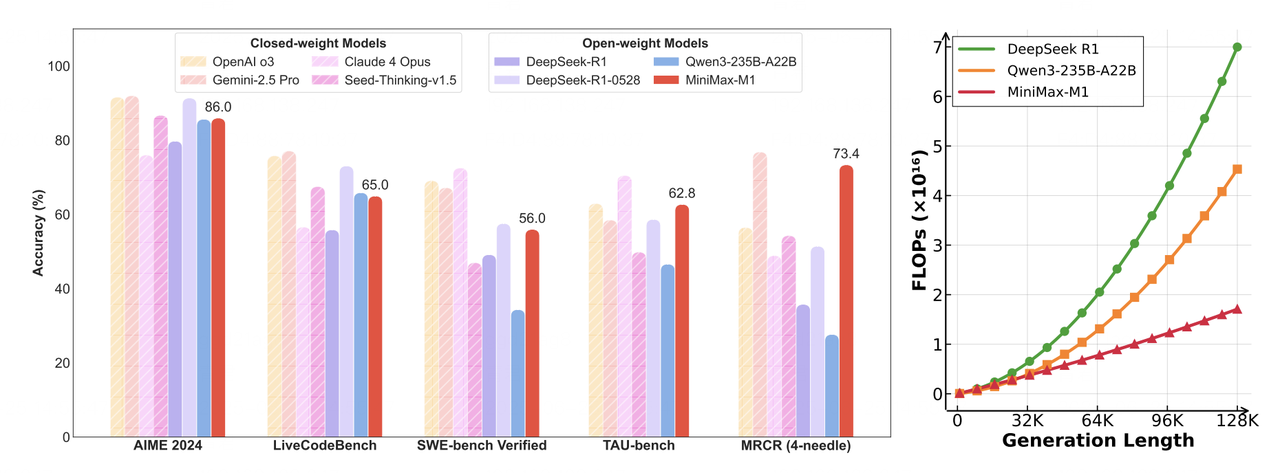
- 左圖:領先的商業和開源模型在數學、程式碼、軟體工程、工具使用和長上下文理解等任務上的基準比較。MiniMax-M1 在開源模型中處於領先地位。
- 右圖:理論推理 FLOPs 隨 token 長度的擴充套件情況。與 DeepSeek R1 相比,MiniMax-M1 在生成 10 萬個 token 的序列時僅使用 25% 的 FLOPs。
使用 vLLM 部署 MiniMax-M1
我們建議使用 vLLM 部署 MiniMax-M1 以獲得最佳效能。我們的測試表明其具有以下主要優勢:
- 出色的吞吐量
- 高效智慧的記憶體管理
- 對批次請求的強大支援
- 深度最佳化的後端效能
模型下載
您可以從 Hugging Face 下載模型
# Install the Hugging Face Hub CLI
pip install -U huggingface-hub
# Download the MiniMax-M1-40k model
huggingface-cli download MiniMaxAI/MiniMax-M1-40k
# For the 80k version, uncomment the following line:
# huggingface-cli download MiniMaxAI/MiniMax-M1-80k
部署
以下是使用 vLLM 和 Docker 部署 MiniMax-M1 的快速指南
# Set environment variables
IMAGE=vllm/vllm-openai:latest
MODEL_DIR=<model storage path>
NAME=MiniMaxImage
# Docker run configuration
DOCKER_RUN_CMD="--network=host --privileged --ipc=host --ulimit memlock=-1 --rm --gpus all --ulimit stack=67108864"
# Start the container
sudo docker run -it \
-v $MODEL_DIR:$MODEL_DIR \
--name $NAME \
$DOCKER_RUN_CMD \
$IMAGE /bin/bash
# Launch MiniMax-M1 Service
export SAFETENSORS_FAST_GPU=1
export VLLM_USE_V1=0
vllm serve \
--model <model storage path> \
--tensor-parallel-size 8 \
--trust-remote-code \
--quantization experts_int8 \
--max_model_len 4096 \
--dtype bfloat16
MiniMax-M1 混合架構亮點
混合專家(MoE)
MiniMax-M1 採用了混合專家(MoE)架構,總引數量達 4560 億。在推理過程中,動態路由演算法根據輸入 token 的語義特徵啟用稀疏的專家子集(約 459 億引數,佔總引數的 10%)。這種稀疏啟用由門控網路管理,該網路計算專家選擇機率。
這種方法顯著提高了計算效率:在分類任務中,它將計算成本降低了高達 90%,同時保持了與密集模型相當的準確性。
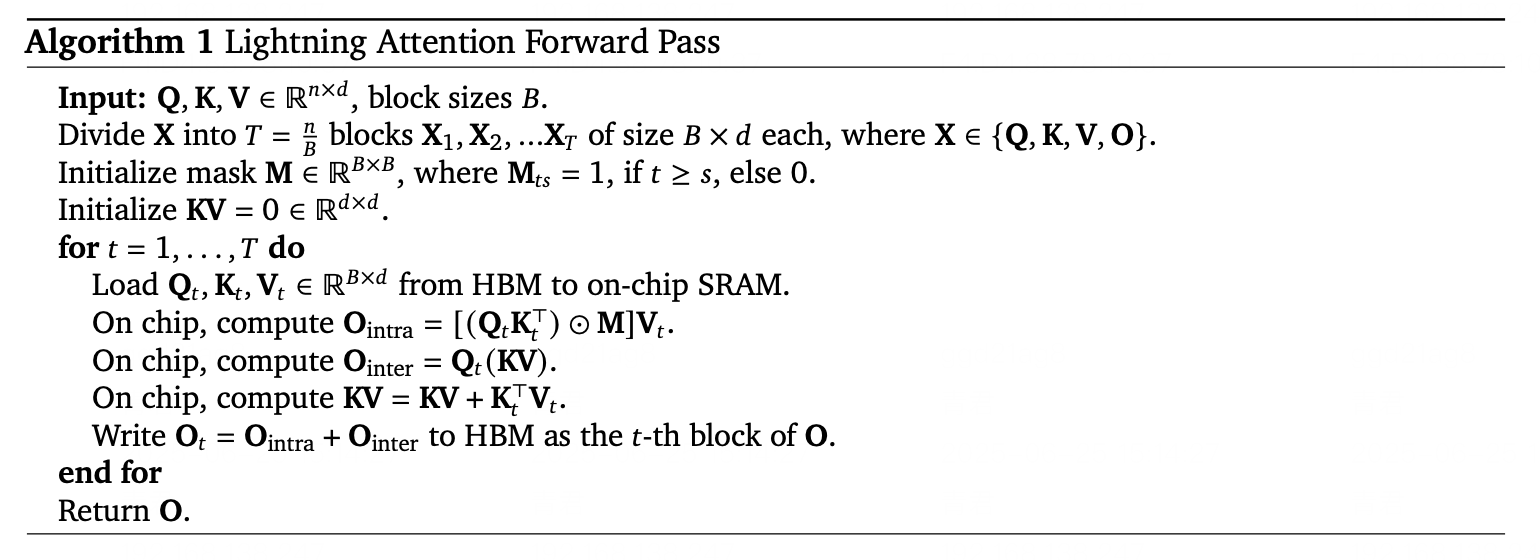
Lightning Attention
Lightning Attention 透過引入線性化近似技術,解決了傳統注意力機制的二次複雜度瓶頸。它在動態記憶體分塊和梯度近似的輔助下,將 softmax 注意力轉換為矩陣乘法的線性組合。
在程式碼補全基準測試中,Lightning Attention 將 10 萬個 token 序列的記憶體使用量減少了 83%,推理延遲減少了 67%。
高效計算 & 啟用策略
得益於其混合架構,MiniMax-M1 實現了高效計算和可擴充套件推理。Lightning Attention 機制顯著提高了執行時效能,而稀疏專家啟用策略則避免了不必要的計算。這使得即使在有限的硬體資源下也能實現強大的效能。
要了解有關 MiniMax-M1 的更多資訊,請參閱本文。
使用 vLLM 進行高效推理
高階記憶體管理
vLLM 引入了 PagedAttention,這是一種更有效地管理注意力鍵值快取的技術。vLLM 不會將 kv-cache 連續儲存,而是將其劃分為多個記憶體頁,大大減少了碎片和過度分配。這使得 vLLM 能夠將記憶體浪費降至 4% 以下,而傳統方法則高達 60%-80%。
這種高效的記憶體處理對於 MiniMax-M1 等支援超長上下文長度的模型至關重要,可確保平穩穩定的推理,而不會遇到記憶體瓶頸。
深度核心級最佳化
vLLM 融合了廣泛的 CUDA 核心最佳化,包括與 FlashAttention、FlashInfer 的整合,以及對 GPTQ、AWQ、INT4、INT8 和 FP8 等量化格式的支援。
這些增強功能進一步提升了 MiniMax-M1 推理的底層計算效率。量化在最小精度損失的情況下減少了記憶體和計算開銷,而 FlashAttention 則加速了注意力計算本身——從而在實際應用中實現了顯著更快的推理。
vLLM 中的 Lightning Attention
作為一種尖端注意力機制,Lightning Attention 透過 Triton 在 vLLM 中實現,充分利用了 Triton 的靈活性和高效能計算特性。基於 Triton 的執行框架完全支援 Lightning Attention 的核心計算邏輯,從而實現了在 vLLM 生態系統中的無縫整合和部署。
未來工作
展望未來,vLLM 社群正在積極探索對混合架構支援的進一步最佳化。值得注意的是,混合分配器的開發有望實現更高效的記憶體管理,以適應 MiniMax-M1 等模型的獨特需求。
此外,計劃全面支援 vLLM v1,混合模型架構預計將遷移到 v1 框架中。這些進步有望進一步提升效能,併為未來的發展提供更堅實的基礎。
結論
MiniMax-M1 的混合架構為下一代大型語言模型鋪平了道路,在長上下文推理和複雜任務推理方面提供了強大的能力。vLLM 透過高度最佳化的記憶體處理、強大的批次請求管理和深度調優的後端效能對其進行了補充。
MiniMax-M1 和 vLLM 共同為高效可擴充套件的 AI 應用奠定了堅實基礎。隨著生態系統的發展,我們預計這種協同作用將為廣泛用例提供更智慧、響應更快、功能更強大的解決方案,包括程式碼生成、文件分析和對話式 AI。
致謝
我們衷心感謝 vLLM 社群的寶貴支援與合作。特別感謝 Tyler Michael Smith、Simon Mo、Cyrus Leung、Roger Wang、Zifeng Mo 和 Kaichao You 所做的重大貢獻。我們也感謝 MiniMax 工程團隊的努力,特別是 Gangying Qing、Jun Qing 和 Jiaren Cai,他們的奉獻使這項工作成為可能。